
5个真实场景实测:云知声U2,可能是最能“干活”的大模型

撰文 | 李信马
题图 | 云知声
AI行业似乎正在陷入一场无序的“Token消耗赛”。
全球范围内的Token消耗正在迅速增长,Uber的5000名工程师仅仅4个月就烧完了全年的AI预算,迫使Uber出台分级限流措施管控成本;微软核心的Experiences and Devices部门内部曾大规模放开使用Claude Code,但仅半年就因Token成本远超预期而叫停;就连OpenAI的CEO奥特曼也感慨,目前有员工的月Token消耗达到1000亿,甚至曾有员工30天消耗了6030亿Token、一周消耗2100亿Token,但他们依旧算不上全球Token消耗量最高的人。

增长源于AI从“对话模式”向“Agent模式”的演进,一个复杂Agent任务的Token消耗量,轻松就达到普通对话模式的几十甚至上百倍。摩根大通曾预测,中国的AI推理Token消耗量预计将从2025年的约10千万亿增长至2030年的约3900千万亿,五年间增长约370倍。
想要让AI创造海量价值的同时,又能减少大量无意义的算力消耗,Agent选用的核心模型是关键。过去几年,大模型领域的主流竞赛逻辑可以概括为三句话:更大的参数、更长的上下文、更复杂的推理链条,这场以算力为底座的竞赛,把训练和推理成本一路推高。而现在,随着AI的规模化落地,性价比的重要性日益凸显。
6月8日,云知声正式发布了新一代通用大语言模型——U2。这款大模型是面向个人、开发者与组织打造的原生智能体大模型,技术主张极为纯粹:高智能密度 × 高Token价值。简单来说,就是不追求堆叠参数和输出长度,而是追求用更少的资源承载更强的能力,让每一次调用都更接近交付结果。
尤其值得一提的是,U2强调面向真实任务的连续执行能力,官方介绍其在复杂办公、软件工程、深度研究与多工具协同场景中,能够自主拆解并推进100+步复杂工作流,将需求理解、任务规划、环境交互、工具调用、过程纠错与结果验收串联为完整闭环。
最新发布的一系列国内外权威能力评测中,U2在多个关键能力方向进入主流大模型第一梯队:
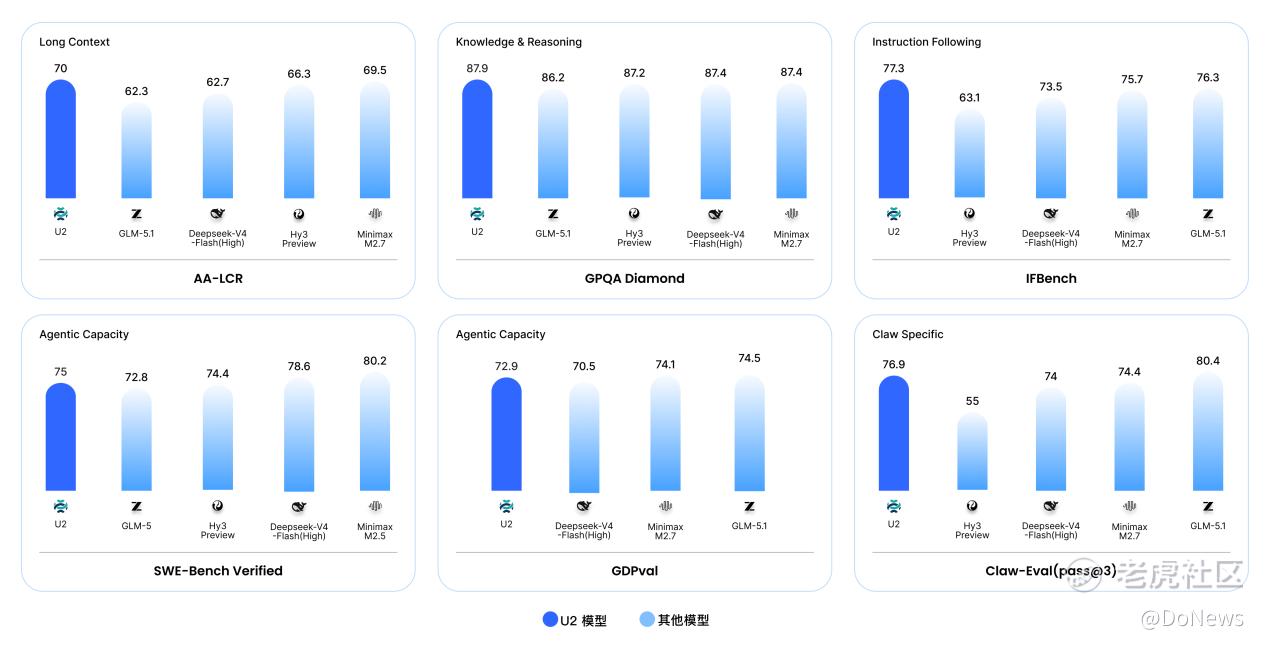
在衡量知识与复杂推理能力的 GPQA Diamond 上,U2取得了87.9分,超过GLM-5.1、Hy3 preview、DeepSeek-V4-Flash(High)和MiniMax M2.7;在衡量真实软件工程能力的 SWE-Bench Verified 上,U2以75分的成绩进入主流模型第一梯队;在面向自主Agent端到端执行能力的 Claw-Eval(pass@3)上,U2的76.9分超过了Hy3 preview、DeepSeek-V4-Flash(High)和MiniMax M2.7;在面向真实办公与知识工作交付能力的GDPval上,U2也取得了72.9的高分。
