
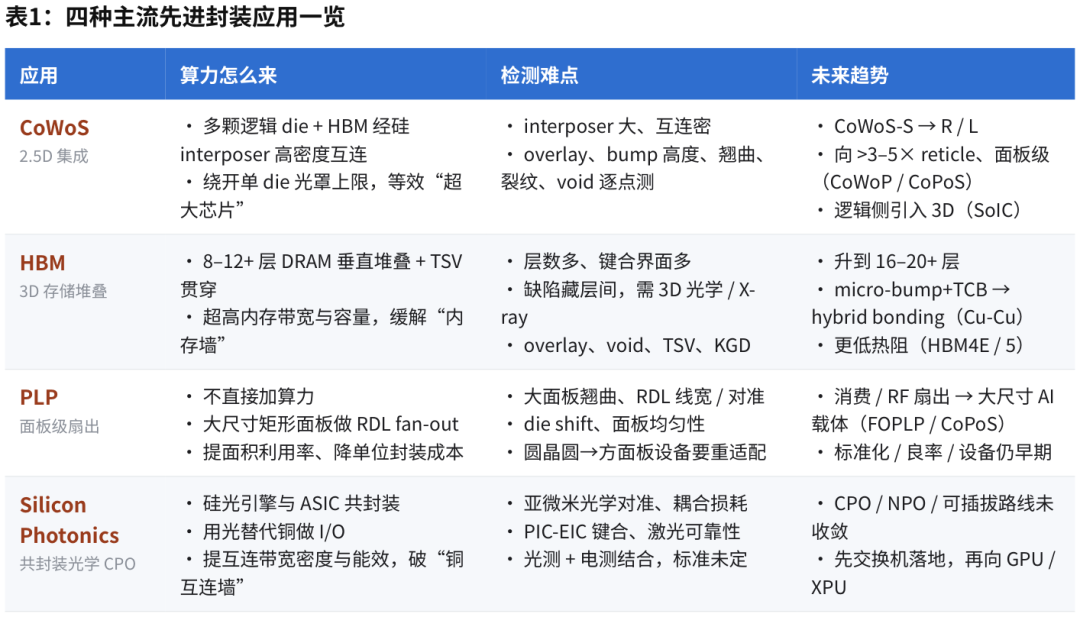
AI 芯片越复杂,越离不开先进封装设备

BEDROCK | 路线会变,但检测、量测、测试不会消失
先进封装这条线,最值得看的不是某一个封装名词,而是 AI 芯片复杂度上升后,良率控制重新变成设备收入主线。CoWoS、HBM、玻璃基板、PLP、CPO 的技术路线会继续变化,但检测、量测、测试这些把复杂度关进良率闭环的环节不会消失。
|
Key takeaway • 算力增长正从“晶体管微缩”转向“chiplet 堆叠”,价值从前道重新流回中道与后道。 • 先进封装的第一性原理:用“更短、更密、更省电的连接”,去换“晶体管微缩”换不来的性能。 • 短期看 CoWoS 与 HBM 的确定性,长期看玻璃基板、PLP 与硅光(CPO)的空间。 • 路线会变(TCB→hybrid bonding、ABF→玻璃、CoWoS→面板级),但良率控制不会消失。 • 封装越复杂,检测 / 测试需求越是非线性(≈n²)上升——这正是“复杂度被稳定转化为收入”的机制。 • 跟踪排序:检测 / 量测(KLA、Onto、Camtek)> 测试 / 探针(Advantest、Chroma、FormFactor)> 减薄 / 切割(DISCO)> 键合(BESI 等,高弹性但验证后移的一层)。 |
一、微缩走不动:算力靠 chiplet 堆叠,落到四种主流封装
过去几十年,算力的增量主要来自晶体管微缩——节点每往前走一代,同样面积里塞进更多晶体管。但这条路正在走不动:先进节点的 PPA(性能/功耗/面积)改善越来越小,成本却快速上升,而单颗 die 继续做大又撞到光罩尺寸(reticle limit)和良率的天花板——die 越大,一个致命缺陷报废的面积就越大,良率掉得越快。结果是,靠"把一颗芯片做得更大更密"来拿算力的边际收益急剧下降。
于是行业转向 chiplet:把原本一颗大 SoC 拆成多个小 die(逻辑、I/O、缓存),再配上 HBM 等存储,通过先进封装重新"拼"和"叠"成一个系统。
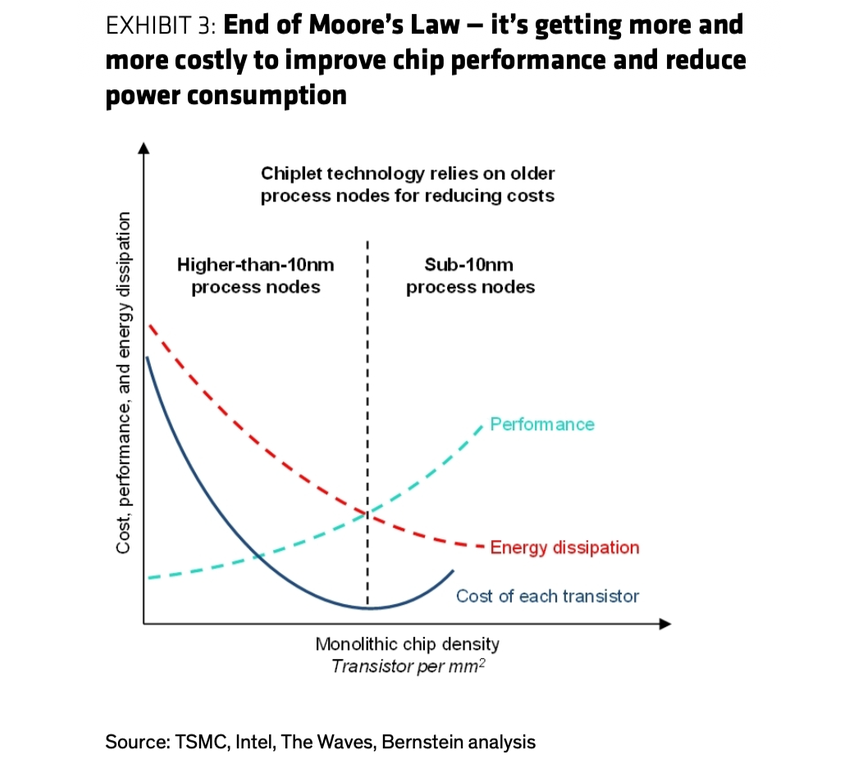
图1:摩尔定律放缓,算力转向 chiplet 堆叠
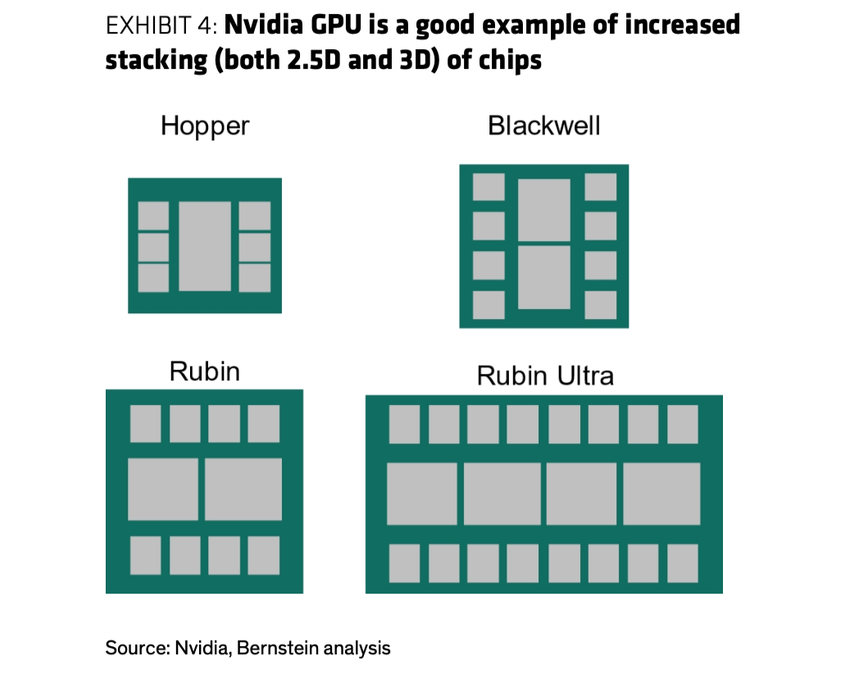
左:改善芯片性能 / 功耗的成本越来越高,单 die 微缩的边际收益递减;右:NVIDIA 从 Hopper 到 Rubin Ultra 不断增加 2.5D / 3D 堆叠。资料来源:TSMC、Intel、Nvidia、Bernstein analysis。
左图:PPA 改善变贵,单 die 微缩边际收益下降
右图:NVIDIA GPU 走向更多 2.5D / 3D 堆叠
把多颗芯片连同内存拼叠成一个系统,具体落到四种主流的先进封装上:CoWoS(2.5D 集成)、HBM(3D 存储堆叠)、Panel-Level Packaging(面板级扇出)和 Silicon Photonics(硅光 / 共封装光学)。它们分别解决算力交付里的不同瓶颈,但用到的先进封装环节高度重叠。下面把四者的结构剖面分开看,橙色标出的就是各自用到先进封装、也就是设备公司切入的环节。
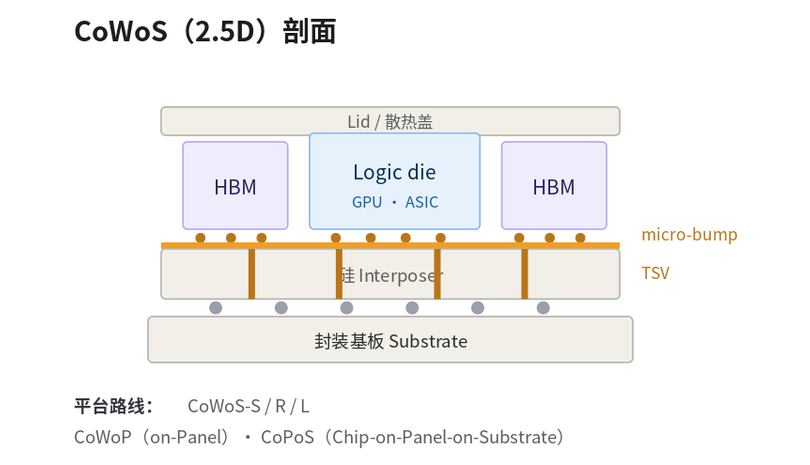
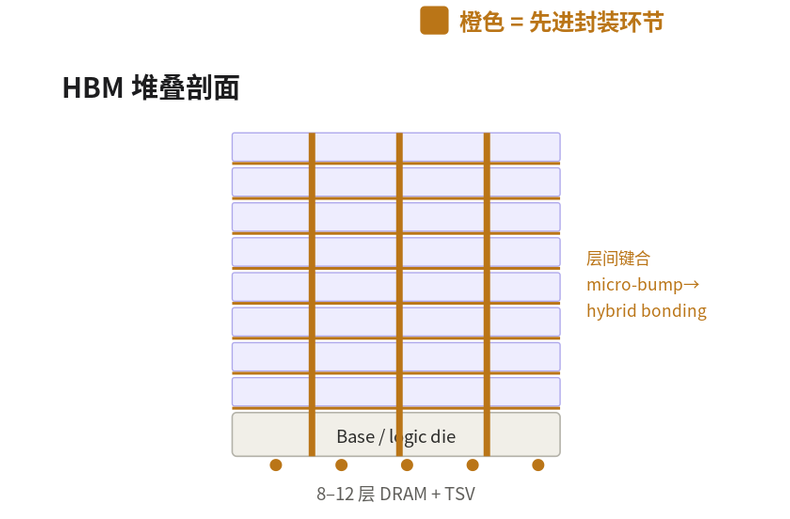
图2:四种主流先进封装应用的结构与先进封装切入点
橙色 = 先进封装环节(micro-bump、TSV、键合、RDL fan-out、光学共封装等)。
CoWoS(2.5D):logic die + HBM + interposer
