
AI降价、SpaceX入指、QDII额度:近期纳指100到底怎么看?
1 引言
自 ChatGPT 3.5 问世以来,AI 一直是美股市场最重要的主线之一,尤其是纳指100投资者,几乎每天都能看到各种互相矛盾的说法。
-
有人说 AI 需求还在爆发;
-
有人说 AI 支出已经降温;
-
有人说 token 太贵,客户用不起;
-
有人说 token 降价,厂商收不回投资;
-
有人说 GPU 太贵、折旧太快,云厂商要被拖垮;
-
有人说 GPU 租赁价格又涨了,算力依然供不应求;
-
有人说美国大模型继续领先,纳指100还能涨;
-
有人说中国大模型价格太低,美国 AI 要被卷死;
现在又多了 SpaceX 进入纳指100、QDII额度、场内溢价这些问题。这些说法单独看,好像都有点道理;放在一起看,又很容易让人越看越乱。
所以这篇文章,我不想喊口号,也不想简单看多或看空,而是把近期最重要的几个问题聊一聊:
-
AI 需求到底还猛不猛?
-
token 降价到底是好事还是坏事?
-
GPU 会不会快速贬值?
-
云厂商投 AI 能不能收回钱?
-
中国大模型会不会卷死美国 AI?
-
SpaceX 进入纳指100会不会拖垮指数?
-
QDII额度和纳指溢价又该怎么看?
以下都是我的个人理解,不一定对,但尽量用数据和逻辑说话。

2 分析与讨论
2.1 AI的需求还很猛吗?
市场对于AI的需求很猛很猛。
这里我们重点观察两个代表性数据来说明。
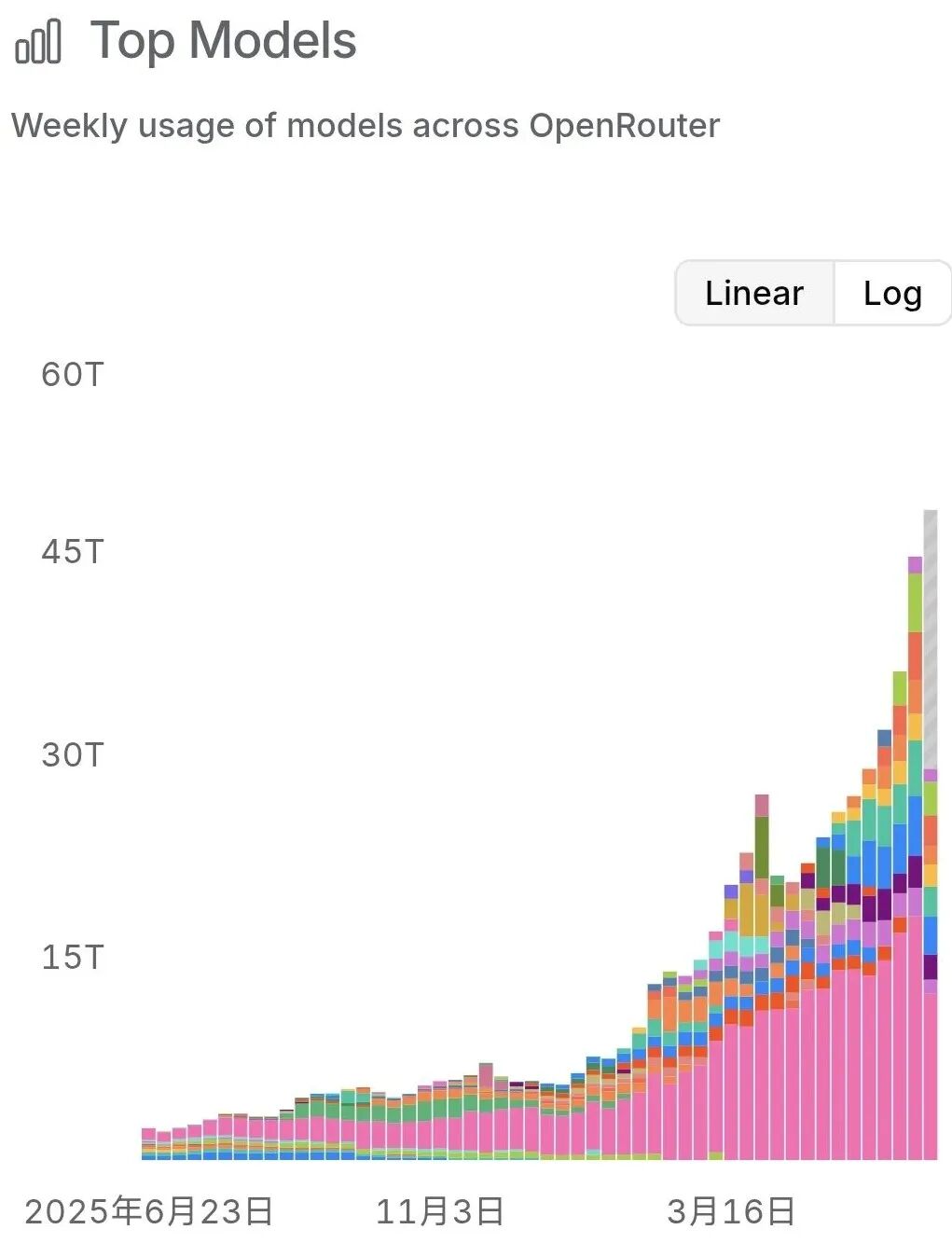
第一个数据是openrouter(全球最大的第三方token接入站点)上的每周token调用量数据。
根据下表可以看到,openrouter上token的周环比增速大约在10%以上。这个数据是很恐怖的,普通产业的增长速度大约是每年10%,这意味着一年顶上普通产业52年的发展速度。
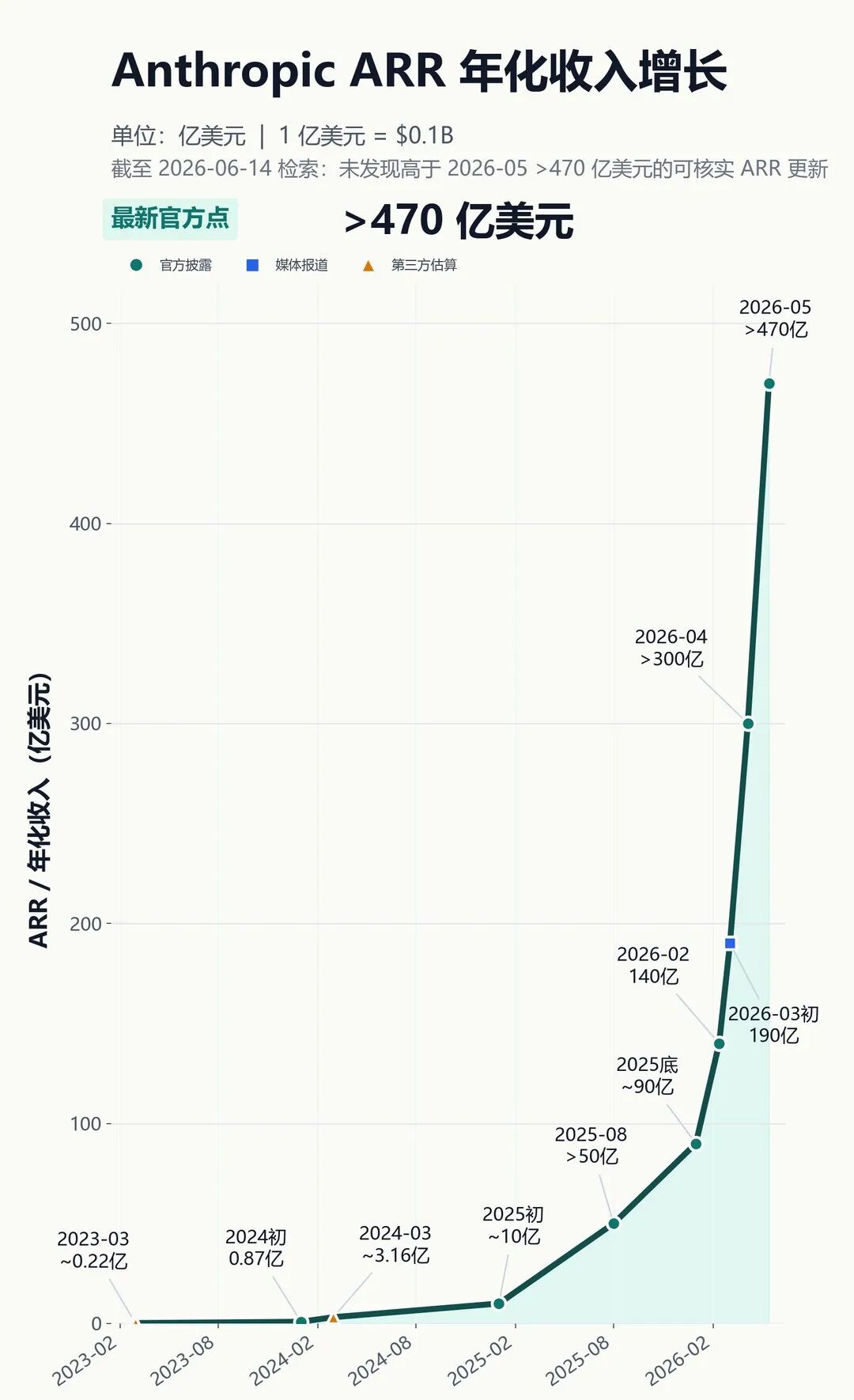
第二个数据就是anthropic公司的ARR年化收入。
可能部分人对anthropic公司不太熟悉,主要因为他主要面向公司客户以及编程市场,现在这家公司现在估值已经接近1万亿美元,已经超过openai了。
下图可以看到,anthropic公司的ARR持续爆发式增长,如今已经来到了470亿美元,这需求猛吗?当然了,后面增速肯定不会这么快了。
因此,整个市场对于AI的需求毫无疑问是很猛的。
最初的chat时代,AI只能用来聊天,一次消耗一点token;
后来出现了推理,是chat的几倍;
后来出现了智能体agent,又比推理时代的需求高一个数量级;
后来出现了...