“真的能干活”,是U2给人的直观感受。接下来,我们用几个真实的工作任务,来测试一下U2的实际表现。
U2评测:当大模型进入执行力竞争,U2交出了一份第一梯队答卷
场景1:经典游戏编程——俄罗斯方块
打开后可以看到界面很简洁,左边专家列表中还有“高效办公”、“金融分析”、“深度研究”三个选项。我们先直接对话,来考验一下U2的代码能力——代码是最不会骗人的东西,行不行跑一下就知道了。
俄罗斯方块堪称大模型编程能力的“体测项目”,要求逻辑严密、实时交互,还得兼顾前端呈现。很多模型能写出能跑的代码,但界面丑得像上世纪产物;有些则反过来,页面漂亮但核心逻辑全是bug。所以这道不算难,但要求不低,让U2用网页来做一个经典的俄罗斯方块小游戏,要求支持用电脑键盘的方向键来控制方块的移动和变形,还要有计分功能,并把所有代码都写在一个文件里,保存后双击就能直接在浏览器里玩。
指令发出后,U2很快就设计并实现了一个完整的俄罗斯方块游戏,并把所有的HTML、CSS和JavaScript代码都整合在一个文件里,从视频可以看见,双击打开后浏览器瞬间加载出简洁的游戏界面:黑色的游戏区域、右侧实时更新的计分板,以及底部的操作提示一目了然。
实际操作时,方向键控制方块左右移动、快速下落的响应极为灵敏,上键触发的方块变形,还有方块被填满时自动消除并累计分数也完全符合俄罗斯方块的经典规则,整个游戏过程没有出现任何逻辑错误。可见U2除了能熟练编写代码,在前端设计方面也颇具实力,从功能开发到页面布局、视觉呈现一站式完成。
场景2:实战网页设计——产品发布倒计时&邮箱注册
接下来是一道更贴近实战的题——做一个产品发布页面。为什么选这个场景?因为这才是大多数中小企业开发者每天都在干的活儿:一个落地页,要有倒计时制造紧迫感,要有邮箱收集做用户沉淀,要看起来像一个正经产品而不是学生作业。这类任务不需要多高深的算法,但考验的是模型能不能把设计审美、交互逻辑和业务需求糅在一起,一次**出能用的东西。给U2的指令很直接:构建一个产品发布页面,并带上倒计时和邮箱注册。
和上一个任务类似,打开文件后,页面呈现出来简洁现代的科技感设计,中间区域的倒计时组件尤为吸睛,完全满足日常产品发布页面的核心需求,甚至在细节处理上超出预期。
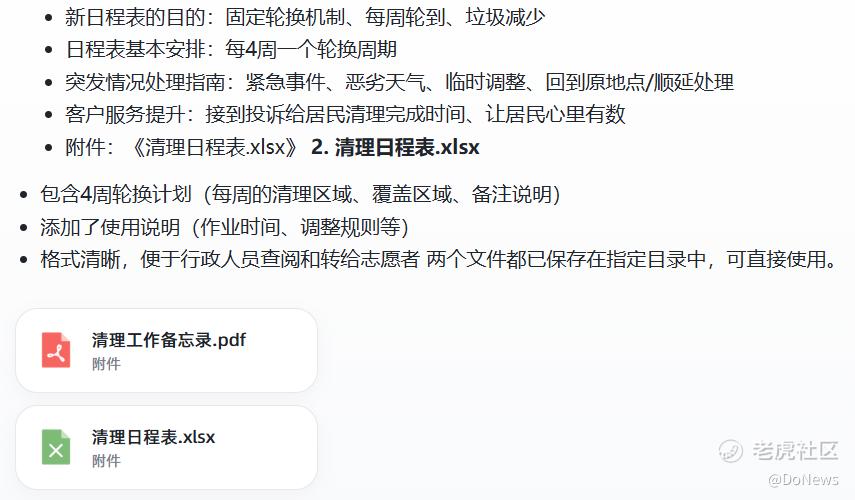
