
未来持续成长的一个热点
大家晚上好,我是刀哥。
实际上,A股有不少涉及到人工智能方面的个股。而在ChatGPT作为最近最热门的话题的环境下,人工智能方面的个股都得到了很高的关注。
今天就谈谈ChatGPT。结论其实很简单:这可能是一个划时代的产品,一如当年的搜索引擎。这也是谷歌如此紧张的原因。
如果用简单总结这个产品,如下:这是一个基于前期巨大的“人工投喂”+“人工排序”之后,再自我进化整合出来的一个聊天式的智能AI解决方案,可以用于大量的行业。
ChatGPT到底是什么。ChatGPT全称Chat Generative Pre-trained。GPT的意思是生成式预训练转换器),是一种基于互联网可用数据训练的文本生成深度学习模型。
GPT是众多LLM中的一种模型。LLM全称Large Language Model(中文翻译,大型语言模型)。
ChatGPT作为一个对话模型,到底是如何运作的呢?ChatGPT也被称作GPT-3.5,与去年公布的InstructGPT是一对姊妹模型。
ChatGPT是InstructGPT的兄弟模型(sibling model),后者经过训练以遵循Prompt中的指令,提供详细的响应。InstructGPT是OpenAI在2022年3月在Training language models to follow instructions with human feedback文献中提出的工作,整体流程和以上的ChatGPT流程基本相同,除了在数据收集和基座模型(GPT3 vs GPT 3.5),以及第三步初始化PPO模型时略有不同。
两者在训练方式和模型结构上完全一致,所以可以简单通过InstructGPT来理解ChatGPT的训练细节及模型。
其训练步骤分为三步,分别是SFT、RM、PPO。
1. SFT全称为Supervised Fine-Tuning,本质是对数据进行优化。
为了让GPT 3.5初步具备理解指令的意图,首先会在数据集中随机抽取问题,由人类标注人员,给出高质量答案,然后用这些人工标注好的数据来微调 GPT-3.5模型(获得SFT模型, Supervised Fine-Tuning)。此时的SFT模型在遵循指令/对话方面已经优于 GPT-3,但不一定符合人类偏好。
你可以理解,第一步是人工训练。但这种方式,有个很大的缺点是不具备判断能力。比如,模型给出了A、B、C、D四个答案,用户还得判断,哪一个自己才是自己想要的。
2. 训练奖励模型(Reward Mode,RM) 这个阶段的主要是通过人工标注训练数据(约33K个数据),来训练回报模型。
在数据集中随机抽取问题,使用第一阶段生成的模型,对于每个问题,生成多个不同的回答。人类标注者对这些结果综合考虑给出排名顺序。这一过程类似于教练或老师辅导。接下来,使用这个排序结果数据来训练奖励模型。对多个排序结果,两两组合,形成多个训练数据对。RM模型接受一个输入,给出评价回答质量的分数。这样,对于一对训练数据,调节参数使得高质量回答的打分比低质量的打分要高。
3. PPO (Proximal Policy Optimization,近端策略优化)
PPO的核心思路在于将Policy Gradient中On-policy的训练过程转化为Off-policy,即将在线学习转化为离线学习,这个转化过程被称之为Importance Sampling。这一阶段利用第二阶段训练好的奖励模型,靠奖励打分来更新预训练模型参数。在数据集中随机抽取问题,使用PPO模型生成回答,并用上一阶段训练好的RM模型给出质量分数。把回报分数依次传递,由此产生策略梯度,通过强化学习的方式以更新PPO模型参数。如果我们不断重复第二和第三阶段,通过迭代,会训练出更高质量的ChatGPT模型。
你可以理解:第一步是人工投喂,第二部是人工排序,第三步是整合进化。
在现阶段,只要输入问题,ChatGPT 就能给予回答,这其实给搜索带来巨大的影响。未来是否会替代搜索是不确定性的。ChatGPT目前已经全面接入微软,bing卷土重来,这对谷歌的冲击是巨大的。(比如现在在外贸这个领域,很多外贸企业需要做谷歌SEO,需要做谷歌搜索。但未来,可能都需要变化营销方式,ChatGPT是大家必须要接入的公司了)
当然,目前我们感受到的ChatGPT的“智力”是向相当强大的,包括我们看到很多特别耳目一新的回答,已经不俗的编程能力。但是,ChatGPT也有一些局限性。还在不断的进步。