随着AI能力越强,需求只会更猛。
任何人和任何组织都无法拒绝n个聪明的24h的打工AI。
那什么时候会饱和?或许直到每个人的电脑,每个人的手机,每家公司的服务器,每台汽车,每个机器人身上都随时运行着智能的时候,token需求的增速才会显著降低。
2.2 token降价了吗,影响如何?
是的,最近token价格指数确实降低了。
6 月 8 日以后,SDLLMTK(大语言模型LLM推理token使用成本指数,Silicon Data 官方说它是按美元/百万 token 表示的标准化混合价格) 变成热门“AI 体温计”:Seeking Alpha 把它称作 AI 多头不能忽视的图,市场开始用它讨论 AI boom 是否可持续。
6 月 11 日左右,焦点转向“token 价格战/支出降温”:MarketWatch 报道称该指数从 5 月底约 2.05 跌到 1.80,跌幅超过 10%,并把它和 OpenAI/Anthropic 价格竞争、企业客户觉得 AI token 太贵联系起来。
它就像一个导火索,引发了市场对AI的担忧。
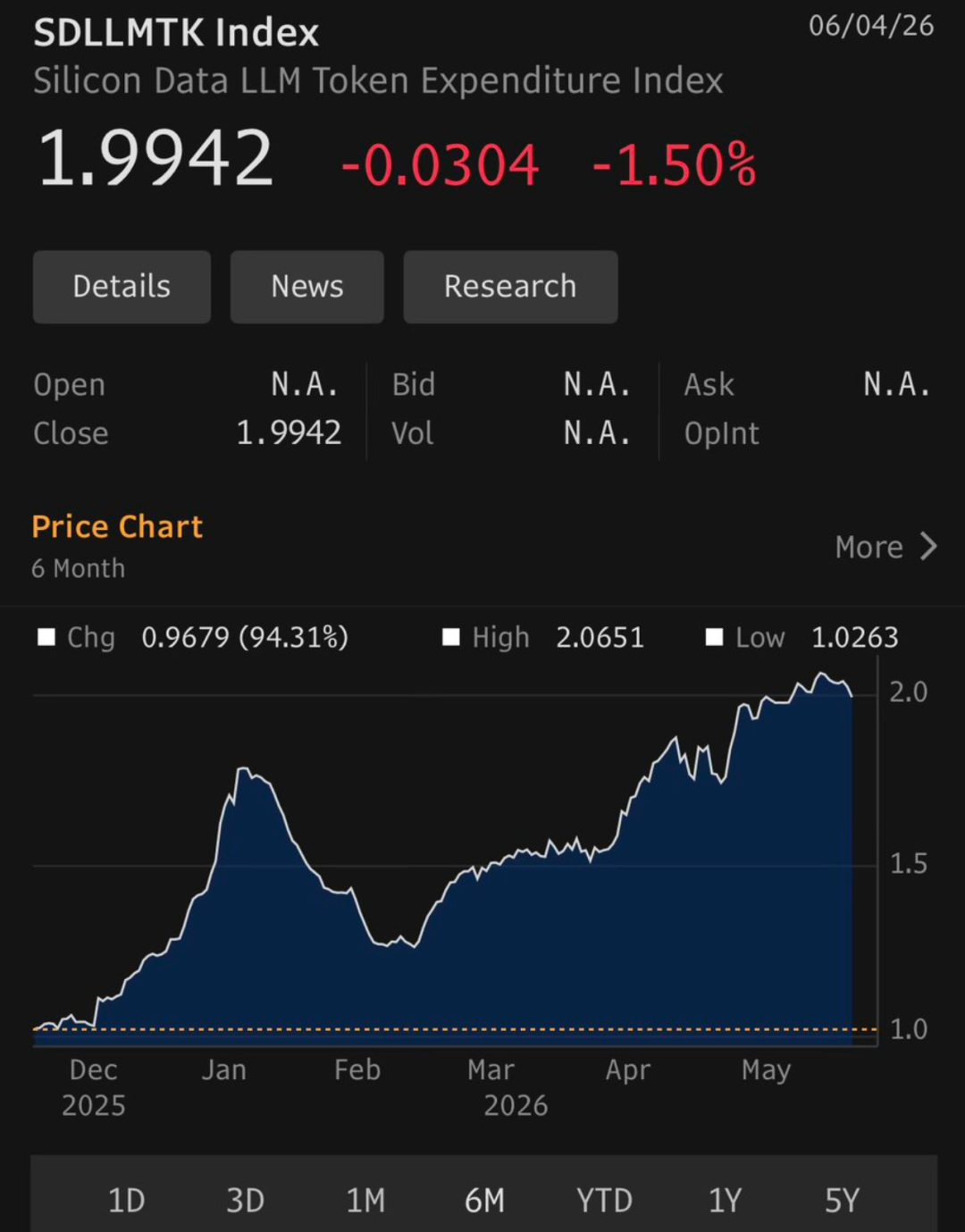
Silicon Data的这个价格指数不仅包含了openai,anthropic等美国顶级闭源大模型的价格,也包含了开源大模型(如deepseek等),跟踪 400+ models,每日篮子约 20+ models,覆盖超过 90% 的可寻址全球 LLM 推理支出。不过具体成分其实披露的并不透明。
由于价格下降主要在6月,这个价格指数的下降大概率源自:
-
开源模型的价格下移;
-
企业部分转向开源模型;
-
推理效率的提升与缓存价格的下降
不过需要说明的是,价格的下跌与用量增加是不矛盾的。前沿的贵模型用量也在增加,便宜模型的用量也在增加,只要便宜模型的增速更快(这个基本是肯定的,观察openrouter上的数据就能明白),那么综合价格指数就会表现为下降。
token价格的下降并非坏事,如果手机的价格还像曾经的大哥大那么贵,如果流量费还是5元30M,移动互联网会有今天的场景吗?
未来大模型token价格会怎么样变化?