场景3:高效办公——社区轮换排班和PDF/Excel生成
前两道题考的是代码,但很多打工人日常面对的往往是琐碎且耗时的工作,比如排个班表、写个通知、导个Excel。很多大模型写代码挺利索,一到这种“帮我做个文件”的需求就开始掉链子,像是格式不对、内容逻辑错误,甚至文件根本打不开。
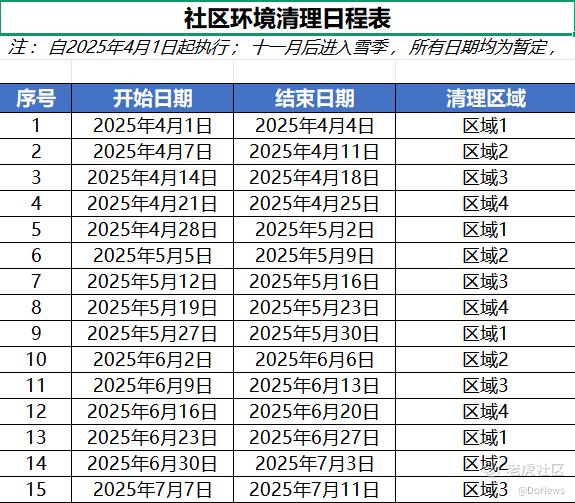
所以,接下来就真的是走入日常的生活工作中,考验U2处理实际问题的能力。首先,我们测试下高效办公场景,我假设自己是一名社区的行政服务经理,针对社区垃圾堆积的情况实施定期轮换清理计划,让U2为我制定新的日程表,并做成PDF和Excel文件发给我。
很快,界面上就显示已完成请求,并生成了对应的文件,下面是截取PDF和Excel文件的部分内容,可以看到U2清晰列出了每周各楼栋的垃圾清理轮换时间,通知文件也符合正常行文的标准,可以直接使用。

场景4:金融分析——持仓回撤评估与调仓建议
前面测试的是执行力,但U2能不能胜任更专业的活儿?接下来进入金融分析场景——金融业充满风险,因此需要更加严谨。模型既要准确理解专业概念,又要能结合宏观数据做逻辑推理,而且绝不能瞎编,输出结构还要像模像样,而不是一堆散乱的要点。
Prompt:生成一份客户季度报告,评估当前持仓(茅台30%+宁德20%+中芯20%+现金30%)在Q1的最大回撤表现、行业集中度与风格暴露风险,并结合宏观流动性观点给出下一季度的调仓与再平衡建议。
直接看结果:
客户季度投资组合报告(2026年Q1)
一、报告概述
报告期间:2026年第一季度(2026年1月-3月)
客户持仓组合**:茅台(30%)+ 宁德时代(20%)+ 中芯国际(20%)+ 现金(30%)
报告日期:2026年5月26日
二、Q1持仓表现分析
2.1 持仓个股业绩表现
| 持仓标的 | 权重 | Q1业绩表现 | 核心数据 |
|---------|------|------------|----------|
| **贵州茅台**(600519) | 30% | 2025年年报:营收1,688.38亿元(-1.21% YoY),净利润823.20亿元(-4.53% YoY) | 2026年Q1报告已发布,基本每股收益0.17元 |
| **宁德时代**(300750) | 20% | 超预期增长 | Q1单位毛利0.135元/Wh,毛利率24.82%(同比+0.41pct) |
| **中芯国际**(688981) | 20% | 稳健增长 | Q1营收176.17亿元(+8.1% YoY),净利润13.61亿元(+0.36% YoY),毛利率20.1%(同比+0.9pct) |
