
AI 硬件供应链全图谱:市场追逐的热点到底是什么?一文看懂【上】
最近跟朋友交流,他们都在跟我抱怨,现在市场热点太多了,每天都在像无头苍蝇一样乱碰。所以今天整理出了一整条完整的链路,文章比较长,我会分成上下发出来。
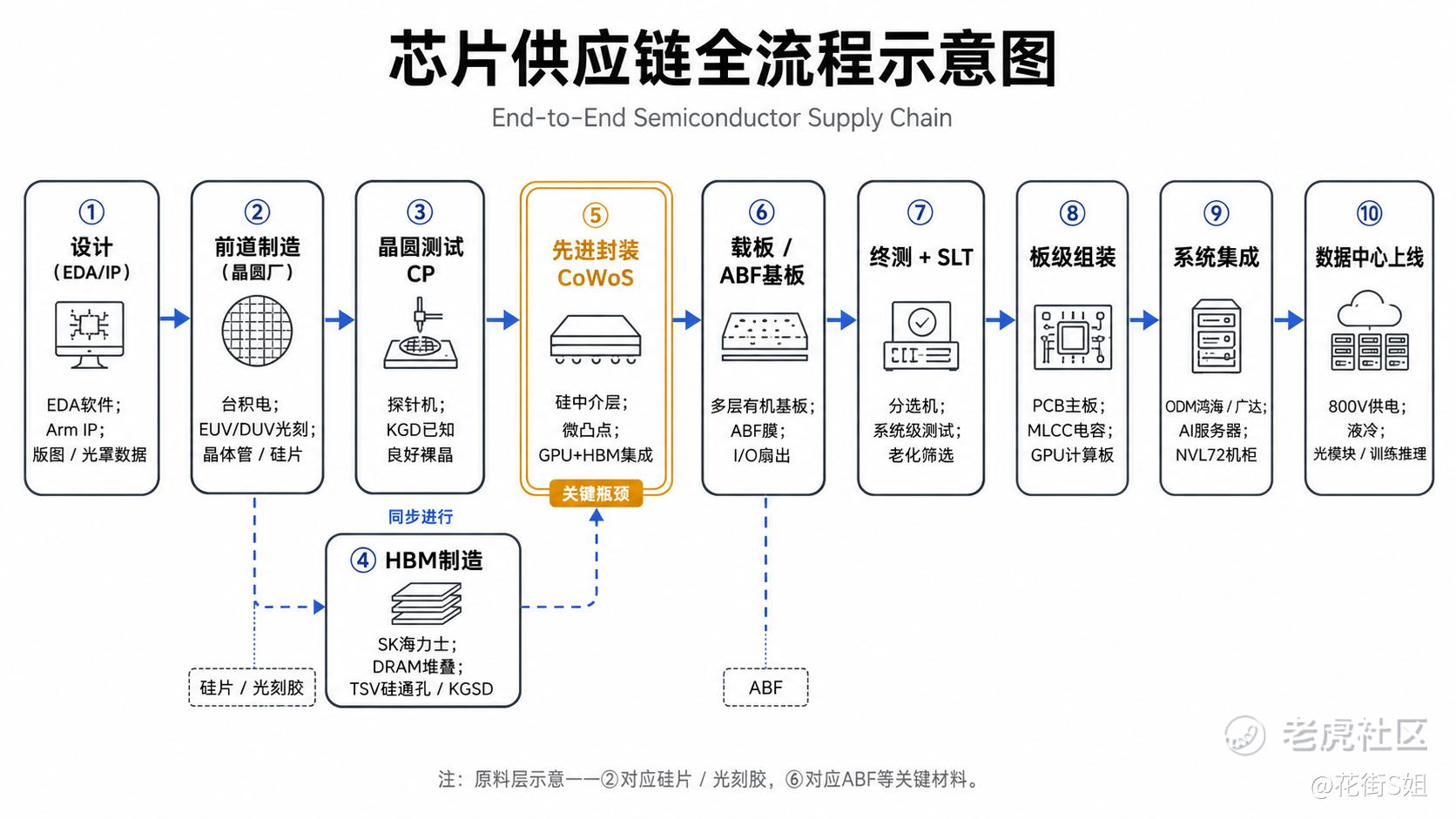
理解这条链,最好的方式是跟着一颗芯片走一遍。它的”一生”大致是这样:
① 设计(图纸):工程师先在 EDA 软件里画出电路、做仿真验证,结合外购的 IP(如 Arm 的 CPU 指令集),最终产出一套”版图”和光罩(掩膜)数据。这一步不碰任何硬件,产出的是”怎么造”的指令。
② 前道制造(把图纸变成晶体管):晶圆厂(台积电)拿一片高纯度硅片当画布,用光刻机(EUV/DUV)配合光刻胶、刻蚀、沉积、离子注入等上百道工序,一层一层把数百亿个晶体管”印”上去,最终在一整片晶圆上做出几十上百颗裸晶(die)。投入的原料是硅片、光刻胶、电子特气、CMP 抛光液和光罩。
③ 晶圆测试 / CP(先验货):晶圆还没切开,就要用探针机+探针卡扎到每颗 die 上做电性测试,挑出好的。业内叫”已知良好裸晶”(KGD)。为什么这么早就测?因为后面的封装极贵,绝不能把一颗坏 die 封进价值数万美元的成品里。
④ 存储的平行支线(HBM):与此同时,DRAM 厂(SK 海力士等)把多片 DRAM 裸晶垂直堆成 8/12/16 层,用 TSV(硅通孔)上下打通,做成 HBM 高带宽存储;HBM 也要测,确保已知良好堆叠(KGSD)。
⑤ 先进封装 / CoWoS(把 GPU 和 HBM 拼到一起):这是关键一步。把 GPU 裸晶和好几颗 HBM 一起,通过微凸点贴到一块”硅中介层”上。中介层是一块带超细线路和 TSV 的硅片,提供 GPU 与 HBM 之间极短、极密的互连,这直接决定了带宽。这个组合体再贴到下面的载板上。这套工艺就叫 CoWoS(Chip-on-Wafer-on-Substrate)。
⑥ 载板 / ABF(翻译成主板能用的样子):封装好的芯片有成百上千个引脚,间距极细,没法直接焊到普通电路板上。载板就是一块多层有机基板,把这些密集的 I/O 一层层”扇出”、转接到主板能接受的间距,同时承担供电和散热路径。它的核心绝缘材料就是 ABF 膜。
⑦ 终测 + SLT(成品再验一遍):封装好的成品用分选机送进测试机做终测(FT);复杂的 AI 大芯片还要做系统级测试(SLT),在接近真实负载下跑,并经过老化筛掉早夭品。
⑧ 板级组装:合格的芯片焊到 PCB 主板上,配上成千上万颗 MLCC(陶瓷电容)来稳定供电,做成 GPU 计算模组/计算板。
⑨ 系统集成(攒成服务器/机柜):计算板 + CPU + 网络交换芯片 + 光模块/铜缆 + 电源 + 散热,由 ODM(鸿海、广达等)组装成 AI 服务器,再叠成整机柜(如英伟达 GB300 NVL72)。
⑩ 数据中心(通电、组网、跑起来):机柜进数据中心,接上电力(800V 供电+液冷散热),用光模块/OCS 把成千上万张 GPU 组成一张网,开始跑训练和推理,吐出 token。