答:极大概率是继续降价!原因请看2.3的分析与讨论。
2.3 英伟达GPU迭代速度如此之快,价格又如此之高,购买显卡的大客户要被折旧拖入深渊吗?
首先,英伟达 GPU 迭代快,这是真的。
从 A100 到 H100、H200、B200、GB200、GB300,再到 Vera Rubin,英伟达已经进入接近“年度迭代”的节奏。
其次,价格贵,也是真的。
B200 单卡公开估算大约 3-4 万美元,GB200 Superchip 大约 6-7 万美元。到了 Vera Rubin,市场估算单 GPU 约 5.5 万美元,一个 NVL72 机柜约 780 万-910 万美元。英伟达也在电话会上说过,1GW AI 工厂大约需要 500-600 亿美元,其中英伟达相关计算系统大约 350 亿美元。
但问题的核心不是“投入多少”,而是“资产能不能持续创造价值”。
云大厂一般把服务器和网络设备按 5-6 年折旧:微软计算设备大致 2-6 年,Alphabet 服务器和网络设备一般 6 年,Meta 多数服务器和网络资产 5.5 年,亚马逊部分 AI/ML 相关设备从 6 年缩短到 5 年。也就是说,并不是两年一迭代,旧卡就直接归零。
现实中,老 GPU 仍然有价值。最新 GPU 用来训练和高价值推理,上一代 GPU 可以跑推理、微调、embedding、小模型、内部 AI 工具。只要 token 需求继续增长,便宜算力反而会有自己的市场。
以 SpaceX的算力租给 Anthropic 和谷歌为例。
根据 SpaceX 文件披露,Anthropic 租用 Colossus/Colossus II 约 32.5 万张 NVIDIA GPU,月租金 12.5 亿美元。Google 向 SpaceX 租用约 11 万张 NVIDIA GPU,月租金 9.2 亿美元。
因此年化收入是:
(12.5+9.2)亿美元 × 12月 = 260亿美元/年再看整体投入。SpaceX 文件显示,其 AI 业务2023 年投入约 5 亿美元,2024 年 AI 资本开支约 56 亿美元,2025 年资本开支约 127 亿美元,2026 年 Q1 又投入约 77 亿美元,合计约 265 亿美元。
一年就收回主要成本了,投资算力卡不是吃亏,而是赚翻了!
按照5年折旧来计算,毛利润也接近60%,这是顶级生意!
这个案例能说明:在当前 AI 需求下,GPU 不是负担,而是稀缺现金流资产。市场真正该看的是 GPU 利用率和租赁价格,而不是简单看到英伟达迭代快,就认为老 GPU 会迅速归零。
只要 AI 需求还猛、算力仍然紧、老 GPU 还能出租和跑业务,折旧就是利润表压力,而不是资产归零风险。市场真正该担心的不是“GPU 太贵”,而是“这些 GPU 最后能不能产生足够多的智能收入”。
2.4 英伟达GPU租赁价格变化如何,为什么?
下图展示了H100为代表的算力卡每小时租赁价格的变化趋势。
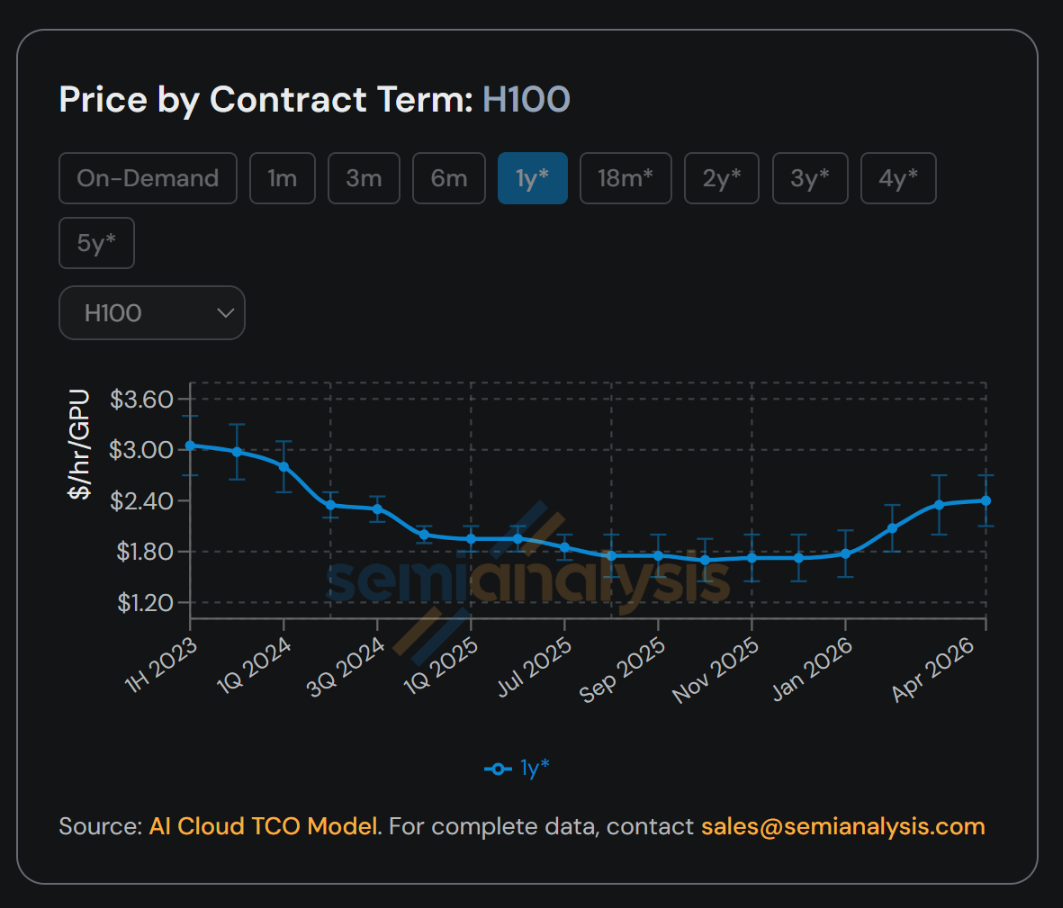
H100 是英伟达在 2022 年 3 月发布的,首批产品和云服务在 2022 年 10 月开始推出。所以图里 2023 年上半年价格很高,本质上是 ChatGPT 引爆需求后,H100 刚开始规模交付,供给极度紧张。这张图看的是 H100 一年期租赁价格,不是 GPU 购买价格。它大致经历了三段:
第一段,2023 年高位。
H100 刚量产不久,ChatGPT 又突然引爆大模型训练需求,云厂商、OpenAI、Anthropic、Meta、xAI 都在抢卡,而供给受制于台积电 CoWoS、HBM、整机集成、机房电力等环节,所以租赁价格可以到 3 美元/GPU/小时以上。
第二段,2024-2025 年下行。
英伟达供给上来,云厂商自建集群增多,H200、B200/GB200 陆续推出,H100 从“最前沿训练卡”逐渐变成“成熟主力卡”。同时推理优化、缓存、量化、调度提升,也压低了单位算力成本,所以 H100 一年期租赁价格一路降到 1.7-1.8 美元/GPU/小时附近。
第三段,2026 年重新上行。
这并不是因为 H100 变新了,而是因为需求又超过供给了。推理模型、agent、多模态、企业 AI 应用都在大量消耗算力;而 Blackwell/GB200 很贵、很紧、被大客户锁定,很多任务用 H100 仍然性价比很好。于是 H100 作为“成熟、稳定、好用、现货可得”的 GPU,租赁价格又回升到 2.4 美元/GPU/小时附近。
与此同时,模型的迭代更新其实也会提高旧硬件的价值。H100运行GPT5.5的时候,产生的是高价值的聪明token,自然要比运行GPT3.5产生的token价值更高。
H100就像一间厨房,做盒饭(gpt3.5)一天赚 1000 元;后来请来米其林厨师,做高端私宴(gpt5.5)一天赚 1 万元。厨房还是那间厨房,但因为产出的东西更值钱了,厨房的经济价值也变高了。
这张图真正说明的是:GPU 价格不只由新旧决定,更由供需和利用率决定。H100 虽然是 2022 年发布的产品,但只要 AI 需求继续增长,它仍然是能产生现金流的高价值资产,而不是简单随着新一代 GPU 发布就快速归零。千万别不经思考就相信别人满口胡言。
2.5 微软,谷歌,亚马逊等云厂商如此大力投入AI,能有回报吗?
