
苹果哭了. HBM之后,推理开始吞噬NAND
当单卡HBM装不下百万token的KV Cache,企业SSD第一次成为GPU内存层的结构件
2026.06.19 · 技术前沿
[ STORAGE ]训练堆HBM,推理向下分层。NAND第一次拿到一个不依赖手机换机的AI锚——但成色押在每GPU配置TB数与缓存命中经济上。
HBM承载训练,推理向下分层。当单卡HBM装不下百万token的KV Cache,企业SSD第一次成为GPU内存层的结构件。
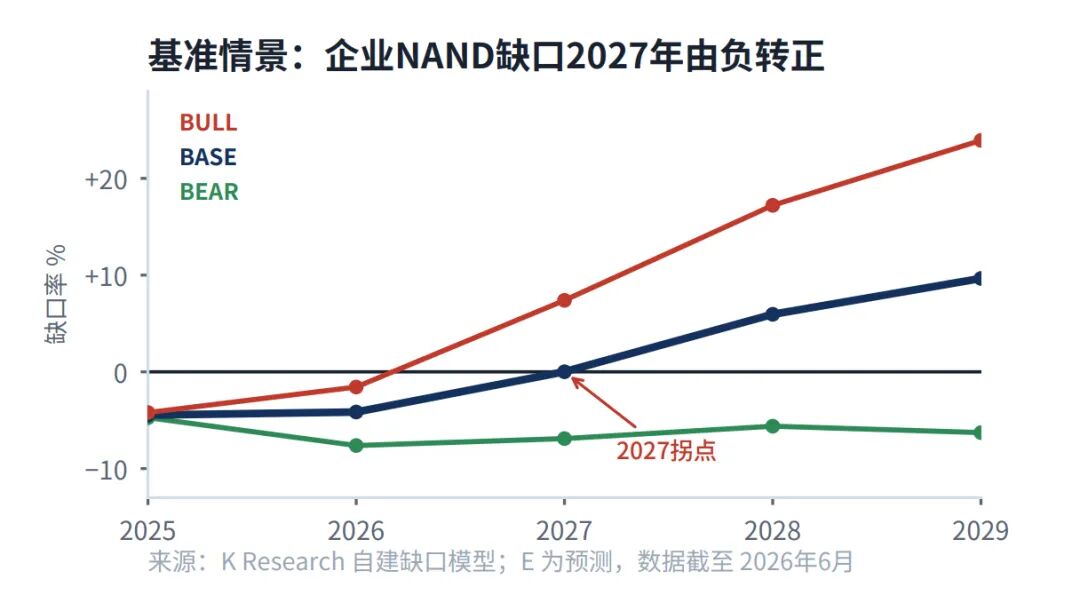
账本变了。70B级模型每百万token约生成 293GB KV Cache,是模型权重的两倍多,单卡Rubin HBM塞不下——分层成了工程刚需。
把约70%冷KV下沉SSD,每百万token内存账单从约2,930美元降到约590美元,省约八成;HBM越涨,省得越多。
训练期
−70%热层
冷KV
推理期
HBM越涨省得越多。NVIDIA在CES'26发布 CMX,用BlueField-4把以太网闪存做成池级KV缓存层,官方称吞吐与能效各 5倍。
市场早已为KV复用定价:Anthropic缓存读取只收输入价 10%(省90%)。DeepSeek把盘上缓存首token时延从13秒压到0.5秒 —— Anthropic / DeepSeek 文档 2026.05。
钱在跟进:Micron上季数据中心NAND营收环比翻倍,点名"vector database与KV cache offload";Kioxia经营利润率 74%、上市以来首次分红 —— Micron FQ2'26 / Kioxia Investor Day 2026.06.02。
反方不弱:DeepSeek V4把KV体积压到GQA的约 2%,更大DRAM也在抢。但压缩降单token体积,却放大可服务并发与上下文——杰文斯悖论,总bit方向不改。完整版已上传。
但这是条件性重定价。
卡位在控制器固件与GPU直连协议,而非裸NAND;裸晶圆最先被 2028–29 新产能稀释。低端消费NAND未必同步受益,反被挤出涨价。
NAND估值锚,正从手机出货切换为"每GPU配置TB数 × 每token存储流量"。
一切都是因为推理的崛起训练,一次性推理次次性。
免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。