所以整个流转的过程是硅片 → 前道制造(裸晶) → 晶圆测试(KGD) →〔HBM 支线〕→ CoWoS 封装(GPU+HBM+中介层) → ABF 载板 → 终测/SLT → 板级组装(+MLCC) → 服务器/机柜(ODM) → 数据中心(供电+散热+组网)
芯片造好之后,运行时的”数据流”分三个尺度,正好对应三类互连:
GPU ↔ HBM(封装内,毫米级):靠硅中介层,这是先进封装要解决的;
GPU ↔ GPU(机柜内,米级):靠 NVLink 铜背板和高速铜缆,这是铜互连要解决的;
机柜 ↔ 机柜(数据中心内,几十到几百米):靠光纤,这是光互连要解决的。
距离越远,铜越扛不住、越要上光;距离越近,铜越省电越可靠。
整条供应链里封装、铜缆、光模块三个环节的存在与博弈,本质上都是在为”不同尺度的数据搬运”服务。
逐块拆解:每片拼图的壁垒与价值
下面的文章会围绕这 5个支点展开:
设计:英伟达约 80% 训练加速器份额、约 71% 毛利率、CUDA 生态护城河,Vera Rubin 2026 下半年量产;定制 ASIC(博通+迈威尔合计约 95% 协同设计份额)增速远超 GPU;
代工:台积电约 67% 代工营收、制造约 92% 先进 AI 芯片,营业利润率约 58%;HBM:SK 海力士/三星/美光三足鼎立,2026 售罄、排单到 2027–2028;
设备:ASML 独家 EUV、毛利率约 53%;
软件:新思/楷登/西门子 EDA 垄断约四分之三市场。
板块 A:材料、硅片与 EDA(造芯片的原料和图纸,成熟寡头)
这是最上游的原料 + 图纸。
硅片是芯片的物理衬底,玩家有信越化学、SUMCO(日)+ 环球晶圆(台)+ Siltronic(德)的三家寡头;
光刻胶在曝光时充当感光成像介质,由 JSR、东京应化、信越、富士胶片、住友化学等日企掌握约九成 EUV 胶;
电子特气、CMP 抛光液服务于刻蚀、清洗、平坦化等工艺;
EDA 软件是设计芯片的工具,是新思、楷登、西门子三家天下。另外,Arm 提供 CPU 指令集 IP。
这些是结构稳定的日本/美国垄断带,壁垒在纯度与认证周期,国产替代多年只在成熟节点缓慢渗透。属于”稳”而非”快”的环节。
板块 B:封装与载板(全链最卡)
这一板块要解决两件事:第一,把 GPU 和 HBM 以最短距离、最高密度连起来,这决定了”喂数据”的带宽;第二,把脆弱、引脚密集的硅芯片”翻译”成一个能焊到主板、能供电、能散热的成品。
它分四层:
中介层与 CoWoS(先进封装本体)
CoWoS 的字面意思是”芯片-在晶圆-在基板上”。它先把 GPU 和多颗 HBM 用微凸点贴到一块硅中介层上,中介层是带 TSV 和超细布线的硅片,提供 die 之间的超密互连;再把这个整体贴到载板。
工艺有几种分支:CoWoS-S 用纯硅中介层(成熟但尺寸受限);CoWoS-L 用”重布线层(RDL)+ 局部硅桥(LSI)”拼接出更大的封装面积,英伟达 Blackwell 即采用此路线,但要应对大面板的”翘曲”难题;CoWoS-R 用 RDL 中介层。更先进的 SoIC 是把多颗 die 垂直 3D 堆叠(铜-铜直接键合)。(这些路径我之前专门写过)