我认为大概率能有回报,但回报方式不一定是“买 GPU,然后直接出租 GPU”这么简单。
对于云大厂来说,AI 算力有三种变现方式:
第一,直接变成云收入。
微软 FY2026 Q3 披露,AI 业务年化收入已经超过 370 亿美元,同比增长 123%;Azure 和其他云服务收入增长 40%。谷歌 Q1 2026 披露,Google Cloud 收入达到 200 亿美元,同比增长 63%,云业务经营利润 66 亿美元。亚马逊 AWS Q1 2026 收入 376 亿美元,同比增长 28%,经营利润 142 亿美元。这些不是概念股,这是已经在财报里兑现的收入和利润。
第二,AI 会提升原有业务的赚钱效率。
比如微软把 Copilot 卖进 Office、Windows、GitHub、Dynamics;谷歌把 AI 放进搜索、广告、YouTube 和 Gemini;Meta 把 AI 用在推荐、广告投放和内容分发。Meta Q1 2026 收入 563 亿美元,同比增长 33%,广告展示量增长 19%,平均广告价格增长 12%。这说明 AI 不只是成本,也在提升广告系统的效率。
第三,AI 算力本身正在变成稀缺基础设施。
Google 自己已经是云厂商,但仍然愿意向 SpaceX 租约 11 万张 NVIDIA GPU,月租金 9.2 亿美元。这说明什么?说明现在不是“GPU 没人要”,而是头部客户为了拿到算力,愿意支付很高的溢价。
所以,云大厂投 AI,短期肯定会压低自由现金流,折旧也会增加。但不能简单理解为“钱烧掉了”。这些钱买来的不是普通设备,而是未来几年云收入、软件提价、广告效率和企业 AI 工作流的基础设施。
真正要观察的不是“资本开支有多大”,而是三件事:
云收入是否继续高增长;
AI 产品是否能提价或提升用户粘性;
GPU 利用率和租赁价格是否保持强势。
目前看,微软、谷歌、亚马逊、Meta 的财报数据都还在证明:AI 投入正在产生收入,而不是只有故事。风险当然有,但现在更像是高资本开支换高增长,而不是单纯被折旧拖入深渊。
2.6 因为投资AI,美股大科技现金流要干了,是不是非常危险,泡沫要破裂了?
首先,因为AI投资,美股很多大科技的自由现金流要干了,这是正确的。
下图展示了Financial Times(FT)的预测分析。可以看到,大科技的现金流在2026和2027将会显著降低。
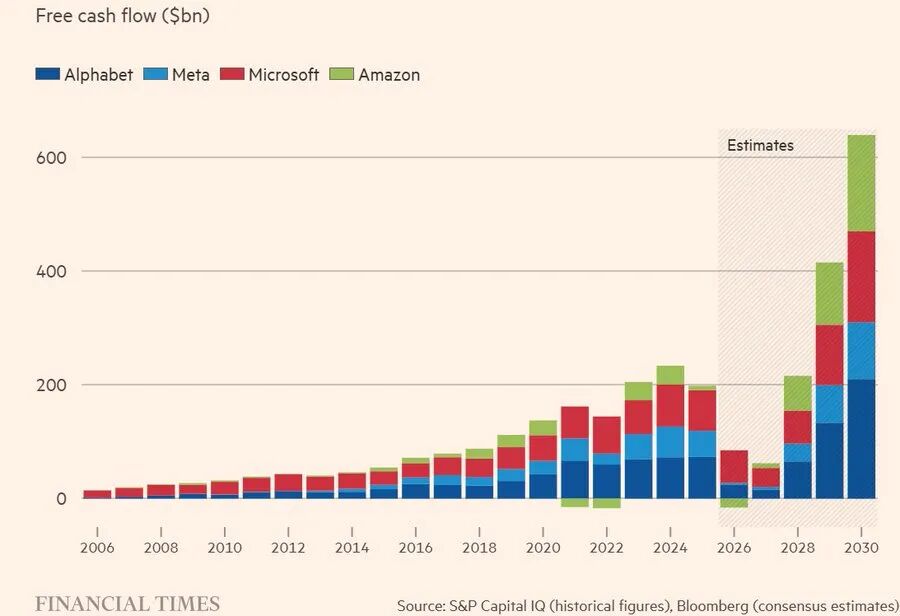
然而,这是否意味着一定危险,是否意味着泡沫破裂则不一定。关键还是看AI的投入是否有回报。
这里同样举个例子来理解:
比如一个人原来开奶茶店,每年能赚 100 万现金流。
后来他发现旁边新商圈要起来,于是花 300 万重新装修、买设备、扩门店。结果这一年自由现金流变成了负数,因为赚的钱都拿去投资了。
这时候能不能说这家店要完了?不能。
关键要看这 300 万花出去以后,未来能不能带来更多收入。如果扩店后每年利润从 100 万变成 300 万,那短期现金流下降不是坏事,而是投资期;但如果装修完没人买奶茶,那才是真正的风险。
AI 也是一样。
微软、谷歌、亚马逊、Meta 现在自由现金流下降,不是因为主营业务突然不赚钱了,而是因为把大量现金拿去买 GPU、建数据中心、扩 AI 基础设施。
所以,现金流变少本身不等于泡沫破裂。真正要看的是:这些 AI 投入,未来能不能带来更多云收入、广告收入、软件收入和效率提升。只要未来回报足够高,今天现金流下降反而是为了明天赚更多钱。
2.7 中国大模型和美国大模型有多大差异,未来竞争态势如何?