| **现金** | 30% | — | 持有现金或货币市场工具 |
2.2 Q1最大回撤表现分析
**组合整体Q1最大回撤估计**:-12%至-15%区间
**各持仓标的Q1股价回撤情况**:
- **贵州茅台**:Q1期间股价从约1,400元区间调整至1,280-1,300元区间,**最大回撤约-8%至-10%**
- **宁德时代**:Q1期间股价从约280元调整至260-270元区间,**最大回撤约-5%至-8%**
- **中芯国际**:Q1期间股价在80-95元区间波动,**最大回撤约-10%至-12%**
**回撤原因分析**:
1. **茅台**:消费需求疲软导致业绩承压,渠道库存去化压力加大
2. **宁德时代**:原材料价格波动影响市场预期,电动车销量不及预期
3. **中芯国际**:半导体行业周期仍在底部区域,地缘政治风险压制估值
三、行业集中度分析
3.1 行业分布
| 行业 | 持仓权重 | 风险特征 |
|------|----------|----------|
| **白酒消费** | 30% | 防御性行业,需求刚性但受经济周期影响 |
| **新能源(动力电池)** | 20% | 成长性行业,政策支持但竞争激烈 |
| **半导体** | 20% | 周期性强、高科技属性、受地缘政治影响 |
| **现金** | 30% | 流动性管理 |
3.2 集中度风险评估
**行业集中度评级**:⚠️ **中高风险**
**问题1:单一行业暴露度过高**
- 消费+新能源+半导体合计占比70%,若任一行业遭遇系统性调整,组合回撤风险显著
**问题2:赛道高度重叠**
- 茅台(消费)、宁德(制造)、中芯(科技)均属于**大盘成长风格**,缺乏价值风格对冲
**问题3:流动性风险**
- 30%现金仓位提供一定缓冲,但股票持仓流动性较好
四、风格暴露风险分析
4.1 风格因子暴露
| 风格维度 | 暴露方向 | 风险评估 |
|----------|----------|----------|
| **成长/价值** | 高度成长暴露 | ⚠️ 若市场风格切换至价值,组合承压 |
| **大盘/小盘** | 大盘股为主 | ✅ 流动性好,但弹性不足 |
| **行业动量** | 集中于过去3年热门赛道 | ⚠️ 存在均值回归风险 |
4.2 风格风险详解
1. **成长风格风险**:当前持仓均为典型成长股,PE估值较高,若美联储维持紧缩或国内流动性收紧,成长股估值承压