HBM:DRAM 多层堆叠,TSV / 键合是核心
PLP:面板级 fan-out,核心是 RDL 与 molding
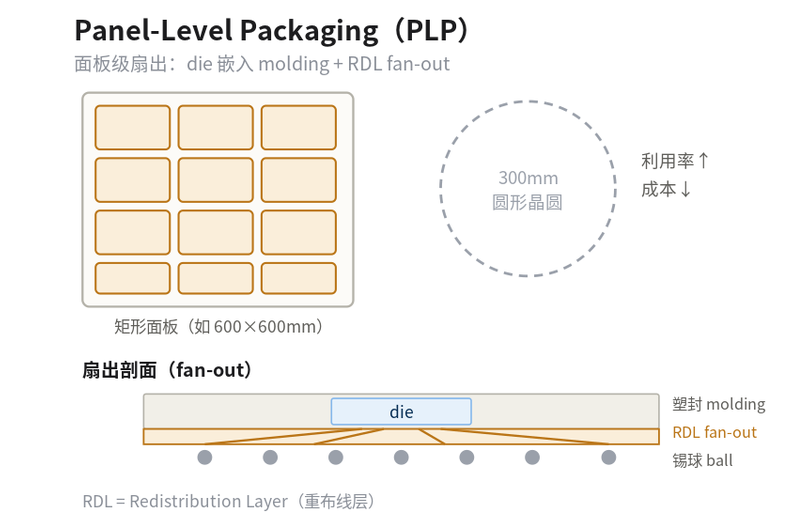
硅光 / CPO:把光引擎与 ASIC 拉近

这四件事,其实是同一件事:先进封装的第一性原理
把这四个应用放在一起看,它们其实在做同一件事。今天 AI 算力的瓶颈,已经不是“算得快不快”,而是“数据喂不喂得上”——计算单元的速度,远远跑在了内存和芯片间连线的前面,好比一个人一秒能看完一本书,却卡在“书递得太慢”。前面说的把多颗芯片连同内存拼在一起、叠在一起,本质都是为了把数据更快、更省电地送到计算单元面前。
而“更快、更省电地送数据”,物理上只有三个办法:让连线更短(贴得更近)、让连线更密(并行通道更多)、让每传一个比特更省电。上表里那些看似五花八门的趋势——HBM 多堆几层、凸点换成无凸点的铜对铜直连、有机基板换成玻璃、最后干脆用光替代铜——本质都是在这三件事上往前推一步。
一句话:先进封装是用“更短、更密、更省电的连接”,去换“晶体管微缩”换不来的性能。判断任何新封装方案,就只剩一个问题:它有没有在“更近、更密、更省电”上真的进了一步。这也埋下后文的伏笔——把芯片叠得越密、连得越近,界面就越多、越容易出缺陷、良率越低;所以越先进的封装,越离不开检测和测试。
玻璃基板:CoWoS 变大之后的材料解法
图3:TSMC CoWoS-S / CoWoS-L / CoWoS-R 平台示意
资料来源:TSMC。
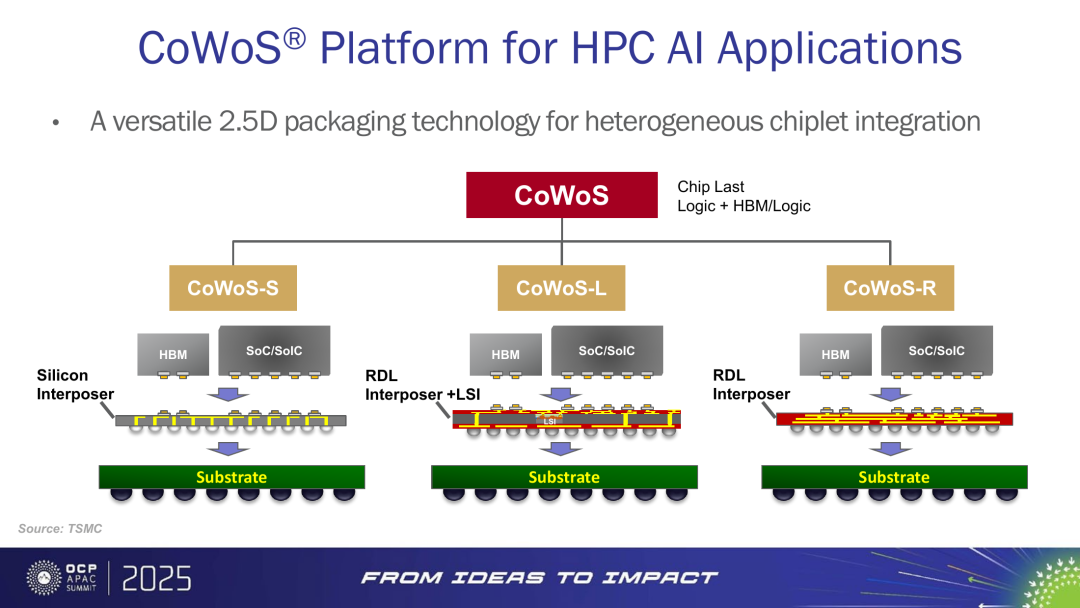
玻璃基板是这轮先进封装里最容易被误解的一条线。它不是另一个孤立的新材料概念,而是 CoWoS 继续变大之后,硅中介层和有机载板共同遇到瓶颈时的材料解法。
现在的主流方案仍然是硅 interposer 加 ABF 有机基板。但当 AI 封装从 3 reticle 走向 5 reticle、9 reticle,问题开始变得尖锐:硅中介层受 300mm 圆片尺寸和面积利用率限制,有机基板在大尺寸封装下更容易遇到翘曲、CTE 不匹配、线宽线距和信号损耗问题。玻璃的价值就在于同时改善几件事:尺寸可以做得更大,平整度更好,CTE 可以通过配方调节,介电损耗更低,也更适合走向面板级加工。
从路线看,玻璃基板至少有两种方向:一种是 glass interposer,替代或补充硅中介层;另一种是 glass core substrate,替代部分高阶有机载板。前者更贴近高端 AI / HPC 的短期痛点,因为大芯片加 HBM 的搭配已经在挤压硅中介层的面积和翘曲边界;后者空间更大,但要和成熟、便宜、供应链完善的有机载板竞争,节奏会更慢。
对设备公司的含义很直接:玻璃路线不会减少检测和量测,反而会增加新的检查对象。TGV 成孔、填孔、金属化、RDL 布线、玻璃翘曲、透明材料缺陷检测,这些都是新插入点。路线从硅 interposer 变成玻璃 interposer,变化的是材料和工艺,不变的是客户仍然必须看到每一个孔、每一层铜、每一次键合界面有没有问题。
硅光 / CPO:用“更短、更密、更省电”解释长期价值
图4:从铜线到 OE on interposer,CPO 把互连做得更短、更省电、更低延迟
资料来源:TSMC(OCP APAC Summit 2025)。
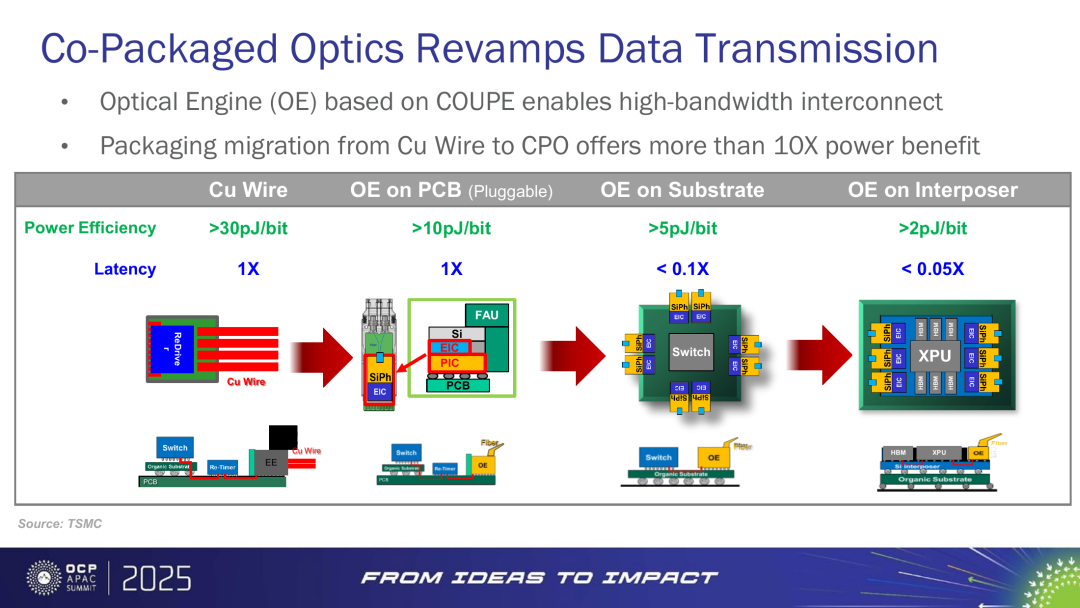
硅光 / CPO 的长期价值,也可以用“更短、更密、更省电”这条第一性原理来解释。传统可插拔光模块仍然要经过较长的铜走线:信号从 XPU 或 switch ASIC 出来后,还要在 PCB 上走一段距离,再进入光模块完成电光转换。CPO 的方向是把 optical engine 放到 substrate 甚至 interposer 附近,把铜线距离从十厘米级压到毫米级甚至更短。