中美大模型最初差距非常大。2022 年 11 月 ChatGPT 3.5 问世时,国内基本没有同等级产品。
直到 2025 年初 DeepSeek-R1 出现,市场才真正意识到:中国模型在推理、代码、数学和成本控制上,已经追上来很多。Stanford 2026 AI Index 甚至提到,2026 年 3 月中美顶级模型性能差距一度只剩 2.7%。
但最近看,差距又有重新拉大的迹象。
原因很简单:OpenAI 和 Anthropic 不仅模型参数量明显更大,而且更新速度太快。OpenAI 从 GPT-5 到 GPT-5.1、GPT-5.2、GPT-5.4、GPT-5.5,不断迭代;Anthropic 从 Claude Opus 4.5、4.6、4.7、4.8,再到 Fable 5 / Mythos 5,也是在几个月内连续更新。相比之下,国内模型虽然也在进步,比如 DeepSeek、Qwen、Kimi、GLM,但最前沿闭源能力的迭代密度,暂时还是美国更强。
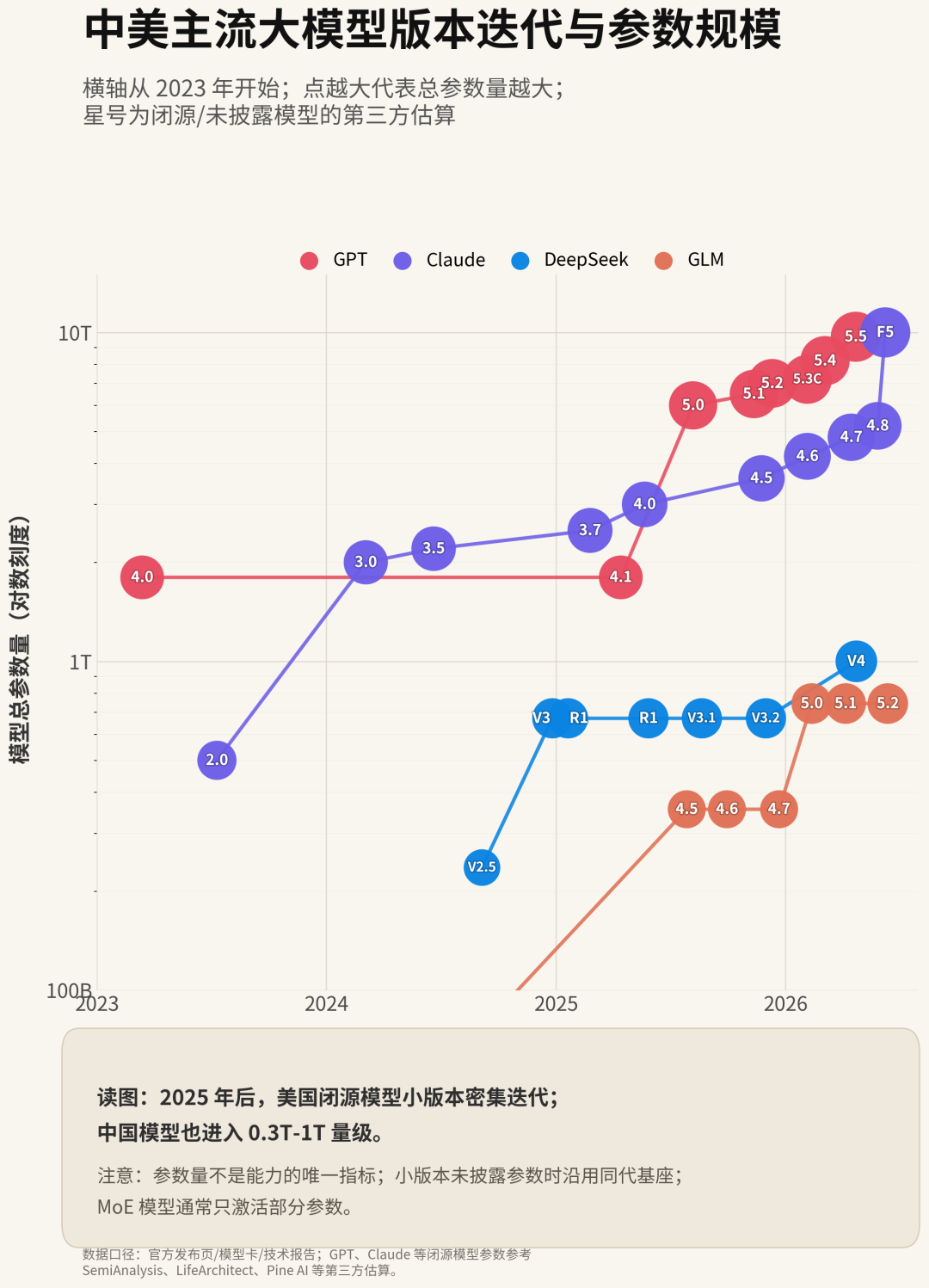
Epoch AI 数据显示,截至 2025 年 5 月,美国拥有约 74.5% 的全球 GPU 集群性能,中国约 14.1%。Stanford AI Index 也显示,2025 年美国私人 AI 投资约 2859 亿美元,是中国 124 亿美元 的 23 倍。模型训练不是光靠聪明就行,越往后越需要算力、数据、工程系统和持续烧钱能力。
如果大模型很快碰到技术上限,那中国肯定会快速追平。就像很多成熟制造业,一旦路线清楚,中国工程能力和成本能力非常强。
但问题是,机器智能的上限远高于人类智能。
现在 AI 还远没有到天花板,后面还有更强推理、更长上下文、更强 agent、更强多模态、更强机器人控制。只要能力上限还在继续抬高,算力更多、资本更多、生态更强的一方,就更容易保持领先。
所以,我认为未来大概率不是“中国干掉美国”,也不是“美国甩开中国看不见”,而是中美共同领导大模型技术:美国模型负责拉高能力上限;中国模型和开源模型负责压低使用成本。
2.8 中国大模型只有美国大模型价格的1%-10%,美国AI是不是要被卷死,收不回来投资了?
中国大模型价格确实很低。
-
OpenAI GPT-5.5 API 价格约 5 美元/百万输入 token、30 美元/百万输出 token;
-
Anthropic Fable 5 / Mythos 5 约 10 美元/百万输入 token、50 美元/百万输出 token。
-
DeepSeek 官方价格大约只有 0.14-0.435 美元/百万输入 token、0.28-0.87 美元/百万输出 token。
-
也就是说,中国模型在很多场景下确实只有美国前沿模型价格的 1%-10%。
但这不代表美国 AI 一定会被卷死。
原因是:AI 市场不是单一市场,而是分层市场。
普通摘要、客服、翻译、内部知识库、简单代码,这些任务会越来越多用中国模型和开源模型,因为便宜、够用、性价比高。
但最复杂的任务,比如高难度代码、科研、金融分析、法律推理、长链路 agent、自动化工作流,客户仍然愿意为最强模型付高价。因为这里贵的不是 token,而是错误成本。如果一个模型能帮企业少犯一次大错,或者让程序员少花 3 小时,几十美元 token 成本根本不贵。
就像手机市场一样。
小米、传音、荣耀把手机价格打下来,并没有让苹果破产。相反,低价手机让更多人用上智能手机,整个移动互联网市场变大了;而苹果仍然靠高端体验、生态和品牌赚高利润。
AI 大概率也一样。
中国模型会把 AI 使用门槛打下来,让更多企业和个人开始大量使用 token;美国前沿模型则继续负责最难、最贵、最有价值的任务。便宜模型扩大需求,顶级模型赚能力溢价。
所以,价格下降会冲击“单纯靠普通 API 卖高价”的模式,但未必会摧毁美国 AI。真正危险的是模型能力停滞、需求不增长、GPU 利用率下降。只要 AI 能力继续提升、使用量继续爆发,价格下降反而可能像当年流量费下降一样,把整个市场做得更大。
2.9 spaceX会纳入多少比例进入纳指100?