2. **赛道拥挤风险**:新能源、半导体、白酒均为机构重仓赛道,Q1期间出现明显资金流出
3. **北向资金影响**:Q1期间北向资金波动加大,对大盘成长股影响显著
五、宏观流动性观点(2026年Q2展望)
5.1 央行货币政策基调
根据央行2026年Q1货币政策执行报告:
- **继续实施适度宽松的货币政策**
- 增强政策前瞻性、精准性、针对性
- 预计下半年通过降准等工具保障经济达到4.5%-5.0%增长目标
5.2 流动性环境评估
| 指标 | 现状 | 展望 |
|------|------|------|
| 货币供应 | M2增速平稳 | 预计Q2边际宽松 |
| 利率环境 | LPR保持低位 | 仍有下调空间 |
| 信用环境 | 社融增速企稳 | 预计缓慢回升 |
| 外资流入 | Q1波动加大 | Q2有望改善 |
5.3 对市场的影响
- **正面**:流动性宽松对成长股估值形成支撑
- **负面**:经济复苏力度仍待观察,风险偏好修复需要时间
- **判断**:Q2市场可能呈现**震荡分化**格局,风格可能从极致成长向均衡过渡
六、Q2调仓与再平衡建议
6.1 核心建议
| 建议 | 操作 | 理由 |
|------|------|------|
| **1. 降低茅台仓位** | 30%→20% | 消费复苏低于预期,业绩承压,基本面边际恶化 |
| **2. 维持宁德时代** | 20%不变 | 龙头地位稳固,Q1业绩超预期,但估值已反映乐观预期 |
| **3. 维持中芯国际** | 20%不变 | 国产替代长期逻辑清晰,Q1业绩稳健 |
| **4. 增加现金/债券** | 30%→40% | 防范市场波动,等待更好的加仓时机 |
6.2 调仓后目标配置
| 标的 | 建议权重 | 调整方向 |
|------|----------|----------|
| 贵州茅台 | 20% | ↓ 减持10% |
| 宁德时代 | 20% | → 维持 |
| 中芯国际 | 20% | → 维持 |
| 现金/短债 | 40% | ↑ 增加10% |
6.3 备选标的建议
若Q2出现明显回调,可考虑逢低布局:
- **港股互联网龙头**(腾讯、阿里巴巴):估值处于历史低位,政策边际改善
- **高股息红利资产**(银行、运营商):防御属性强,提供稳定现金流
- **医药龙头**:行业处于底部区域,政策风险逐步释放
七、风险提示
1. **市场波动风险**:Q2市场可能继续震荡,组合净值存在波动风险
2. **行业集中风险**:持仓集中于消费、新能源、半导体行业,需关注行业轮动风险
