
Marvell 单日暴涨 30%:AI 算力“卖铲人”的下一棒在哪?
英伟达不是终点,网络和互联才是下一段最拥挤的赛道
Marvell这次暴涨,最值得注意的不是又一只半导体股疯了,而是市场开始认真定价一件事:AI资本开支正在从买 GPU扩散到买网络、买互联、买定制ASIC。6月2日,Marvell股价盘中一度飙涨超过30%,收盘附近的市场资本化也被推到约2544亿美元一线;更关键的是,这波拉升并不是孤立发生,半导体板块当天整体也明显走强,PHLX半导体指数大涨 5.9%。
这轮上涨的点火器,是黄仁勋在台北Computex期间公开称Marvell可能成为下一个万亿美元公司。但这句话的分量,不只是情绪加持,而是带着资本与业务绑定的含金量:Nvidia今年早些时候已经向Marvell投资了20亿美元,双方合作方向明确指向定制AI芯片、网络设备和互联基础设施。换句话说,黄仁勋不是在给同行站台,而是在替自己生态里的关键环节站台。
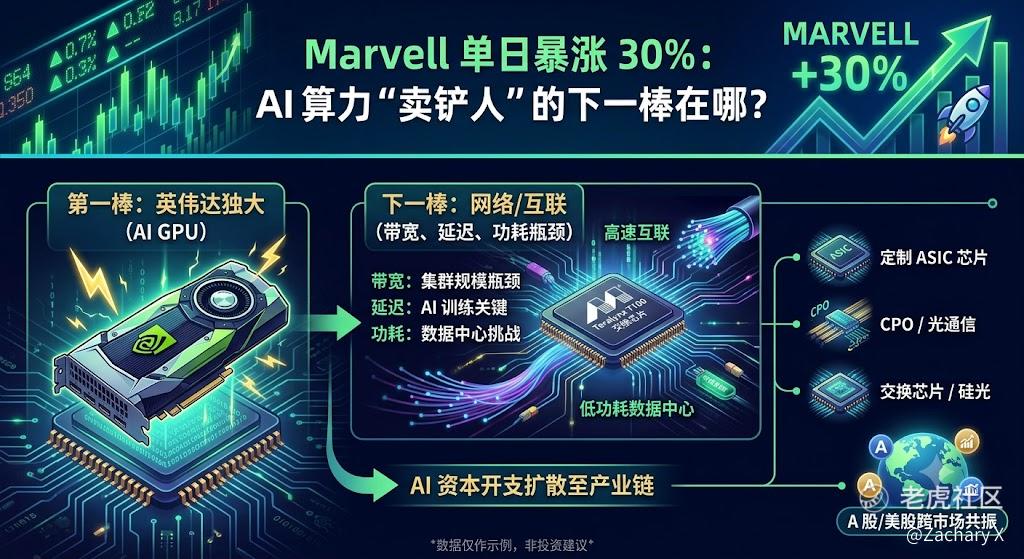
为什么这件事重要? 很多人还在用AI就是GPU的故事来理解行情,但真正的大模型集群,一旦规模上去,最先卡住的往往不是算力芯片本身,而是带宽、延迟、功耗和网络拓扑。Marvell自己最新发布的Teralynx T100,正是把这个问题摆到台面上:它是业内首个102.4 Tbps交换芯片,官方强调其面向AI训练和推理,目标就是用更低功耗、更低延迟去缓解大规模GPU集群的网络瓶颈。Marvell还明确提到,随着GPU/XPU机柜功耗逼近120KW,网络和交换组件已经占到机柜总功耗的约 15%–25%,低功耗交换芯片成了战略刚需。
这就是Marvell这波暴涨背后的核心逻辑:它不是来和英伟达正面抢算力中心的,而是去吃算力周边的确定性需求。 当GPU集群继续扩张,客户一定会买更强的交换芯片、更高带宽的互联、更低功耗的网络架构;而Marvell恰好卡在这个位置上。公司自己也已经把未来的成长路径说得很直白:其custom chip业务预计到2029财年会超过100亿美元收入。
这也是为什么,市场会把Marvell视为AI 卖铲人里的下一棒。第一棒是GPU,第二棒往往是网络互联,第三棒才可能延伸到光模块、硅光、交换芯片、电源、液冷这些基础设施配套。这个链条并不是我凭空想象出来的,而是Marvell官方发布对产业趋势的共同指向:AI数据中心正在加大对定制芯片和互联技术的投入,以降低对单一GPU供应链的依赖。
从交易角度看,Marvell 的暴涨还有一个更重要的信号:AI赛道的资金已经从英伟达独大开始向产业链扩散切换。 Marvell预计其AI数据中心业务会继续增长,市场也在重新评估它在光互联、定制 ASIC 和交换芯片中的位置。换句话说,资金不再只盯着谁是最大GPU公司,而是在问:谁能在下一轮 AI 基建里,持续吃到每一层预算?
如果把这条逻辑映射到 A 股,我更愿意把它理解成一种跨市场共振的产业链估值重排: 不是简单地看谁能复制 Marvell,而是看谁处在AI机房扩容中最先受益、最不容易被替代、最能把带宽和功耗问题货币化的位置。按这个框架去看,CPO、光模块、交换芯片、液冷和电源链条,都可能在同一轮叙事里轮流被资金点名。这个判断是基于Marvell的官方产品逻辑和Nvidia对互联生态的资本绑定做出的推演。
但也要说清楚:Marvell不是无风险的白送题。 这类股票的定价,本质上是对AI基建CAPEX持续扩张的押注;一旦云厂商capex放缓、订单节奏变慢、或者市场开始担心AI投资回报率,估值就会迅速回撤。Marvell过去也曾因为网络设备需求疲弱而遭遇剧烈波动,这说明它的弹性大,波动也大。
所以我对这轮行情的结论很简单:
Marvell的暴涨,不只是英伟达的一个朋友涨了,而是市场第一次如此明确地在交易:AI 资本开支的下一段增量,不在GPU本身,而在GPU集群背后的网络和互联。 如果说英伟达定义了算力时代,那么Marvell这种公司正在定义算力如何真正跑起来。
下一棒,大概率不是更大的 GPU, 而是更快的网络、更低的延迟、更高效的互联,以及更适配AI集群的基础设施链条。
免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。
- 财务自由之路666·06-03今天美股有什么利好的公司点赞举报