台积电把 CoWoS 月产能从 2023 年底约 1.3 万片扩到 2026 年底约 12–13 万片(近十倍)仍售罄,英伟达一家预订了一半以上,台积电把部分工序外包给封测厂日月光(ASE)和安靠(Amkor)。
载板(IC/ABF substrate)
把封装好的芯片几千个密集 I/O 扇出、转接到 PCB 能焊接的间距,并承载供电。行业高度集中,前五约占 74%:欣兴(Unimicron)、揖斐电(Ibiden,历史上独供英伟达 GPU 载板)、新光电气(Shinko)、南亚电路板、奥地利 AT&S,再加景硕(Kinsus)、三星电机。台湾约占三成产能。
2026 年载板市场约 161 亿美元,高端 ABF 载板已售罄、龙头稼动率约九成,机构预计 2027 年缺口超 20%;载板扩产周期长达 2.5–3 年(比 PCB 还长),大规模新产能要等到 2028–2029 年,价格在 2026 年以每季度约 3%–7% 的节奏温和上行。
ABF 膜(独家卡点)
ABF 是味之素堆叠膜(Ajinomoto Build-up Film)的缩写,这层绝缘树脂是高端载板的关键材料,由日本味之素一家独占,一家做味精的公司垄断了全球高端芯片载板的命脉材料,该业务营业利润率高达约 55%,计划 2030 年前增产约 50%。
玻纤布(T-glass,卡脖子的卡脖子)
载板内部要用特种玻纤布做骨架增强,约七成 T-glass 流向 ABF 载板,主要供应商是日本日东纺(Nittobo)、台玻(TGI)和中国大陆玻纤厂商。
机构判断 T-glass 短缺持续到 2027 年、缺口在 2026 年见顶。再往上的覆铜板(CCL)、铜箔、玻纤纱也都在涨价、交期拉长。
玻璃基板(下一代基板/中介层)
这是 2026 年从研发跨入试产+客户认证的暗马。
它的逻辑是用玻璃芯替代现在的有机(ABF)芯做载板,或者用玻璃中介层替代昂贵且尺寸受限的硅中介层。
玻璃的优势是平整度、热稳定性、尺寸稳定性更好,可以做成更大的矩形面板(提升面积利用率)、支持更高层数和更大封装,并用 TGV(玻璃通孔)替代 TSV。难点是玻璃易裂,以及检测困难。玻璃透明反光,让传统的自动光学检测(AOI)几乎失效,反而催生新的检测设备需求。
玩家正在快速卡位:
Absolics(SKC 子公司)在美国乔治亚州建成全球首座玻璃基板量产厂,已向 AMD 送样进入认证,目标年底实现全球首个商用量产,母公司 SKC 把超 6000 亿韩元注入它;
英特尔投入超 10 亿美元,2026 年初展示了 EMIB + 玻璃芯样品(号称无微裂),目标 2030 年标准化;
三星电机在世宗试产、2027 年后量产,依托其显示面板的玻璃工艺积累;
台积电把面板级封装命名为 CoPoS(Chip-on-Panel-on-Substrate,310×310mm),试产线 2026 年落地、量产看 2028–2029,并与康宁台湾厂合作;