直接结果是功耗和延迟下降。TSMC 给过一个直观口径:从 copper wire 到 OE on PCB、OE on substrate,再到 OE on interposer,power efficiency 可以从大于 30pJ/bit 逐步降到小于 2pJ/bit,延迟也随距离缩短明显下降。这解释了为什么 CPO 是 AI 集群未来的长期方向。
但 CPO 现在不宜放到短期主线。它仍然面临标准未定、激光可靠性、光学耦合、PIC / EIC 键合、光电混合测试和供应链分工等问题。对设备投资而言,CPO 更像下一轮封装复杂度的来源,而不是 2026–2028 年最确定的收入兑现主线。
这四类里,真正能在 2026–2028 年兑现为设备需求的,主要是 CoWoS(2.5D 逻辑)和 HBM。下图(Morgan Stanley 口径)很直观:2.5D logic 与 HBM 的封装需求逐年放量,而 Other AP(PLP、硅光等)的贡献始终有限。
图5:2.5D 逻辑与 HBM 持续放量,PLP / 硅光等贡献仍有限
先进封装需求(MS 口径,指数);e = Morgan Stanley 预测。
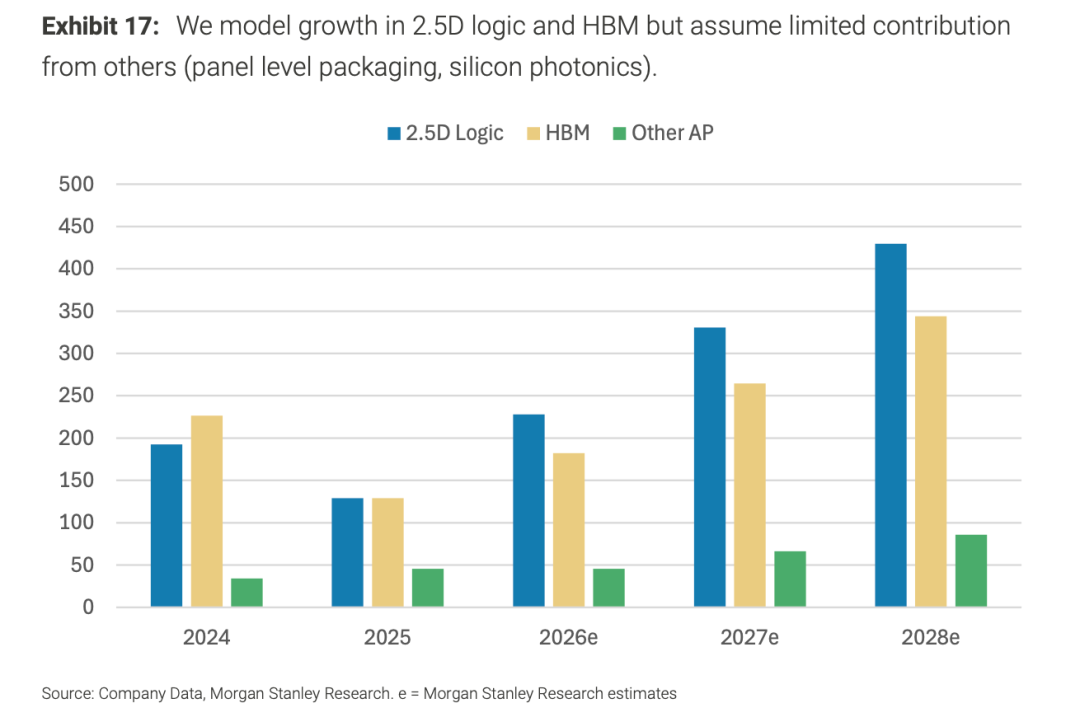
所以可以把节奏分成两段看。短期(2026–2028)看 CoWoS 和 HBM:它们已经在放量,检测、键合、测试需求明确、能直接兑现,是当前确定性最高的主线。长期看 PLP 和硅光:PLP 用大尺寸面板解决面积利用率与成本,硅光用光互连解决带宽密度与能效,它们是 CoWoS / HBM 之后空间更大的下一波——只是当前还卡在良率、标准化与成本上,兑现窗口更靠后。PLP 受制于大面板翘曲、缺乏统一标准、量测 / 检测和键合设备都要重新适配;硅光受制于亚微米光学对准与可靠性、光电混合测试标准未定、以及激光与耦合带来的成本和良率。一句话:CoWoS + HBM 是确定性主线,PLP 和硅光是长期期权。
二、为什么是现在:三个变量同时到了临界点
为什么是现在?因为先进封装已经从“可选优化项”变成 AI 芯片交付的硬约束。
第一,AI 加速器本身越做越大。早期 CoWoS 还能停留在 1.x 到 2 reticle 的封装尺寸,但进入 HBM3E、HBM4 之后,封装不断向 3.3 reticle、5.5 reticle 甚至 9.5 reticle 扩张。封装面积变大不是为了好看,而是为了同时放下更大的 logic die、更多 HBM stack、更宽的 I/O 通道。换句话说,AI 芯片性能的增长正在越来越依赖封装面积、互连密度和 HBM 数量,而不是单颗 die 自己继续变大。
第二,CoWoS 产能已经成为 GPU 出货的实物瓶颈。TSMC 产能口径显示,CoWoS 当前产能约 120 万片 / 年,2026 年底提升到约 130 万片 / 年,其中 NVIDIA 占比较高;业内一个更直白的说法是:AMD GPU 销量本质上是在卖台积电 CoWoS 产能。也就是说,先进封装不再只是封测厂的内部工艺问题,而是直接决定 NVIDIA、AMD 这类 AI 芯片公司能交付多少产品。
第三,HBM 把封装复杂度继续往上推。HBM 从 8 层、12 层继续走向 16 层以上,每多一层 DRAM,不只是多一次堆叠,还会增加 KGD 筛选、键合、TSV、burn-in、最终测试一整套质量控制动作。更高层数、更细 pitch、更高带宽,意味着同一片 wafer 上的检测、量测和测试内容量都会上升。
