
谷歌TurboQuant技术吓崩存储股?华尔街:不要慌,是假利空!
上周刚交出“史诗级”亮眼财报的存储芯片巨头美光(MU),本周却未能延续涨势。周三,Google Research扔下的一枚“炸弹”——压缩技术TurboQuant,声称可将运行大型语言模型所需的内存量压缩至少六分之一,AI推理速度同步提升8倍,整体训练成本随之大幅下降。

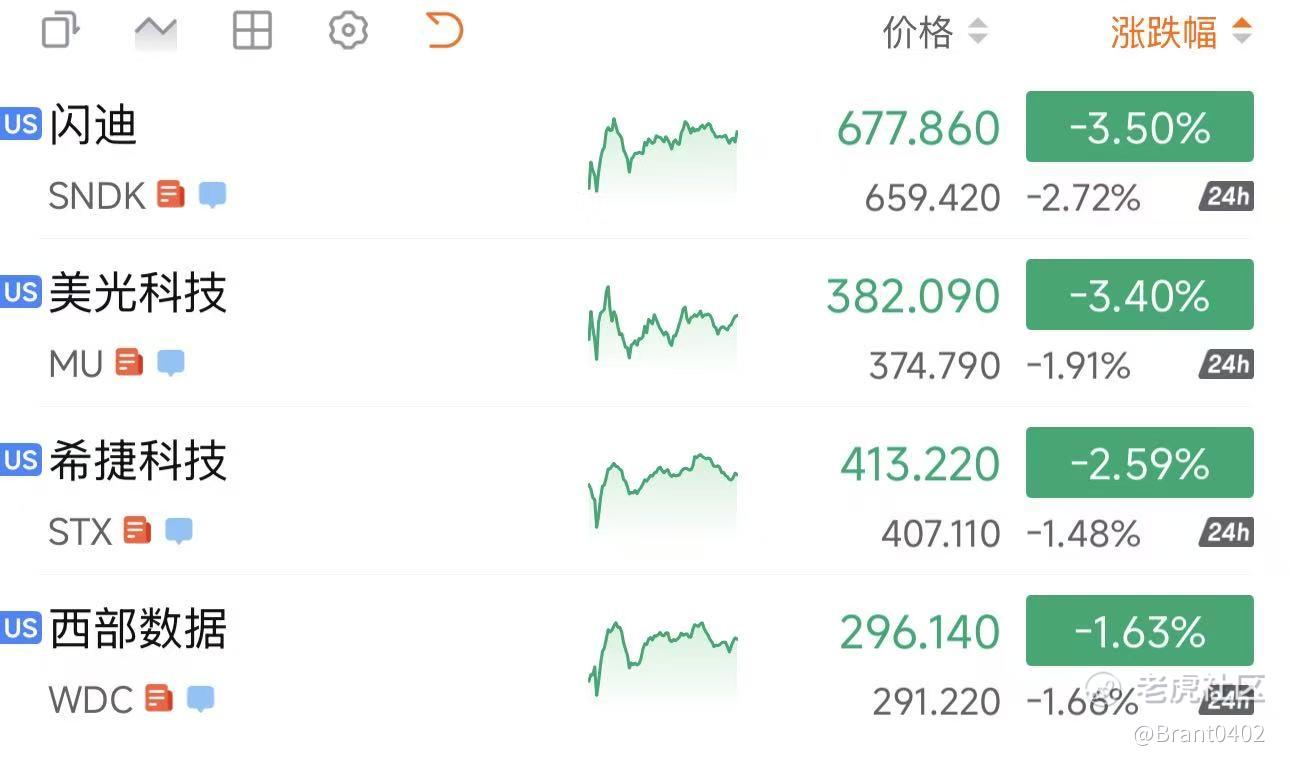
消息一出,全球内存与存储板块应声下挫。美光、闪迪率先领跌,韩国SK海力士、日本铠侠Kioxia次日跟跌,跌幅均超6%。一场由算法引发的存储股“雪崩”,正在席卷全球。
Part.01
导火索:TurboQuant横空出世
引发这场海啸的源头,是Alphabet旗下Google Research最近发布的一项名为TurboQuant的向量量化压缩技术。
在AI推理过程中,随着上下文变长,系统需要存储庞大的KV Cache(键值缓存),这已成为显存占用的最大来源,也是限制大语言模型处理长文本的“内存瓶颈”。
Google宣称,TurboQuant采用了创新的“两阶段”压缩流程:
l 极坐标量化(PolarQuant): 先通过随机旋转让数据分布均匀,以极低位宽(2-4 bits)捕捉向量特征。
l QJL纠错: 利用数学变换将残差投影到低维空间,并仅用1 bit存储正负号作为“数学纠错器”。
其最终效果堪称惊人:
6倍压缩:将LLM运行所需的显存量降低至 6倍。
8倍提速:在Nvidia H100上,推理效率最高提升8倍。
零精度损失:在“大海捞针”等长文本测试中保持了原模型精度。
数据无关:无需重新训练即可直接部署。
对于Google等超大规模云服务商而言,这意味着能以极低的成本运行更强的AI模型,极大地提升投资回报率。
Part.02
市场担忧:AI内存需求的“神话”动摇了吗?
TurboQuant的杀伤力,在于它直接针对AI基础设施的核心“耗材”——内存。过去两年,AI大模型的训练与推理对HBM及NAND的需求呈爆发式增长,支撑了美光、SK海力士、铠侠等内存股的史诗级行情。
一旦单模型的内存消耗量被压缩6倍,市场最直接的担忧是:云厂商能否用更少的内存、更低的成本完成同样的AI工作负载?若答案为“是”,则内存扩容的紧迫性将大幅下降,供需格局的再平衡时间线也将提前。
TurboQuant的出现,无疑打破了市场对于“AI对物理内存需求将无限制指数级增长”的信仰。投资者担心,这可能是导致高带宽内存(HBM)等尖端产品需求萎缩的“生存威胁”。受此情绪影响,美光、闪迪等个股纷纷走低。
Part.03
华尔街观点:假利空,继续买买买!
然而,华尔街主流分析师对上述空头逻辑提出了强烈反驳。他们搬出了一个19世纪的经济学理论——杰文斯悖论(Jevons Paradox):“效率越高,需求反而越旺。”
英国经济学家杰文斯在研究煤炭生产时发现:技术效率的提升往往催生更大规模的使用,而非减少消耗。
这一逻辑在AI领域并不陌生。去年DeepSeek以低成本模型掀起恐慌时,市场同样担忧先进算力需求将萎缩。但事实证明,低成本反而刺激了AI推理的普及化,整体算力消耗不降反升。

摩根大通在研报中补充道:投资者或许会借TurboQuant的消息进行短线获利了结,但短期内不会对内存需求构成威胁。
Ortus Advisors的Andrew Jackson则提出了另一个关键维度:当前内存市场仍处于极度供应紧张的状态。在这一背景下,TurboQuant对实际需求的冲击可能“微乎其微”,因为需求本就超过了现有产能所能满足的上限。
总结
TurboQuant究竟是会彻底改变AI硬件供应链的“降维打击”,还是仅仅通过降低门槛、进一步引爆AI应用从而利好硬件的“催化剂”?
虽然目前,投资者选择了先“落袋为安”,但分析师们依然坚信,在AI这场浩大的社会效率变革中,“杰文斯悖论”终将再次战胜短期的恐慌。
免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。
- FrankCollins·03-26肯定是催化剂,AI需求只会更猛!点赞举报