1)ChatGPT在其未经大量语料训练的领域缺乏“人类常识”和引申能力,甚至会一本正经的“胡说八道”。ChatGPT在很多领域可以“创造答案”,但当用户寻求正确答案时,ChatGPT也有可能给出有误导的回答。
2)ChatGPT无法处理复杂冗长或者特别专业的语言结构。对于来自金融、自然科学或医学等非常专业领域的问题,如果没有进行足够的语料“投喂”,ChatGPT可能无法生成适当的回答。
3)ChatGPT需要非常大量的算力(芯片)来支持其训练和部署。抛开需要大量语料数据训练模型不说,在目前,ChatGPT在应用时仍然需要大算力的服务器支持,而这些服务器的成本是普通用户无法承受的,即便数十亿个参数的模型也需要惊人数量的计算资源才能运行和训练。如果面向真实搜索引擎的数以亿记的用户请求,如采取目前通行的免费策略,任何企业都难以承受这一成本。因此对于普通大众来说,还需等待更轻量型的模型或更高性价比的算力平台。
大模型是当前的其中一个AI研究方向,还有其它研究方向,也就是说,AI需要拼算力这件逻辑不是永恒的逻辑。很多人说英伟达是最受益的,是很有道理的。
(ChatGPT主要涉及AI自然语言处理相关技术,底层算力芯片以高性能GPU为主。而该类芯片中英伟达占据主要市场,英伟达的芯片为大模型训练做了很多优化。英伟达CEO黄仁勋在参加加利福尼亚大学Berkeley Haas 商学院的Dean’s Speaker 系列谈话时,也大赞了“ChatGPT的出现对人工智能领域的意义,类似手机领域iPhone的出现。”)
4)ChatGPT还没法在线的把新知识纳入其中。
当然,虽然是局限,但这也不影响ChatGPT的大火,毕竟未来可期。而且,这次也带动了全球AI建设的爆发。2023年全球进入了AI时代元年,未来AI全球建设规模一定是现在的成百上千倍。
从下游受益应用来看,包括但不限于内容创作、无代码编程、小说生成、对话类搜索引擎、语音陪伴、语音工作助手、对话虚拟人、人工智能客服、机器翻译、芯片设计等都会受益。而从上游增加需求来看,包括算力芯片、数据标注、自然语言处理(NLP)等。
另一个讨论较多的方向,是ChatGPT对于搜索引擎的代替性:ChatGPT目前可以作为搜索引擎的有效补充,但至于是否能代替搜索引擎还有2个因素阻碍:成本+答案的丰富性。
但不可否认,这是一个划时代的产品。随着AI的持续发展,不久就能替代很多人的工作。
正如有博主所说的一样:“最近一些关于ChatGPT和 Bing Chat的文章,就和19 世纪认为照相机是种妖术会摄魂一个意思。”
当然,会有很多个股受益。国内也有不少公司参与到这个环节中来。给大家推荐华夏的人工智能三剑客:
华夏人工智能AI ETF 515070
华夏云计算50ETF 516630
华夏大数据50ETF 516000
人工智能AI ETF(515070)是一个专门投资人工智能领域的行业基金,重仓的个股为:
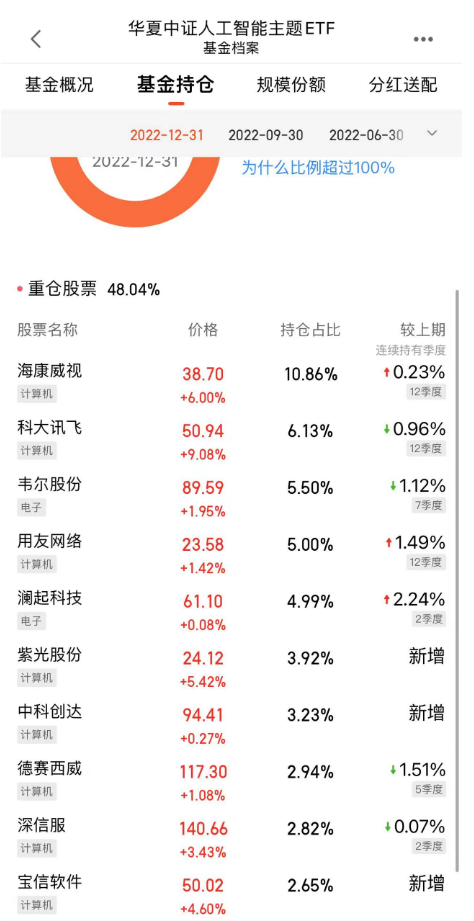
该ETF主要是跟踪中证人工智能主题指数。中证人工智能主题指数从沪深市场中选取50只业务涉及为人工智能提供基础资源、技术以及应用支持的上市公司证券作为指数样本,以反映人工智能主题上市公司证券的整体表现。
这里面其实囊括了大数据、人工智能资源、云计算、机器学习、芯片等各方面的公司。比如海康威视是智能安防领域;科大讯飞是语音智能方面深耕的公司;而韦尔股份则是提供传感器解决方案、模拟解决方案和触屏与显示解决方案,助力客户在手机、安防、汽车电子、可穿戴设备,IoT,通信、计算机、消费电子、工业、医疗等领域解决技术挑战。用友网络则是云计算方面的公司。等等等等。
ChatGPT如果成为划时代的产品,相关的AI基建异常重要,而人工智能AI ETF基本上囊括了AI基建的个股(A股),因此对ChatGPT有兴趣的同学可以关注人工智能AI ETF这个行业ETF。
我个人也购买了该ETF的观察仓位。因为考虑到最近炒作的比较火,所以没有多买,但参与是一定要参与的。未来随着热点冷却,可以考虑再定投买多一些,毕竟这是未来很多年一个最大的趋势点。
另外两个ETF: 华夏云计算50ETF 516630、华夏大数据50ETF 516000,也同样建议大家关注起来,都是人工智能领域方面的行业基金。
各位晚安。各位的“点赞”、“在看”是对刀哥最大的支持。
免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。