所以这轮先进封装设备需求,不是单一技术概念带来的主题行情,而是三个变量同时到临界点:AI die 变大,HBM 层数变高,CoWoS 产能变成出货瓶颈。只要这三件事继续成立,中道和后道设备的价值量就会持续抬升。
图6:CoWoS interposer 从 1.x reticle 扩展到 5.5 / 9.5 reticle,HBM 数量同步提升
资料来源:TSMC(OCP APAC Summit 2025)。
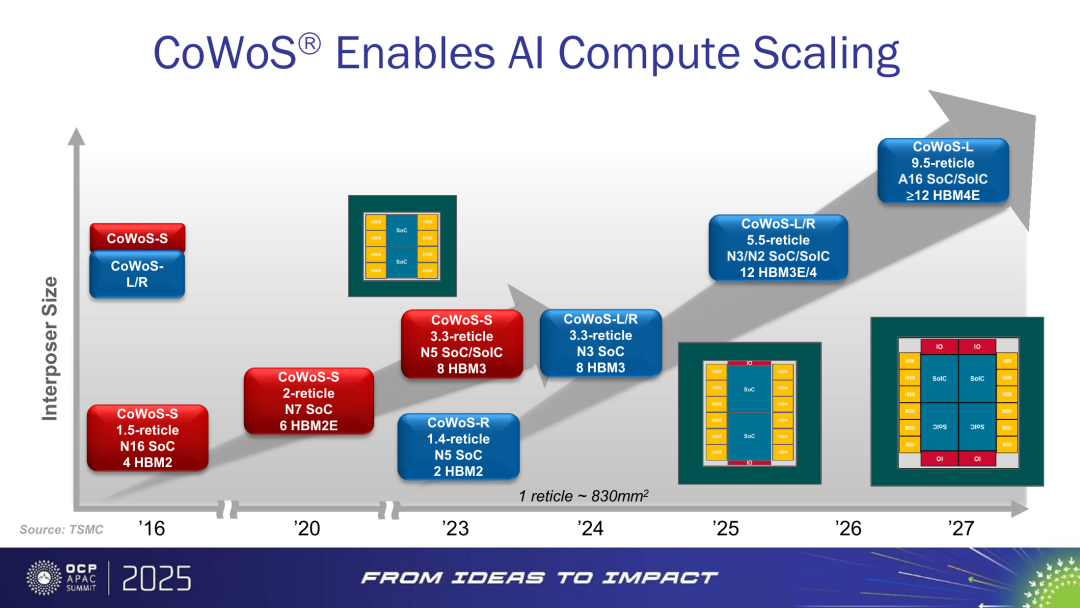
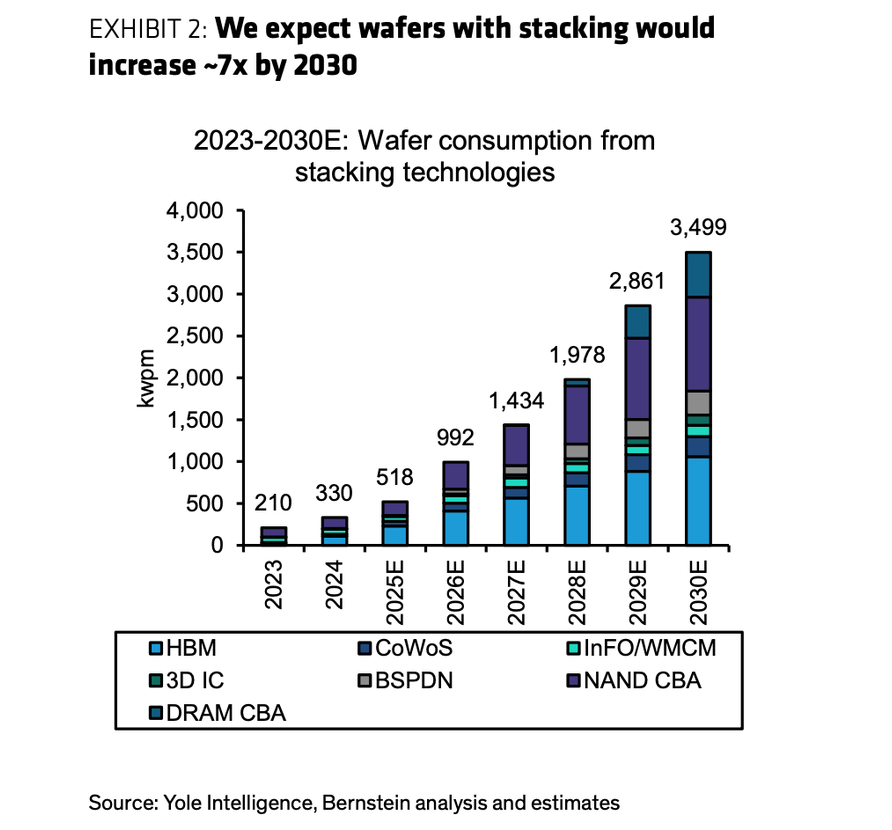
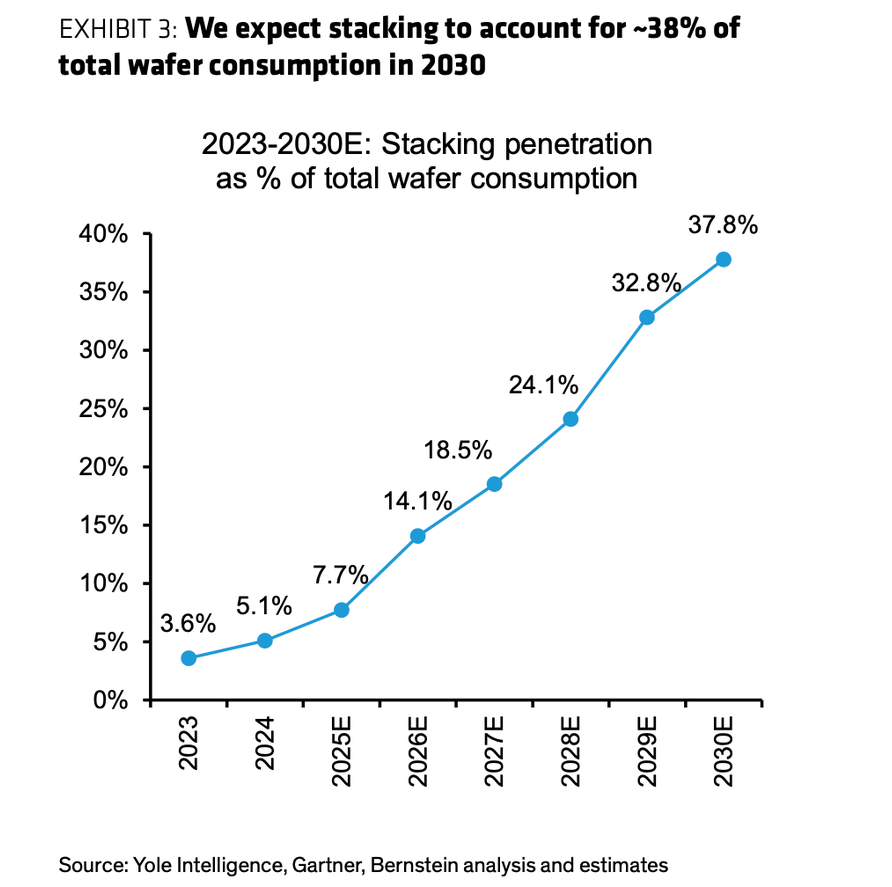
图7:堆叠技术拉动的晶圆消耗 ≈7×,渗透率升至约 38%(2030E)
资料来源:Yole Intelligence、Bernstein analysis and estimates。
左图:堆叠相关 wafer 消耗到 2030 年约 7×
右图:堆叠渗透率到 2030 年约 38%
三、把设备链按工序拆开
换句话说,过去靠制程在晶圆内部解决的集成问题,现在要靠封装在晶圆之上、用堆叠的方式解决。封装因此从"后段配套"升格为延续算力增长的主要手段,而把这些 chip 真正堆叠、互连在一起的工序,就集中在我们所说的中道。
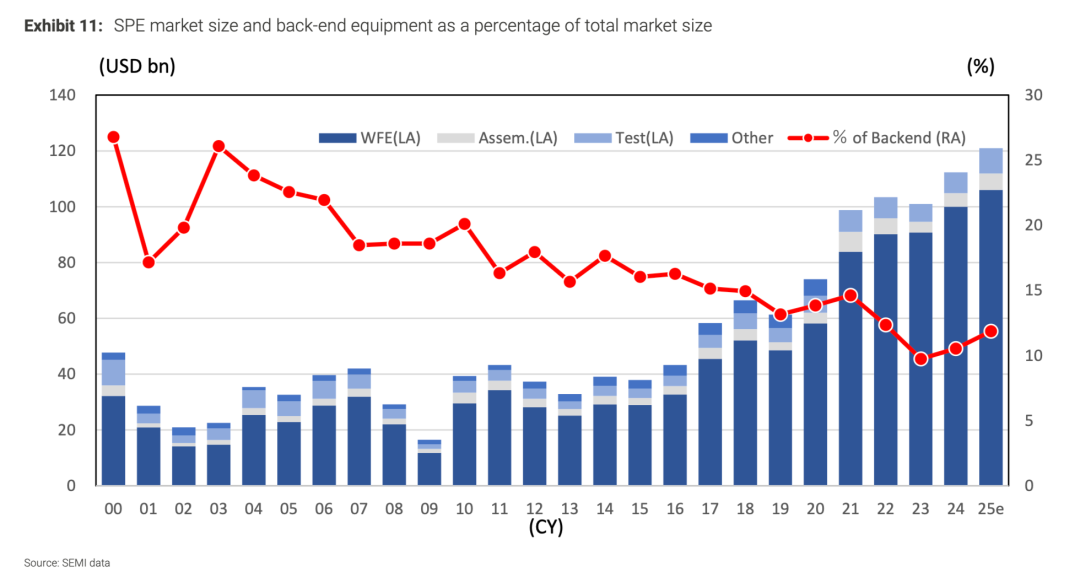
关键的变化在价值量。中道和后道在广义上都属于"后道"(相对前道晶圆制造),而这部分占整体半导体设备(SPE)的价值量,过去很长一段时间是下降的:据 SEMI 数据,后段(封装组装 + 测试)设备占整体设备市场的比例,从 2000 年前后的约 25–27% 一路降到 2019–2021 年的约 13–15%——价值量长期向前道 WFE 集中,后段被视为低附加值的配套环节。但这个趋势正在反转。随着 chiplet 复杂度逐级上升、堆叠层数和 die 数量增加,再叠加堆叠后偏低的良率所带来的反复检测、筛选与返工需求,广义后道的设备价值量重新抬头,占比在近一两年回升。换句话说,过去被前道稀释的环节,正因为"复杂度 + 良率"这两件事,重新变回投资主线。
图8:后道(封装 + 测试)设备占整体设备市场的比例,先降后升
红线为后道设备占比(右轴):从 2000 年前后约 27% 降到 2019–2021 约 13–15%,近年回升。资料来源:SEMI。
中道介于前道晶圆制造和后道成品封测之间,是晶圆级的 chiplet 基本组装:KGD 筛选、晶圆减薄、临时键合/解键合、die-to-wafer 或 wafer-to-wafer 键合(micro-bump TCB 或 hybrid bonding)、TSV reveal,把逻辑 die 与 HBM 堆叠/贴装到 interposer 上,形成 CoW(Chip-on-Wafer)。CoWoS、CPO 这类产品在"成品封装"之前,核心难度几乎都压在中道这段堆叠上。下图把整条交付链拆成前道、中道、后道,并标出各类设备公司的位置。
图9:AI 芯片交付链——前道 / 中道 / 后道与设备公司定位
微缩走不动后,算力靠 chiplet 堆叠获得;中道是 CoWoS / CPO 成品封装前的晶圆级基本组装环节。

| 中道+后道 = 广义后道相对前道晶圆制造,中道与后道合起来构成"广义后道"——也是下文按工序拆解的对象。 |