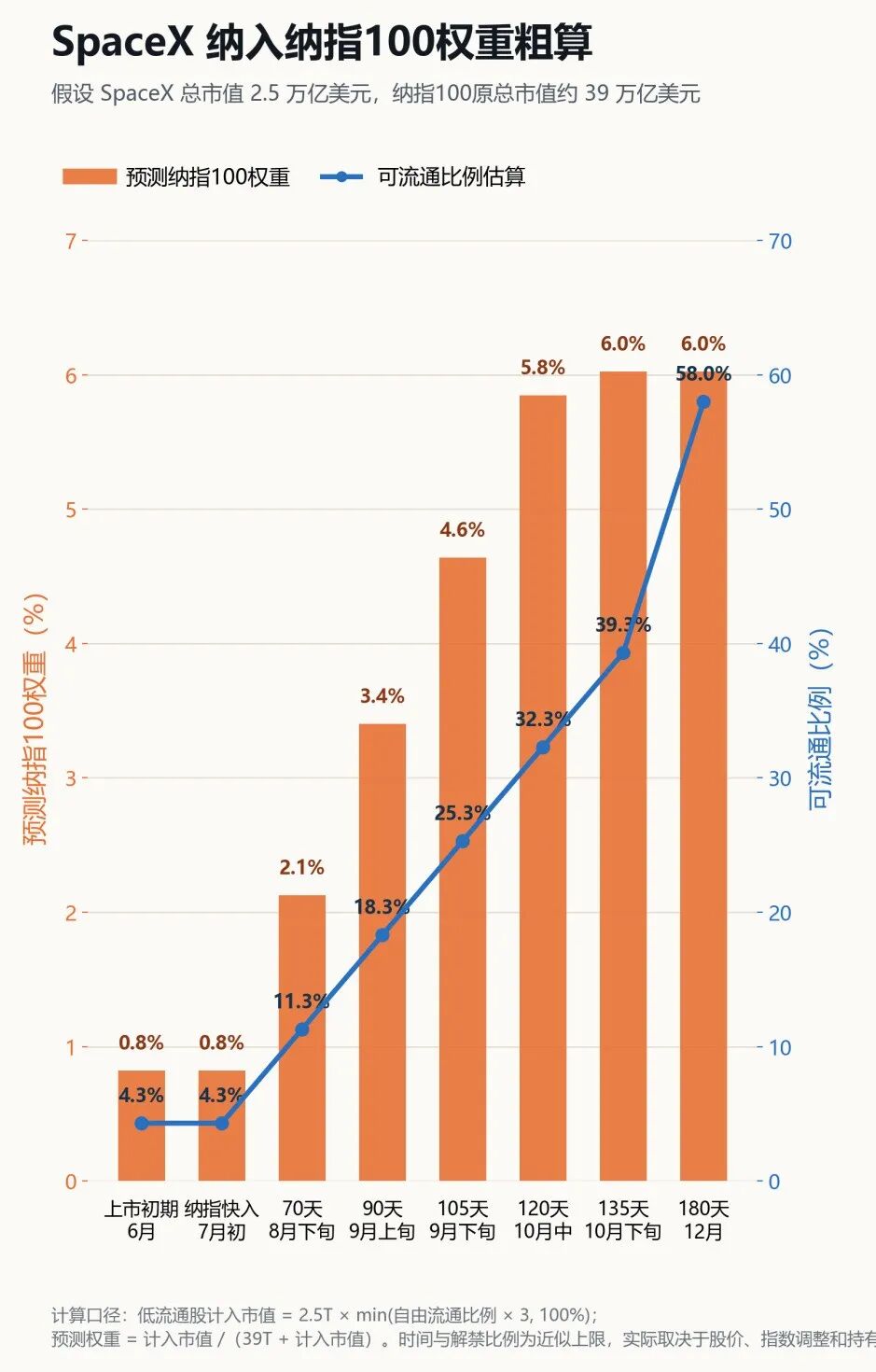
按 SpaceX 总市值 2.5 万亿美元、纳指100原总市值约 39 万亿美元粗算,SpaceX 纳入纳指100后,初始权重不会特别高。
原因是纳指100对低流通股有折扣处理:自由流通比例低于 33.3% 时,计入市值大约按“自由流通比例 × 3”计算;超过 33.3% 后,才基本按完整市值计入。
所以,SpaceX 上市初期自由流通比例约 4.3%,对应权重大约只有 0.8%。随着解禁推进,如果自由流通比例升至 18.3% / 25.3% / 32.3%,权重可能升至约 3.4% / 4.6% / 5.8%。
当自由流通比例超过 33.3% 后,在 2.5 万亿美元市值假设下,SpaceX 在纳指100中的权重大约会稳定在 6%左右。
也就是说,SpaceX 对纳指100的影响不是一次性释放,而是会随着流通盘扩大逐步抬升。
2.10 如何看待spaceX进入纳指100,它会拖垮纳指100吗?
SpaceX 进入纳指100,是一件影响很大的事情。
因为它不是普通新成分股,而是一个刚上市就达到万亿美元级别的超级公司;同时,它的估值也非常贵。按 SpaceX 总市值 2.5 万亿美元估算,若后续自由流通比例提高,它在纳指100里的权重可能升到 6%左右。这意味着 SpaceX 会直接成为纳指100的重要权重股之一。
一方面,SpaceX 的纳入,给纳指100带来了新的科技方向。过去纳指100主要代表互联网、软件、芯片、云计算;现在 SpaceX 进来后,纳指100进一步增加了太空、卫星通信、国防、AI 算力基础设施这些新方向。
另一方面,它也确实提高了纳指100的风险暴露。SpaceX 当前估值很高,而很多长期故事还没有完全兑现,比如 Starship、Starlink 手机直连、Starshield、AI 算力、太空数据中心等。一旦预期落空,股价波动肯定不会小。
但我并不太担心 SpaceX 会“拖垮”纳指100。
原因很简单:就算 SpaceX 最终权重大约是 6%,如果股价腰斩,对纳指100的拖累也大约是:6% × 50% = 3%
3% 的影响当然有,但远远谈不上拖垮纳指100。纳指100里还有英伟达、微软、苹果、谷歌、亚马逊、Meta、博通等公司。SpaceX 是重要变量,但不是唯一变量。
为什么美股愿意给 SpaceX 这么高的估值?
核心原因是:市场不是只按现在的利润给它估值,而是在给它的多个长期期权定价。
第一,Starlink 已经证明自己能赚钱。2025 年,SpaceX Connectivity 业务收入约 114 亿美元,经营利润约 44 亿美元,Adjusted EBITDA 约 72 亿美元,这已经不是纯概念。
第二,SpaceX 有稀缺的基础设施能力。它不是普通互联网公司,而是同时掌握火箭发射、卫星制造、全球通信网络、政府合同和 AI 算力建设的公司。这种垂直整合能力,全世界几乎没有第二家。
第三,市场在押注未来的新业务。Starlink 宽带客户、手机直连卫星、Starshield 国防通信、Colossus AI 算力租赁,甚至未来的太空 AI 数据中心,任何一个方向做大,都可能打开新的收入空间。
所以,我更愿意把 SpaceX 看成纳指100里的“彩票股”:抽中了,可能带来很大上行;抽不中,也不至于把整个指数拖入深渊。
它贵,这是真的;风险大,也是真的。但它进入纳指100后,更像是给纳指100增加了一个高波动、高想象力的新科技资产,而不是一个足以毁掉指数的炸弹。
然而需要注意的是,彩票股如果越来越多,那就逐渐变得危险了,比如:特斯拉,spaceX...
2.11 为什么纳指100和标普500不在一个层级?
标普500是真正意义上的大宽基。
它覆盖美国约 500 家大型公司,行业分布更广,既有科技,也有金融、医疗、消费、工业、能源、公用事业等。S&P Global 自己也说,标普500覆盖约 80% 的美国可投资市值。所以标普500更像美国经济的综合代表。
纳指100则更像“偏科宽基”,或者说“小宽基”。
它只选纳斯达克上市的 100 家非金融公司,科技、互联网、芯片、软件权重很高,金融、能源、传统工业这些基本缺席。所以它弹性更大,牛市涨得猛,但结构也更集中。
其次的区别是规则严谨度。
标普500对新上市公司更严格。它要求 IPO 后通常要有 12 个月交易历史,还要求最近一个季度盈利,并且过去四个季度合计盈利。也就是说,公司不仅要大,还要经过时间和盈利能力的验证。
这次 SpaceX 就是一个典型例子。
纳指100为了大市值 IPO 设立了快速纳入规则,允许符合条件的新上市公司最快 15 个交易日 后进入指数。而标普500没有跟进,仍然保留 12 个月 IPO seasoning period 和 GAAP 盈利要求。也就是说,SpaceX 可以很快进入纳指100,但短期进不了标普500。
这背后反映的是两种指数性格:
纳指100更进取,更愿意快速拥抱新科技巨头;标普500更保守,更强调稳定性、代表性和可投资性。
所以,纳指100不能和标普500完全等同。纳指100适合押注美国科技创新,尤其是 AI、云计算、芯片、软件、太空这些高成长方向;标普500则更适合作为美国核心资产配置,因为它更分散、更稳,也更能代表美国整体上市公司。
2.12 新一轮QDII额度什么时候发,发多少,影响如何?
2026陆家嘴论坛于6月17日上午正式开幕,中国人民银行副行长、国家外汇管理局局长朱鹤新表示,近期将新增推出“一揽子”增量政策,全面改革FDI跨境政策,进步简化OD1、外债等汇兑管理,优化外汇贷款、跨境股权激励等制度,发放新一批QDII额度。
去年陆家嘴论坛,也是发了新一轮额度,大约30亿美元。今天只是惯例罢了。如果一切正常,大约也是6月30日的时候宣布消息。
额度会发多少呢?如果按照往常惯例,预计是30亿美元左右(观QDII额度变化,论QDII基金 — 第4版)。不过考虑到今年外汇局的大动作,可能会额外多给一些。因此,可以期待30-50亿美元。
现在纳指溢价中位数来到了9%附近,这次外汇额度发放会使溢价显著降低吗?