日本 DNP、凸版和中国 BOE 也在推进。上游材料是康宁、AGC、NEG,TGV 激光设备是 LPKF、Disco。
玻璃基板很特殊,它既是对 ABF 载板厂的长期替代威胁,又是台积电/英特尔争夺的下一代护城河。
整个封装板块整体呈一层卡一层:CoWoS 卡产能、载板卡产能与扩产周期、ABF 膜与玻纤布卡材料;受益面从台积电一路延伸到日月光/安靠、欣兴/揖斐电/南电,乃至味之素、日东纺这种卖味精、卖玻璃布的隐形冠军。
板块 C:存储与被动元件(HBM 上游/测试与 MLCC)
HBM 的制造与上游
HBM 是把多片 DRAM 裸晶垂直堆叠(8/12/16 层),用 TSV(硅通孔)把上下层打通,底部放一颗逻辑基底 die 负责与 GPU 通信。
最难的工序是堆叠键合:SK 海力士用 MR-MUF(批量回流模塑底填),良率和散热占优,是它领先的关键;三星用 TC-NCF(热压非导电膜);到 HBM4 的 16 层,行业开始转向混合键合(hybrid bonding,无凸点的铜-铜直接键合)以堆得更高更薄。
相关设备由 BESI、ASMPT、韩国 Hanmi 等供应。HBM 测试则是新瓶颈:必须保证”已知良好堆叠”(KGSD),任何一层坏了整堆报废,还要测极高速接口,这把测试难度和成本推上了新台阶(见后文)。
MLCC / 陶瓷电容(即陶瓷薄膜)
MLCC 是叠层陶瓷电容,贴在 GPU 封装和计算板上做去耦和储能。GPU 在做矩阵运算时电流会瞬间剧烈波动,MLCC 就近储存并释放电荷、平滑电压、滤除噪声。没有它,供电电压会瞬间塌陷、芯片直接出错。
AI GPU 功耗高、工作电压低(不到 1V)、电流瞬变剧烈、供电轨道多,因此一块 GB200 计算板要用上万颗 MLCC,而且要求高容值、低寄生电感(低 ESL)、小尺寸(0201/01005)、耐高温车规级。
玩家是日系主导高端:村田(Murata,全球第一)、太阳诱电、TDK,加上韩国三星电机、台湾国巨与华新科。英伟达 800VDC拉动的是量增 + 规格升级双击,逻辑清晰,属已被充分认知的环节。
(3)连接器与高速铜缆(铜互连)(这部分就简单过一下)
在机柜内部和机架内(米级短距离),用铜缆传数据比光更省电、更便宜、更可靠,所以英伟达 NVLink 的机柜内 scale-up 大量用铜背板和高速铜缆(DAC/ACC)+连接器。这就是前面说的”铜与光分工”里铜的一侧。
玩家有安费诺(Amphenol,AI 连接器最大赢家)、泰科电子(TE)、立讯精密。
其实有的环节还有很多细分,但是篇幅原因,我就不在这里一一展开。下一篇文章讲光互连与光模块、散热与液冷、设备厂等几个环节。
$特斯拉(TSLA)$ ROUNDHILL GENERATIVE AI & TECHNOLOGY ETF(CHAT) $通用人工智能 ETF-AGIX(AGIX)$
免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。