沿着这条链看,每一类公司在做的事并不相同。前道仍是晶圆与 interposer 的制造——光刻、刻蚀、薄膜、CMP,以及 TSV、RDL 和 bump 的形成。中道是堆叠的主战场:减薄/切割(DISCO、Accretech)把晶圆磨到几十微米以露出 TSV;键合/堆叠(BESI、ASMPT、Hanmi、EVG、SUSS)完成 die 的贴装与互连;而一旦进入立体堆叠,缺陷会被藏到层与层之间,平面检测看不到,必须引入 3D 光学量测与检测(Camtek、ONTO、KLA)去测 overlay、bump 高度、翘曲和 bond void。后道则负责把 CoW 切割、贴到封装基板、做成型散热,并通过测试/探针(Advantest、Teradyne、Chroma、FormFactor)在进入昂贵系统前筛掉坏 die。
把先进封装设备沿工序铺开,大致是六段:RDL / TSV / 成孔、封装光刻 / 对准、减薄 / 切割、键合 / 堆叠 / 成型、检测 / 量测、测试 / 探针。下图把主要设备公司按工序归位,并用金色标出我们认为最值得重点跟踪的名字。
图10:先进封装设备产业链图谱
金色 = 重点跟踪(核心);灰色 = 其他 / watchlist。

这张图想说明两件事。第一,价值不是均匀分布的:越往右(检测 / 量测、测试 / 探针)越路线无关、客户黏性越高;越靠键合 / 堆叠,向上弹性越大,但路线风险也越高。第二,同一个名字在不同工序的“含金量”差别很大——KLA 是平台型确定性,Camtek 是纯 AP 弹性,二者不能当成同一类票。
更关键的是,这条链上的技术路线一直在迁移。下表把六个环节的“现在”和“未来”并排列出:

几乎每个环节都在换路线——micro-bump 走向无凸点的 hybrid bonding、ABF 基板走向玻璃、CoWoS-S 走向 R / L 和面板级。但请注意:无论路线怎么换,客户都仍然要确认 overlay、bump 高度、翘曲、void、KGD……路线会变、bonding 工具的份额会重新洗牌,但“看见缺陷、量化偏差、闭环修正”这件事不会被省略。这就引出全篇的核心判断——路线会变,良率控制不会消失。
四、为什么良率控制不会消失:检测复杂度指数级上升
上一节说路线会变、良率控制不会消失,这一节用一个简单的模型说明:随着封装复杂度上升,检测和测试的需求不是线性、而是几何级数地增加。
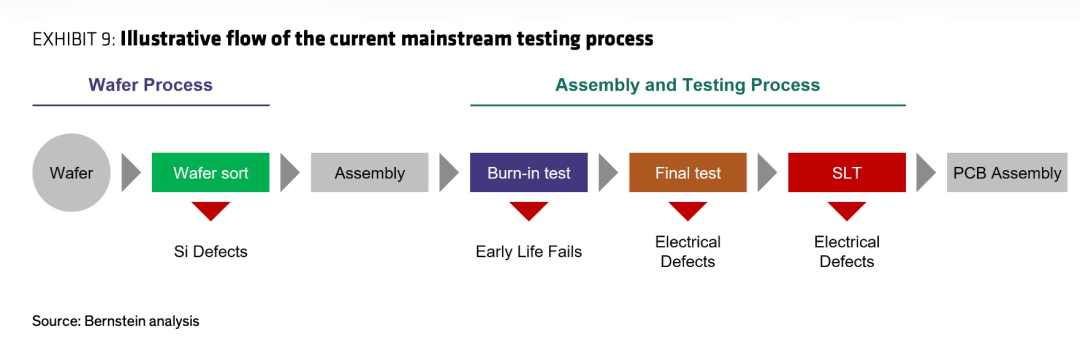
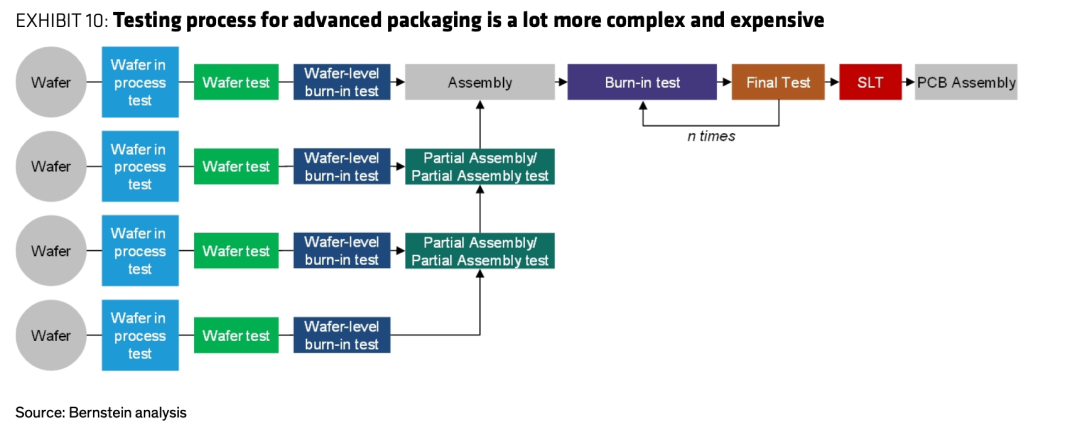
传统芯片的测试基本是一条直线:晶圆 → wafer sort → 封装 → burn-in → final test → SLT → 上板,一颗 die 走一遍,插入点固定且有限。到了先进封装,这条直线裂变成一棵树:多颗 die 各自先做 wafer-in-process test、wafer test、wafer-level burn-in,组装中途还要做 partial-assembly test,最终测试再重复 n 次。
图11:传统测试流程 vs 先进封装测试流程
上为传统线性测试流(Exhibit 9),下为先进封装测试流(Exhibit 10)。资料来源:Bernstein analysis。
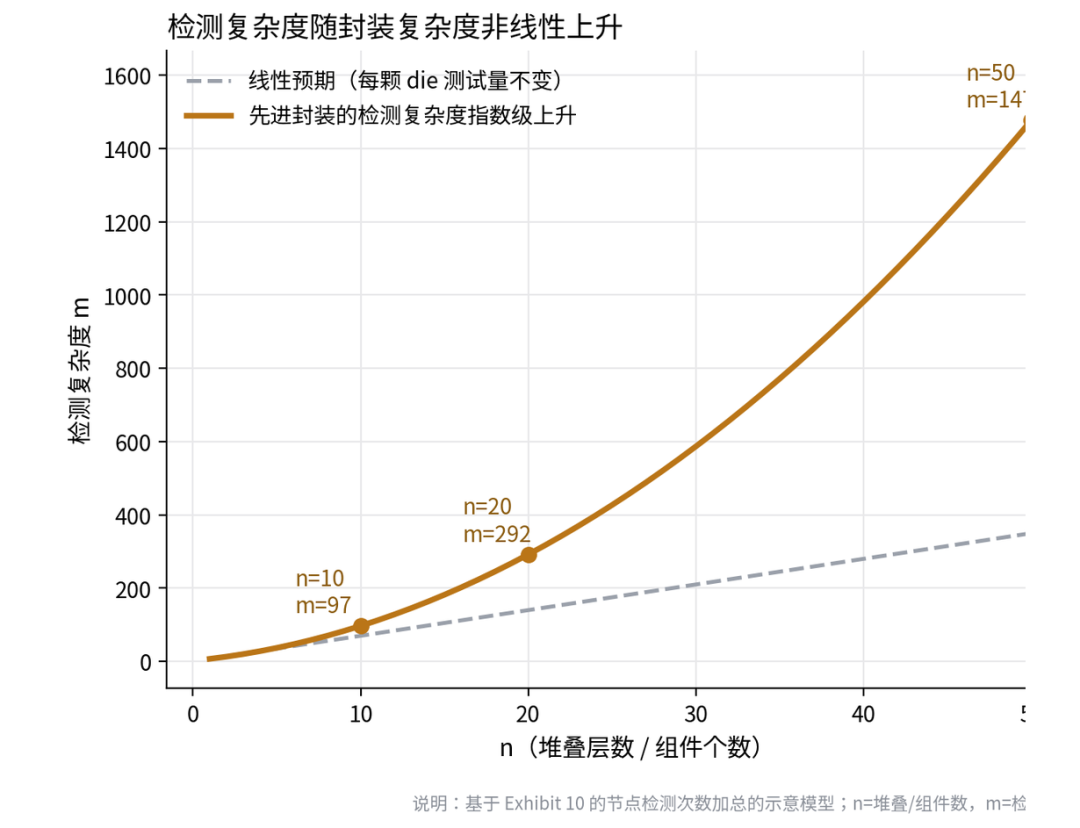
我们把这棵树按“节点检测次数加总”建成一个示意模型:设 n 为堆叠层数 / 组件个数,m 为检测复杂度。
图12:检测复杂度随封装复杂度非线性上升
m(n) ≈ n²/2;n=10 时 m≈97、n=20 时 ≈292、n=50 时 ≈1477(相对单芯片约 4–5 个插入点)。
左图:检测复杂度随 n 非线性上升
右图:增长主要来自组装中累计重测
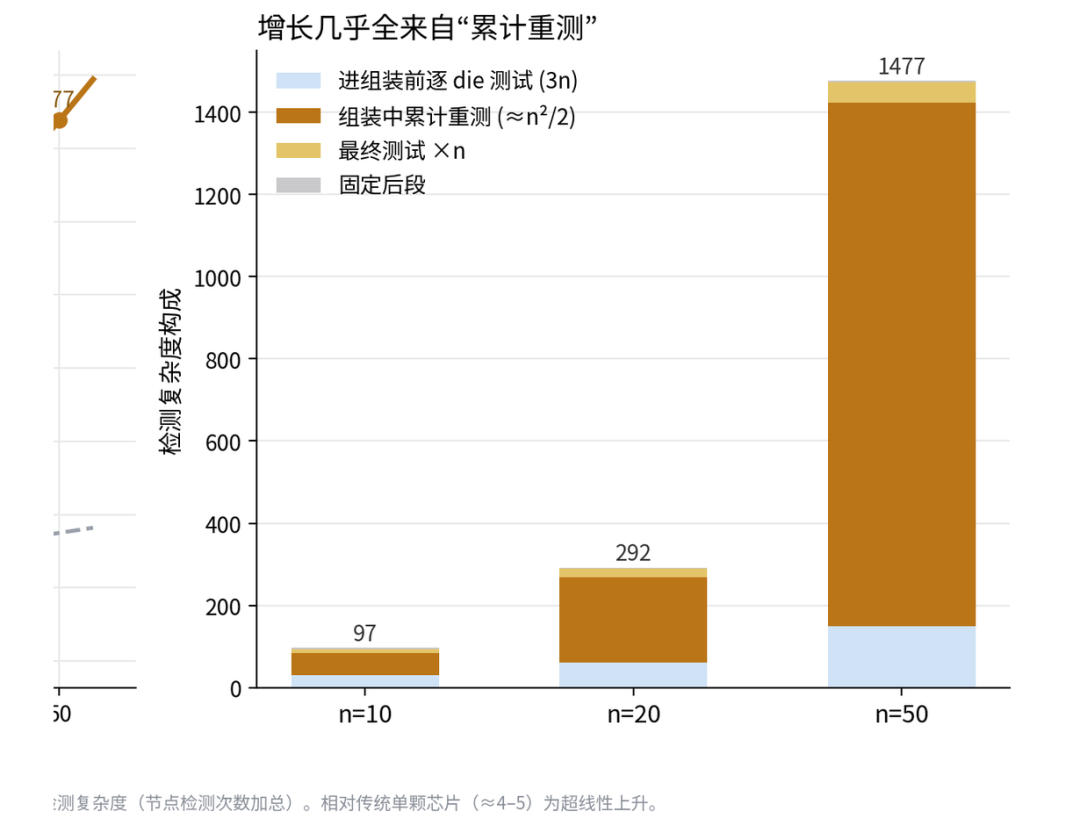