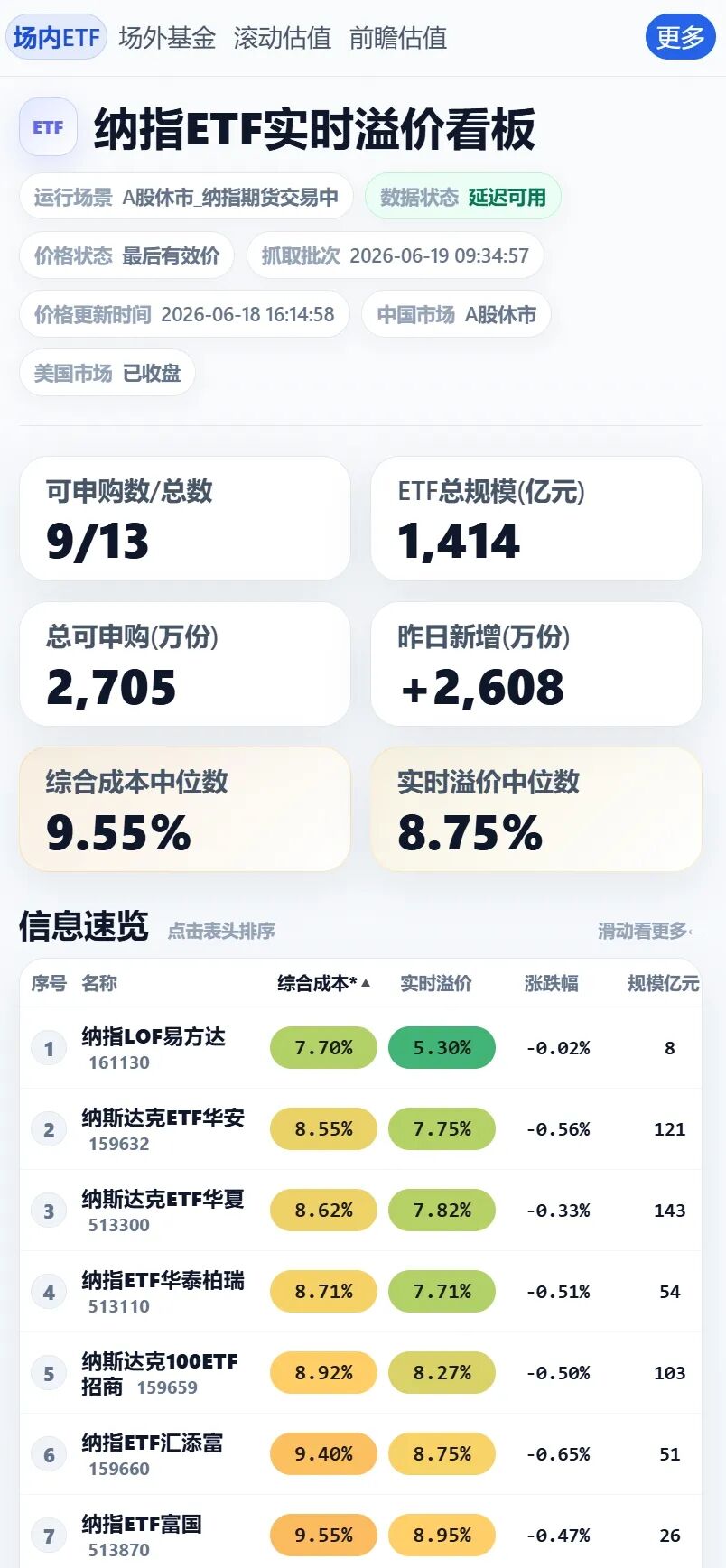
首先说结论:大概率不降低,或者降低1%-3%左右。
假设发放多一些,比如50亿美元。基金公司会发多少给场内纳指呢?实际上1/3都不一定会有。为什么?
答案很简单,留给专户,留给场外直销份额,主动纳指,全球科技类,每年躺赚1.2%-2%,凭什么便宜场内ETF那些0.6%-0.8%呢。
此外,现在想买的纳指的人远比之前多了,纳指远比2018,2020,2022年知名度高多了。这会显著支撑溢价。
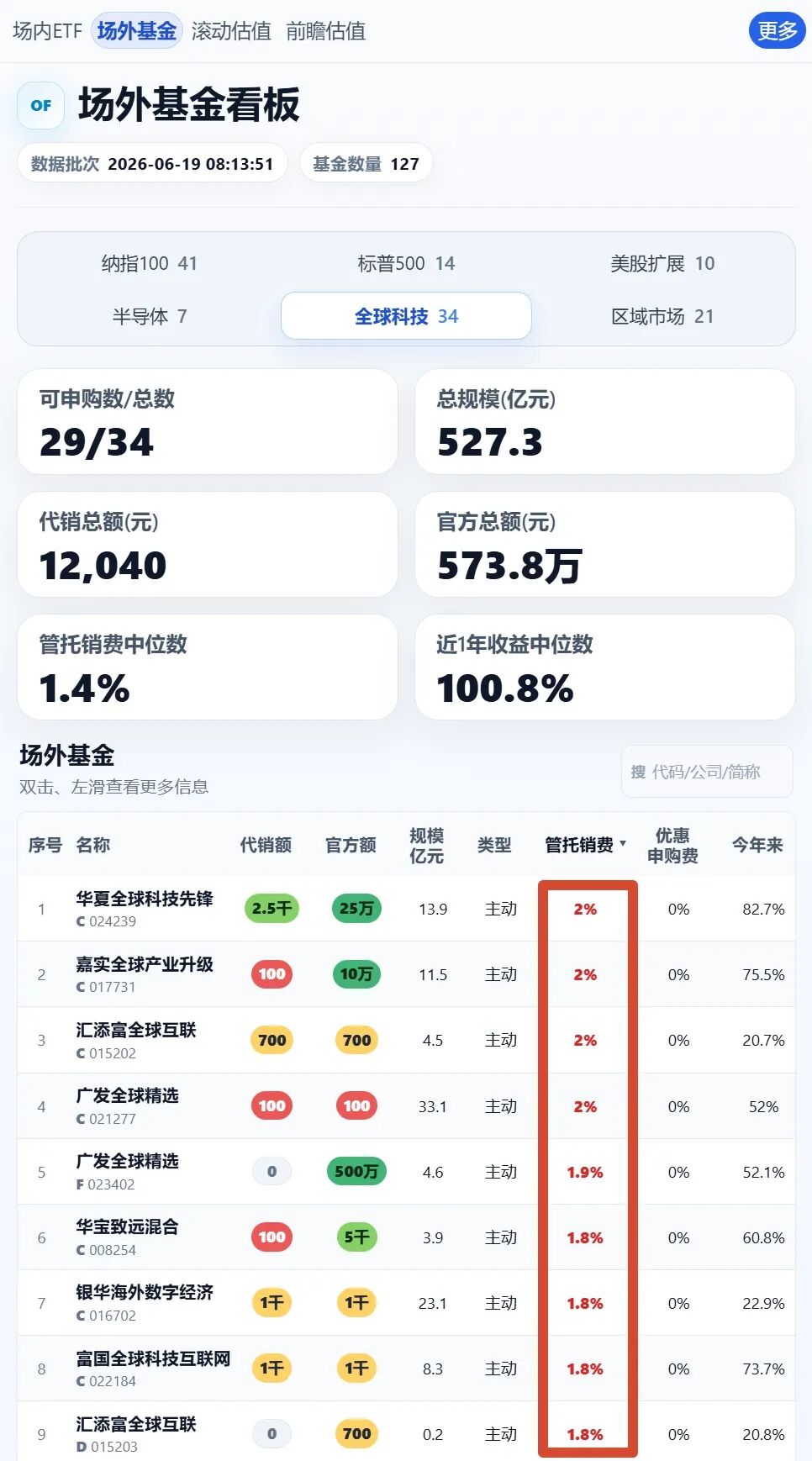
2.13 场外纳指限额好严重,基本都暂停了,怎么办?