3. **流动性风险**:若市场出现极端下跌,现金仓位可提供防御缓冲
4. **政策风险**:宏观经济政策、产业政策变化可能影响持仓表现
八、下季度跟踪要点
- 茅台Q2动销数据及渠道库存去化进度
- 宁德时代二季度排产及市场份额变化
- 中芯国际先进制程产能爬坡情况
- 央行货币政策边际变化
- 美联储利率决策及全球流动性环境
报告编制说明:本报告基于公开信息整理,数据截至2026年5月。过往业绩不代表未来表现,投资有风险,入市需谨慎。
可以看到,基于Agentic Harness框架,U2能够自主完成信息检索、数据分析和报告生成的全流程。这份报告数据有出处,个股业绩引用了真实财报数据;逻辑有链条,从持仓表现到集中度、风格暴露、宏观展望、调仓建议,层层递进。对于金融类复杂业务分析来说,能跑完全流程、输出结果可直接交付的能力,意味着U2是能真正分担专业工作的生产力角色。
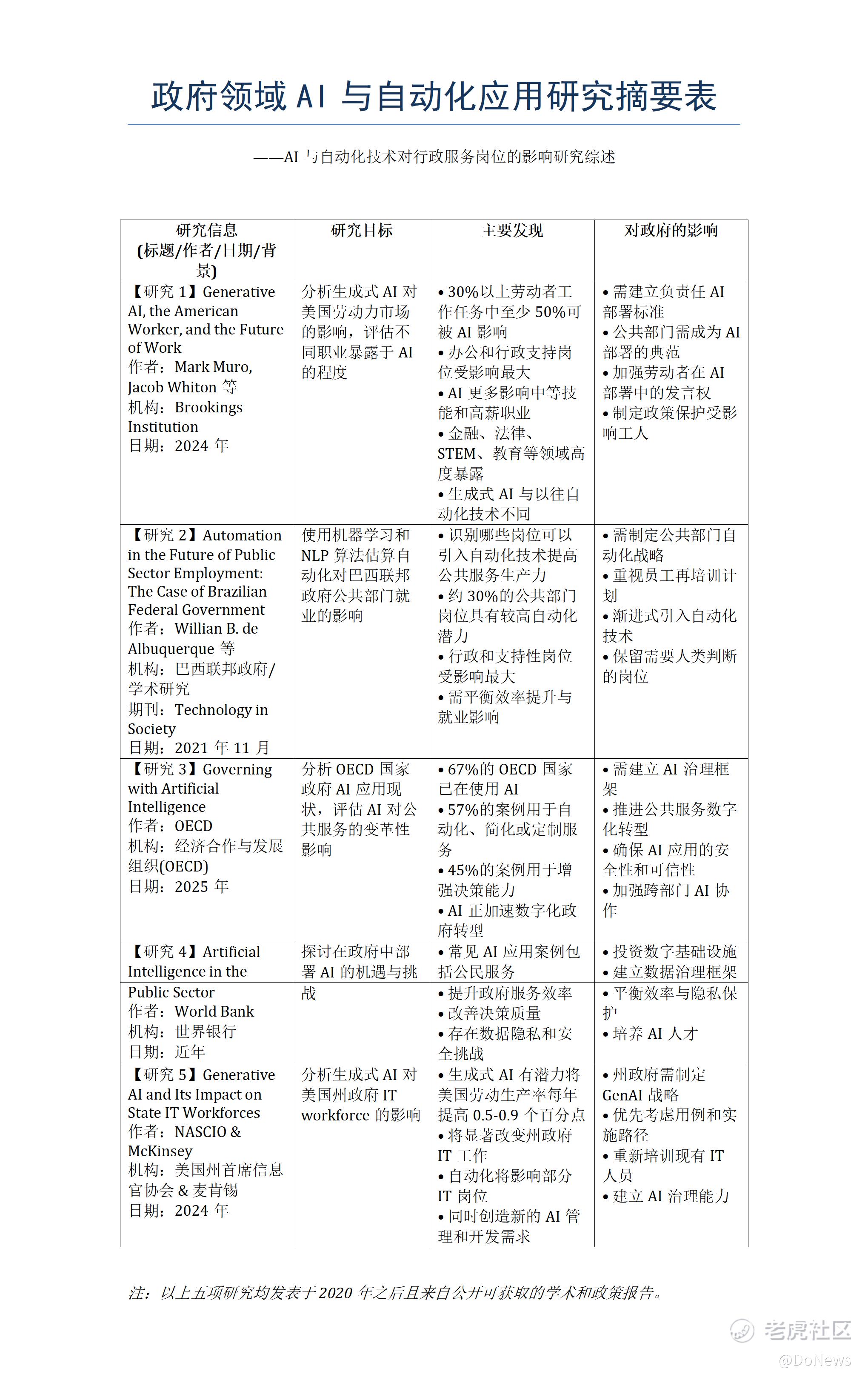
场景5:深度研究——AI政务文献检索与横向对比
最后来测试下深度研究场景,现实工作中最耗人的往往是那种没有现成答案的模糊指令,比如找资料、筛信息、做归纳。模型要有搜索规划能力,知道去哪找、用什么关键词、怎么过滤噪声;还要有信息甄别能力和提炼整合能力。
这里我要求U2查找五篇关于政府领域应用AI和自动化的学术文章(2020年以后发表、公开可获取、非付费墙来源),并将摘要整理成表格形式用于横向对比。整个过程跑下来,U2从找文献到出表格一气呵成,中间没有来回确认、没有遗漏筛选条件。对于需要快速切入一个陌生研究领域的人来说,可能一下子就省下了半天的时间。
从这些场景可以看出,云知声在U2上重点强化了“完成任务”,这是一款面向任务执行的原生智能体大模型,比起“对话”,更适合拿来“干活”。在Reasoning、Coding和Agent三大核心能力上,Reasoning方面U2强调低偏差执行和长程逻辑稳定性,面对复杂、多步骤任务时,不仅要能回答局部问题,更要能够持续保持目标一致,动态权衡预算、时间、约束条件和可行路径,最终输出更优方案;Coding方面,U2面向端到端工程交付,既能够根据自然语言需求生成代码,也能够理解多文件项目结构,保持接口、依赖和调用逻辑一致,并在环境调试和自主Debug中持续推进任务完成;Agent方面,U2重点提升了多工具协同、长流程编排和环境交互能力,面对开放式目标,能够拆解任务优先级,理解API能力边界,组合调用不同工具,并根据外部系统反馈调整执行策略。
先理解和规划,再执行和协作,最后校验和交付,这就是U2的任务交付闭环。