模型里真正的非线性来自一点:每往上堆一颗 die,不只是测这颗新 die,还要把已经组装好的整摞重新验证一遍——因为键合会损伤已有结构,且越到后面价值越高、越不敢漏。于是检测次数是累计的,m(n) ≈ n²/2:n=10 约为单芯片的 20 倍、n=20 约 60 倍、n=50 约 300 倍。右图显示,这些增长几乎全部来自“组装中累计重测”这一项。
这就是“复杂度被稳定转化为收入”的机制:每多一颗 die、多一层堆叠、多一道键合界面,就实打实多出一组检测 / 测试插入点;而且越贵的 die,抽检率和覆盖率还往上走。这也是为什么——无论封装走哪条路线——检测、量测、测试、探针是最难被替代的环节。
这个模型可以用三个产业案例来落地。
一是 HBM 探针卡。据产业调研,HBM 一张 wafer 所需测试针卡的价值约为传统 DRAM 的 3 到 5 倍。原因不是 HBM 的针数一定更多,而是它采用 stack 工艺,每层 DRAM 在堆叠前都要尽量筛成 KGD,堆叠后还要再做 burn-in 和最终测试。一旦坏 die 被封进多层 HBM 里,损失就不再是一颗 DRAM die,而是一整摞高价值组件。
二是 X-ray 和 3D 检测。Hybrid bonding、TSV、HBM4、SoIC 这类结构会把缺陷藏到层与层之间,传统平面光学检测很难看见。据行业判断,随着 2027 年后 HBM4 和 hybrid bonding 量产起量,先进封装 X-ray 检测增速会显著高于普通前道检测。本质不是某一家 X-ray 公司突然重要,而是封装从 2D 走向 3D 后,客户必须引入更多无损、立体、在线的检查手段。
三是 TGV 玻璃基板。玻璃通孔的难点不是单个孔能不能打出来,而是一整块基板上数以百万计的孔能不能保持孔径、腰身、上下口形貌和金属填充的一致性。只要一个关键孔失败,就可能导致整块基板报废。玻璃路线一旦从验证走向量产,AOI、3D 量测、缺陷分类和 process control 会成为良率爬坡的核心,而不是附属环节。
这三个案例指向同一个结论:先进封装把“看不见的风险”变多了。die 越贵、堆叠越高、界面越多,客户越不敢靠抽象良率假设往前走,必须用更多检测、量测、测试插入点把风险一层层关住。
五、一个简单的框架:确定性 vs 弹性
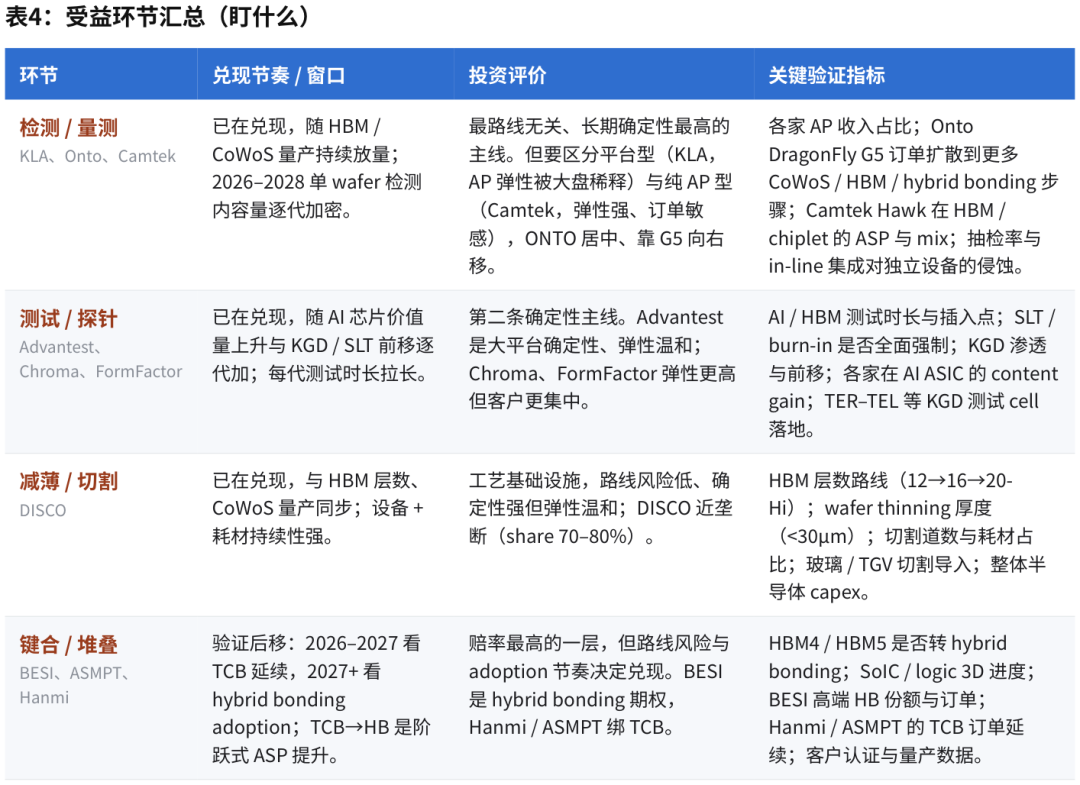
把前面的判断收成一个可操作的排序。沿着“路线无关程度”和“复杂度→收入的兑现确定性”,先进封装设备大致分四层:第一层,检测 / 量测(KLA、Onto、Camtek)——最路线无关,复杂度越高插入点越多,长期确定性最高;第二层,测试 / 探针(Advantest、Chroma、FormFactor)——受益于 AI 芯片价值量上升和 KGD / SLT 前移,每代芯片测试时长和插入点都在加;第三层,减薄 / 切割(DISCO)——工艺基础设施,路线风险低、确定性强,但弹性相对温和;第四层即高弹性但验证后移的一层,键合(BESI、ASMPT、Hanmi)——向上弹性大,但取决于 hybrid bonding 的 adoption 节奏和客户认证,验证后移。
|
确定性排序(路线无关程度 + 兑现确定性) 检测 / 量测 > 测试 / 探针 > 减薄 / 切割 > 键合 / 堆叠 |
|
弹性 / 弹性排序(向上空间) 键合 / 堆叠(hybrid bonding)> 检测 / 量测(纯 AP 高弹性)> 测试 / 探针 > 减薄 / 切割 |
两张表反着看,才是这条线的投资难点:确定性最高的未必弹性最大,弹性最大的兑现最慢。
但“确定性”只是一个维度,还要看第二个维度——AP 纯度 / 弹性。同样在第一层,KLA 的 AP 只占收入个位数到约 10%、弹性被大盘稀释;Camtek 的 AP 纯度 50%+、弹性强但订单更敏感。两者是不同性质的票,不能混为一谈。