现在场外纳指代销额限制确实十分严重。
不过仍然还有部分基金公司不时放出额度。比如广发,华安和南方的官方直销渠道,每日仍然还有1000元的额度,足够普通人用了。同时,新一轮QDII额度即将发放,后面肯定还有信额度。
同时,自6月22日起,万家的纳指AC份额也放出了每日1万的额度,天天基金已经更新,支付宝预计要到6月22日更新信息。
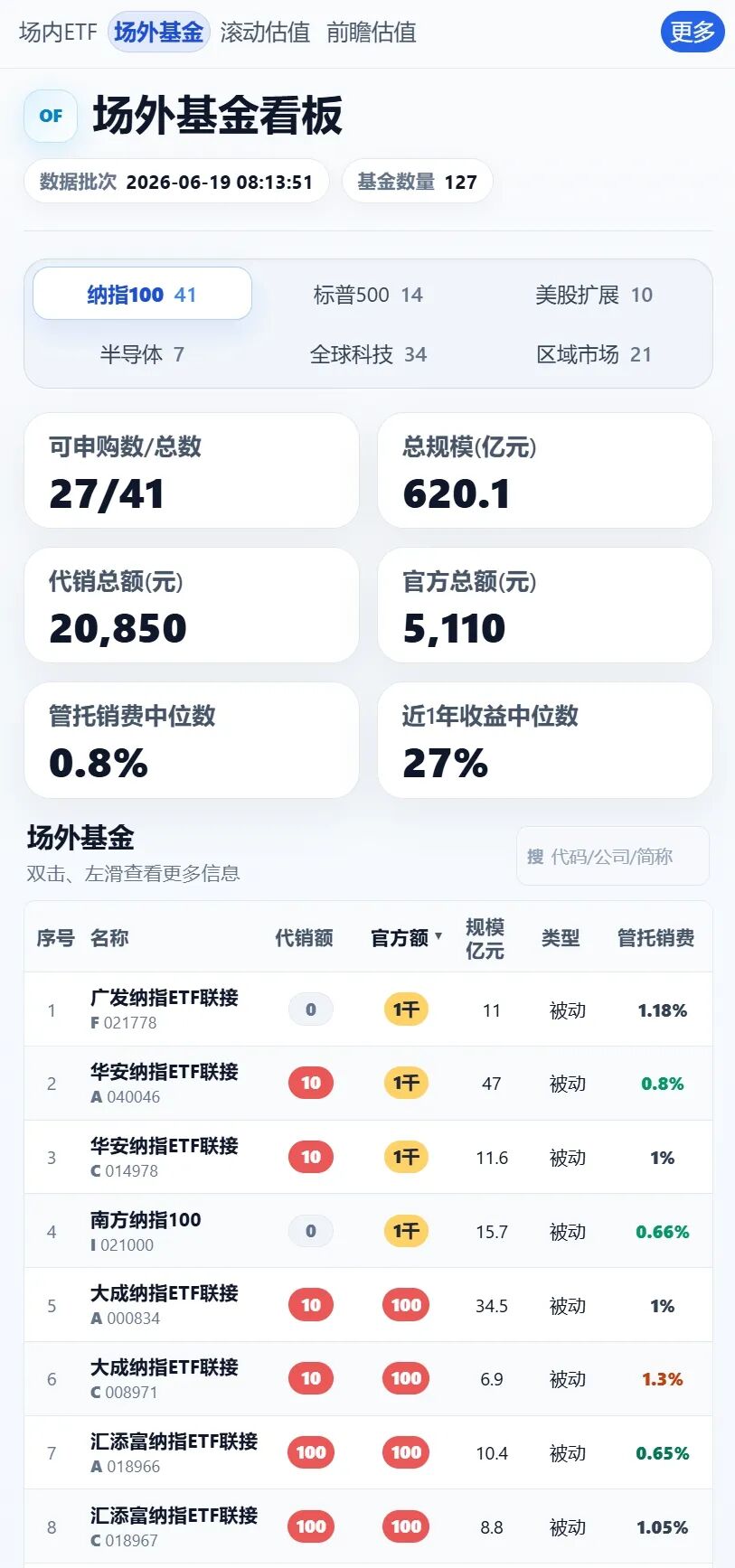
此外,华宝纳指精选纳指精选这个额度还很充足。我知道很多人说这个不是纯正的纳指。它确实不是,不过它的业绩基准是纳指100,近一年略微落后,近三年收益反而还超越纳指100了。
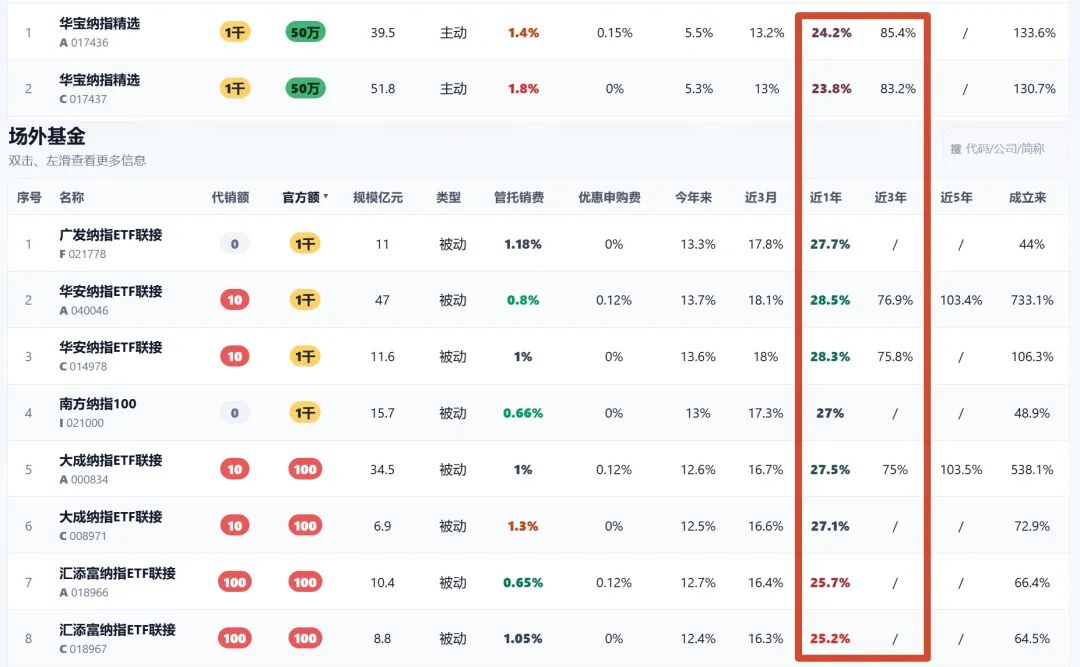

此外,这个市场不仅有场外,还有场内,不仅有纳指,还有标普500和美国50,场内LOF/ETF的溢价率并不是都高。
总之,不要自己给自己限制,也不能既要方便,又要可靠,还要高额度,还要低费率,这不可能。你只能自己多了解,然后思考哪个适合自己,无人能替你做决定。
3 结论
整体看,我对这轮 AI 和纳指100的判断是:风险确实在上升,但现在还没有看到泡沫破裂的核心证据。
纳指100仍然是押注美国科技创新最直接的工具,但它不是标普500。它更集中、更偏科、更刺激,也更容易出现阶段性大波动。
-
如果你买的是纳指100,就要接受它的性格:涨的时候很猛,跌的时候也不会温柔。
-
如果你追求更稳,更分散的美国核心资产,标普500仍然是更底层、更可靠的选择。
-
如果你买的是场内QDII,还要额外考虑溢价、额度和流动性,不要只看指数涨跌。
AI、SpaceX、纳指100,都不是没有风险。但目前真正的问题不是“有没有风险”,而是这些风险有没有被增长覆盖。
只要 AI 需求继续增长,算力仍然紧缺,云厂商收入继续兑现,纳指100的长期逻辑就还没有被破坏。
但如果未来出现 GPU 利用率下降、云收入放缓、AI 产品无法变现、SpaceX 高估值故事落空,那就需要重新评估。
注:本文仅是个人投资记录,不为任何人提供建议。成年人为自己的钱负责!
引申阅读:
经典文章合集 第7版
基金横评合集 第7版
如何开一个实惠的好账户?
免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。