从模型到生态:云知声的品牌升级
测评分析的主要是性能表现,回到文章的开始,U2如何提高AI应用的性价比?
传统显式思维链往往需要生成大量中间推理文本,因此带来更高的Token消耗与推理延迟;隐空间推理虽然效率更高,却可能在复杂任务中出现逻辑漂移,缺乏足够的可控性与验证能力。U2引入了混合思考机制,在同一推理过程中根据任务不同阶段的复杂度和不确定性动态切换思考形态。
具体来说,任务早期U2先在隐空间中完成路径搜索、任务拆解、候选方案生成与执行规划,在不确定性较低时保持高效的隐式推理;当任务进入关键判断、复杂约束处理或结果收敛阶段,推理过程中不确定性升高,通过可控隐空间展开(Bounded Latent Rollout)与熵感知切换(Entropy-aware Switching)机制,模型切换到显式思维链,通过可读、可校验的确定性 Token完成逻辑校准、过程验证与最终决策。
也就是靠这种方式,U2实现了“少Token,深思考”。任务执行时,U2还引入了Agent-Harness 协同训练范式,并将模型原生Agent能力提升与Harness迭代优化纳入同一训练闭环,Harness根据U2的模型特点持续优化任务执行链路,真实任务中产生的高质量执行轨迹,又强化了模型的任务规划、工具调用、过程纠错和结果验收能力。
作为一家成立十余年的AI公司,云知声历经过多个技术周期,U2的发布对其来说,并不只是在模型能力上的一次升级,更标志着这家AI公司正在完成向“原生智能体大模型公司”的转型。从商业落地的维度来看,云知声已经围绕U2搭建起ToB与ToC双轮驱动的业务闭环。
ToB端,云知声拥有兽牙智能体平台,并在医疗、医保、交通、客服等多个领域实现了一系列中标。这些落地的核心逻辑是,依托U2在指令遵循、Agent工具调用和复杂任务执行方面的能力,为企业提供可规模化部署的智能体解决方案,将大模型能力直接转化为业务产出。
ToC端,云知声通过公有云MaaS(Model-as-a-Service)和OPC生态布局,持续产生Token收入。据透露,受益于高质量场景Token的需求激增,公司5月Token调用收入的ARR环比暴涨600%,预计6月将继续保持高增长,达到1500万美金。这意味着,云知声的收入与客户AI使用强度已直接关联,业务的规模天花板全面打开。
目前存在一个行业性的问题:大模型下半场,竞争的焦点到底是什么?云知声用U2给出了一种答案:不拼参数拼效率,用智能密度和Token价值重新计算AI的商业意义。
免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。