图13:核心公司定位——确定性 vs 弹性
横轴 = 先进封装收入暴露度 / 纯度,纵轴 = 平台确定性 / 客户黏性;越靠右越纯(弹性大),越靠上越确定。左上是高确定性大平台,右下是高弹性但验证后移。
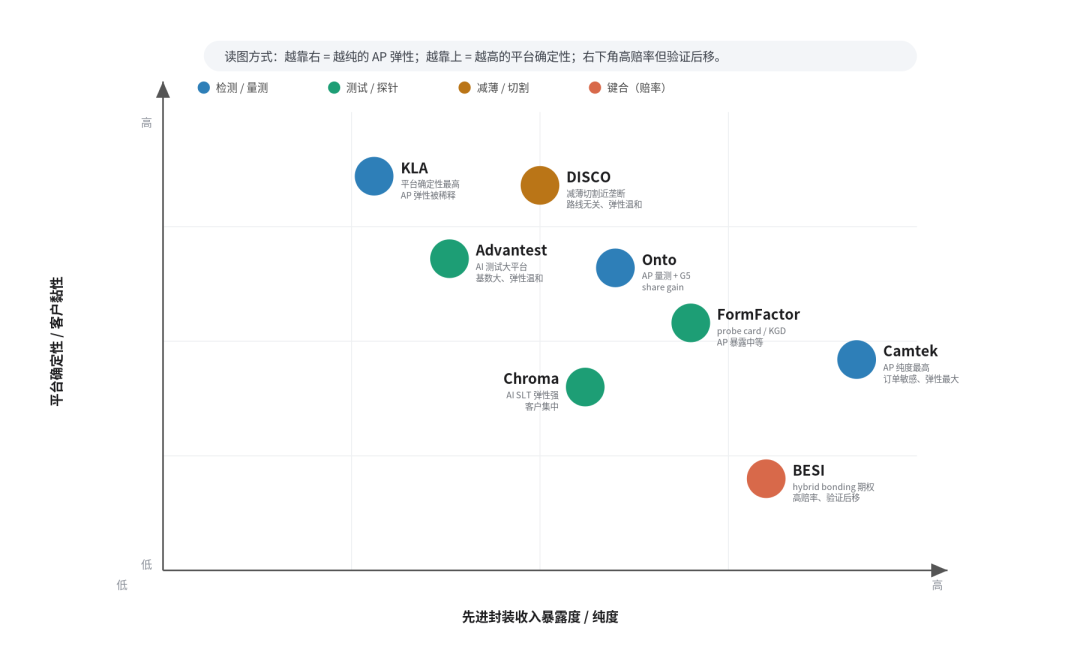
顺带把“高弹性但验证后移的一层”说透。键合层为什么是高弹性但验证后移的一层?因为它面对的是一次工艺范式切换:从 micro-bump 加 TCB,走向无凸点的 Cu-Cu hybrid bonding。TCB 成熟、适合当前 HBM3E、CoWoS 等主流量产;但当 pitch 继续缩小、I/O 密度继续提高、堆叠层数继续增加,焊料微凸点会越来越难支撑带宽、热阻和良率。Hybrid bonding 互连路径更短、pitch 可压到 10µm 以下、界面更薄,更适合 HBM4E / HBM5、logic 3D、SoIC 这类高密度堆叠。
封装行业的公开口径给了一个有用的量级感:先进封装投资中约 70%–80% 投向 2.5D / 3D 相关设备与工艺改造;当前 hybrid bonding 设备仍是几十台量级,但随 2.5D / 3D 月产能扩张,设备需求有机会从百台级继续向上。数字不必机械外推,但足以说明:hybrid bonding 一旦进入更多量产产品,设备收入弹性会是阶跃式的。这也正是它只能放“高弹性但验证后移的一层”、不能放“最高确定性层”的原因——逻辑成立,但客户认证、良率稳定性、产能利用率和产品导入节奏都后移;检测 / 量测和测试会随复杂度先兑现,键合工具要等客户真正把 HBM、logic 3D 或 SoIC 大规模切过去,弹性才集中释放。
为了说明“复杂度怎么算成收入”,我们用一个统一口径,给四个代表性标的做了 2030 年的情景测算:

测算示例,仅用于说明架构 / 复杂度变化如何放大可服务市场,不代表买卖建议、目标价或任何投资操作。
倍数谱拉得很开:DISCO 约 0.3–0.5x(温和、路线无关)< Advantest 0.85–1.3x(大基数平台)< Camtek 1.6–2.4x(纯度高弹性)< BESI 1.8x→3.5x+(高弹性、验证后移)。越靠右弹性越大,但确定性越低。
风险也要一句话讲清:这条主线不是无风险年金——真正的变量是 hybrid bonding 的节奏(影响键合层)、国产替代与出口管制(影响中国敞口)、以及成本压力下抽检率与 in-line 集成对独立检测设备的侵蚀。但这些改变的是弹性和份额,而不是“良率控制必须存在”这个前提。
排序与验证指标为方向性判断;具体兑现节奏取决于客户导入与认证进度。
六、拉远一层:封装背后更大的变量
如果只看设备公司,这里讲的是检测、测试、键合、减薄、探针。但把镜头拉远一层,先进封装背后真正发生的,是 AI 产业链的瓶颈从“单颗芯片制造”转向“系统交付”。
过去半导体的主线很清楚:谁能把晶体管做得更小,谁就能拿到性能、功耗和成本优势,价值主要集中在前道——光刻、刻蚀、薄膜、量测和先进制程产能。但 AI 时代的芯片不再只是一个 die,而是 logic die、HBM、interposer、substrate、电源、散热、光互连和系统测试共同组成的一个算力模块。单颗 die 再强,如果 HBM 不够、CoWoS 排不上、散热压不住、测试过不了,最终都无法变成可交付的算力。
这意味着价值开始从单一前道 WFE,向中道和后道重新扩散。不是前道不重要了,而是前道之外的每一个环节都开始决定最终性能:CoWoS 决定 GPU 能不能出货,HBM 决定数据能不能喂到计算单元,玻璃基板决定大尺寸封装能不能继续放大,CPO 决定未来互连能耗能不能下降,电源和散热决定整柜系统能不能稳定运行。AI 交付不再是一条线,而是一张网。
