
滴普科技牵手南科大、天津大学及上海交大等多所高校,成立智能体评测开放实验室
6月12日,据市场消息,滴普科技(01384.HK)联合南方科技大学、天津大学、上海交通大学等海内外高校,正式发起成立AgentOS OpenLab——一个聚焦智能体过程级评测的开放实验室。该实验室定位为开放、中立、可复现的评测基础设施,由南方科技大学牵头研究与运营,滴普科技作为发起方、赞助方与资源支持方。这是国内首个关注智能体执行过程、而非仅看最终结果的评测社区。

大模型产业正经历从“内容生成”到“任务执行”的范式迁移。当AI从聊天机器人进化为能够规划、调用工具、与环境交互的智能体时,企业客户面临的核心问题不再是模型够不够快,而是AI员工能不能在我的业务里被信任。
传统评测体系无法解决这个问题——一个智能体可能答对结果,但推理路径错误且不可复现;也可能答错,但过程中展现了正确的规划与自我修正。这在企业级应用中是不可接受的,尤其当AI承担售后工程师、财务分析师、施工协调员等真实岗位时。AgentOS OpenLab提出的解决方案是用“基于Rubric的LLM-as-a-Verifier”替代传统的单次主观打分,通过记录完整执行轨迹、切分关键检查点、生成可量化评测规则,实现评测的可记录、可验证、可复现。
AgentOS OpenLab的成立释放了一个关键信号:滴普科技正在从提供“企业AI员工平台”的产品公司,向参与定义行业评测标准的基础设施层玩家跃迁。这样的企业往往致力于解决企业AI落地的三大约束——私有性、可信性与协同性。
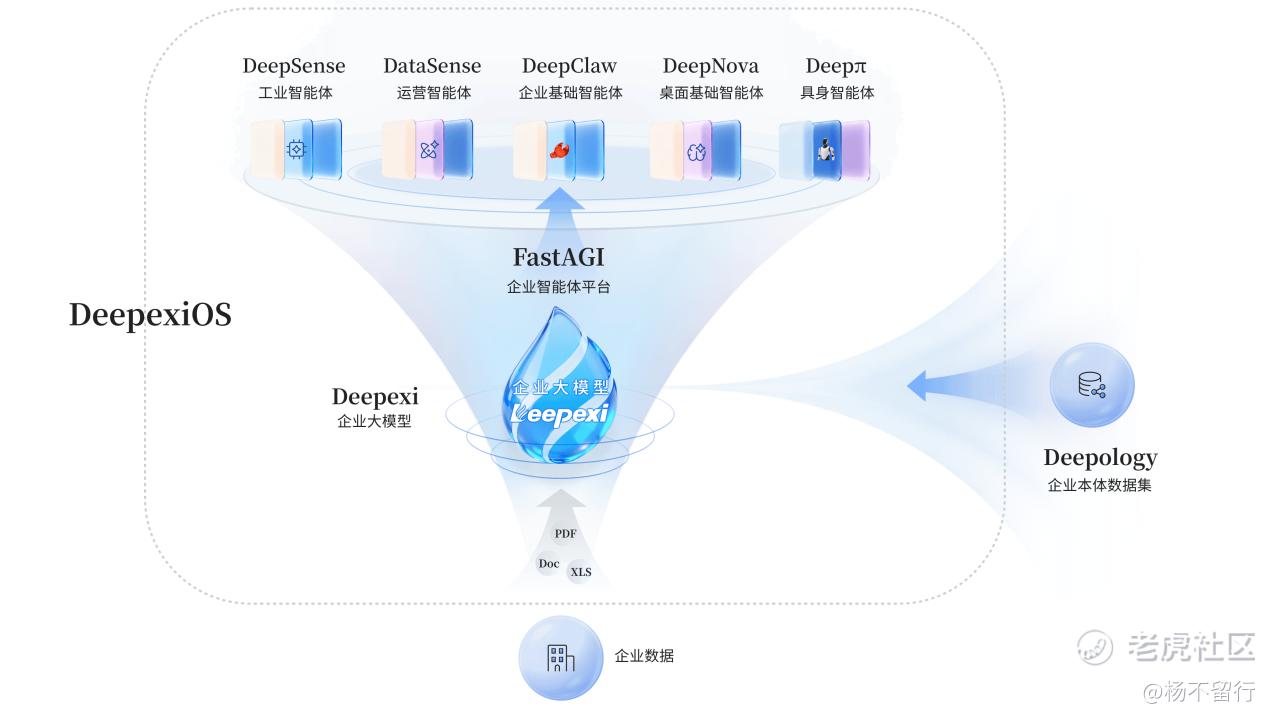
滴普科技通过Deepexi企业大模型将私有知识体系与业务逻辑训练进模型参数而非外挂知识库,再通过FastAGI多智能体协同平台组织AI员工分工协作,已在制造、零售等领域服务超过400家大中型企业客户,其中制造业收入占比超过50%。评测是“可信”的最后一道关卡,OpenLab的成立意味着滴普科技正在将自身产品内对“可信”的工程实践上升为行业通用的评测基础设施,这是其从“卖软件”到“建生态”的关键一步。
从产学研协同的视角来看,AgentOS OpenLab的成立具有三重深层意义:
第一, 填补学术界在AI Agent过程级评测上的空白。 当前高校研究多集中在模型能力或最终任务成功率,缺乏可复现、可细粒度诊断的执行轨迹评测体系。OpenLab由南方科技大学牵头运营,将帮助企业级场景中的真实问题反向输入学术研究,推动评测理论、Benchmark与开源工具的系统性产出。
第二, 构建企业与高校之间“双向赋能”的新型合作机制。 滴普科技提供场景、算力与工程实践,高校提供研究能力与中立性。实验室的治理机制明确规定:滴普科技是发起方、赞助方与资源支持方,而研究与运营由高校主导,Benchmark、评测任务、轨迹库、工具链由全体共建团队共同建设。这一设计不仅避免单一商业主体定义标准带来的公信力风险,更让学术评价体系与产业落地需求形成正反馈循环。
第三, 打通从人才培养到产业标准的完整链路。 通过开放实验室,高校师生可以直接参与企业级智能体评测任务的设计与验证,毕业生在入学阶段就接触工业级可信AI工程问题。长期来看,这有助于为中国智能体产业培养一批既懂理论又懂评测实践的复合型人才,而这些人将成为下一代企业AI基础设施的标准制定者。
根据发布的时间表,OpenLab将在2026年6月底前跑通MVP Benchmark与首批共建任务,7月收集创始共建团队的反馈与改进建议,9月底发布开源工具、评测结果、数据集与阶段性研究成果,2026年底推动Agent Benchmark Challenge与年度发布会。
智能体市场正在从技术可行性验证走向企业规模化落地阶段。在这一转折点上,谁能定义“可信”的度量标准,谁就掌握了下一代企业软件市场的定价权。滴普科技选择以开放社区的方式押注这一方向,既是战略卡位,也是一场需要耐心的长期投入。当别人还在比拼上下文长度和推理速度时,滴普已经在定义“可信”的标准;当别人还在拿通用模型的benchmark分数讲故事时,滴普已经把评测的裁判权交给了高校和开源社区。这不是一场营销秀,这是一场面向未来三到五年的战略豪赌。而资本市场最喜欢的故事,恰恰就是这种“别人看不懂、学不会、追不上”的长期主义。
免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。