这也解释了为什么中国供应链会特别关注封装侧。先进制程受出口管制影响更大,但中道和后道里仍有很多国产替代窗口:玻璃基板、TGV 加工、封装光刻胶、湿电子材料、探针、AOI、部分量测和测试设备。这些环节未必一开始就能进入最高端 NVIDIA 链条,但只要国内 AI 芯片、HBM、CPO 和大尺寸封装继续推进,就会给本土设备和材料公司提供从低规格、小批量、验证线向量产线爬坡的机会。
所以先进封装不是摩尔定律的尾声,而是算力增长从晶体管层面转向系统层面的开始。设备机会不在押中某一个封装名词,而在押每一条路线都绕不开的良率闭环:看见缺陷、量化偏差、筛掉坏 die、修正工艺窗口。路线会变,但这套闭环不会消失。
回到开头那条第一性原理:先进封装的本质,是用“更短、更密、更省电的连接”,去换“晶体管微缩”换不来的性能。这条原理一句话决定了两件事——技术往哪走(更近、更密、更省电的互连),以及钱往哪流(连得越密、叠得越高,良率控制的需求越刚性)。所以投资上,短期跟 CoWoS 和 HBM 的确定性,长期看玻璃、PLP 和 CPO 的空间;设备上先抓最路线无关的检测、量测、测试,再用里程碑去验证键合的弹性。说到底,能穿越所有封装路线变化的,不是某一种封装,而是“看见缺陷、量化偏差、把坏 die 关在门外”这件事本身——更短、更密、更省电地把芯片连起来,就必然要更多地把它们看清楚。
本文由BEDROCK成员Oliver所撰写,为研究框架讨论,不构成投资建议。

欢迎关注网站:https://www.bedrock-invest.com/
BEDROCK播客已经开通,视频号、小宇宙、喜马拉雅、Youtube已上线,不定期分享对投资、产业、公司的理解和感悟,欢迎大家关注。
BEDROCK播客E28-《从AI时代投研范式转变聊起,26年上半年运作回顾》
BEDROCK播客E27-和Trader韭联动,从DCI聊起,谈AI对产业的重塑
BEDROCK播客E26-和湾区一线AI工程师聊Coding, 企业AI和Physical AI
BEDROCK播客E25-创始人谭聪 对话 哥大校友圣狮投资研习院,聊聊AI和全球化投资
BEDROCK播客E23- 聊聊Agent时代,当“思考”开始规模化
BEDROCK播客E22- AI投资下半场:分歧、重估与结构性机会
BEDROCK播客E20-展望2026,AI投资脉络:中美摩擦、泡沫分歧、细分机会?
BEDROCK播客E19- 聊聊AI在投资的应用
BEDROCK播客 E18- 聊聊巴西和投资
BEDROCK播客 E17- 聊聊中亚
BEDROCK播客 E16- 从AI云聊到大模型
BEDROCK播客 E14-我们的全球投资之道
BEDROCK播客 E13-聊聊我们如何做投资
往期文章:
电源结构开始决定算力速度
AI 的扩散缺口!
DCI不再是配角:AI Capex里的10x机会
当AI的快世界,撞上现实的慢世界
算力、记忆与 Alpha
又到了关键时刻!?
AI架构深度研究:存储与连接的时代?
AI Agent时代与市场影响
THE 2028 GLOBAL INTELLIGENCE CRISIS
The Era of Vibe Investing?
2026: Agent元年- 从“⼯具”到“劳动⼒”的范式转移
拉美投资(3)- 电商巨头Mercado Libre
拉美投资(2)- 最大的数字银行Nubank
拉美投资(1)-宏观初探

免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。
