
CSIAM论坛 | 明略科技吴明辉:Scaling Law的缺失维度,横向扩展如何重塑企业智能
5月23日~5月24日,中国工业与应用数学学会(以下简称学会或CSIAM)第六届“数学促进企业创新发展论坛”在湖北武汉举行。本次论坛旨在搭建数学家与产业界之间的高效对话平台,深入探讨数学如何赋能企业技术创新,加速双方的知识共享与技术融合,解决关键领域的“卡脖子”难题。来自国内多所高校、科研院所及产业界的200余名专家学者、企业代表、学生代表参会,围绕数智时代的产学研深度融合进行了学术交流。

大会报告环节,明略科技(2718.HK)创始人、CEO兼CTO吴明辉与武汉大学李德仁院士、姜卫平院士,以及上海交通大学徐振礼教授同台,分享前沿领域最新研究进展与应用成果,为与会者带来了多视角、跨学科的学术启发。

吴明辉在《Scaling Law的缺失维度——横向扩展如何重塑企业智能》演讲中指出,"当前AI行业的注意力集中在Scaling Up:更大的参数、更多的数据、更强的算力。但回顾计算基础设施领域的历史,从IBM大型机到云计算,横向扩展最终胜出。AI领域同样存在这个可能:多个智能体协作产生的集体智慧,未来将超越单一大模型。"
Scaling Up的瓶颈:公开数据接近耗尽
过去几年大模型的飞速发展得益于Scaling Law。模型参数越大、训练数据越多、算力投入越高,性能就越好。OpenAI在2020年系统论证了这一幂律关系,DeepMind在2022年进一步指出参数规模与数据量必须同步增长。直到最近,DeepSeek等开源模型在推理时的Scaling进一步延展了这条曲线。
但所有工作的本质是同一件事:把一个集中化的模型做得越来越大。而做大的前提是持续喂入更多数据。
全球公开互联网上可获取的数据已接近耗尽——行业称之为"数据墙"(Data Wall)。当Data不能继续增长,算力和参数的单方面增长将失去边际效益。
真正的数据壁垒在哪?
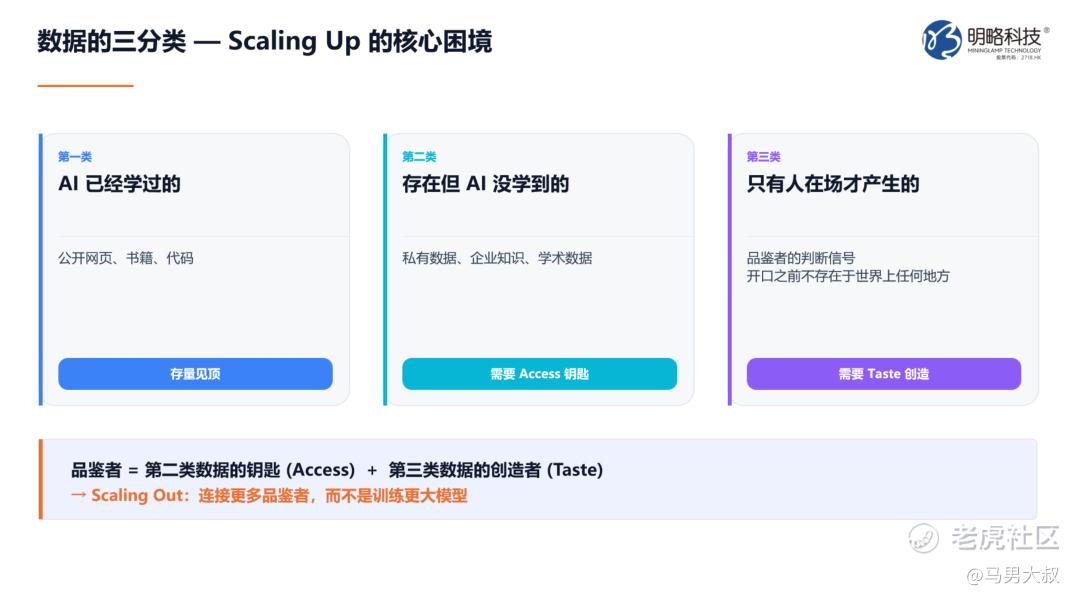
在吴明辉看来,按可获取性和属性,数据可以分为三类:
第一类:已被基础大模型训练过的公开互联网数据——这部分基本被用尽。
第二类:存在于企业和机构信息系统中,已被数字化但因权限原因不能被集中训练的私有数据。企业财务数据、个人健康数据、工厂设备数据、各类分布式系统中的数据都属于此类。问题不仅是"能不能连",更是数据拥有者"愿不愿意连"。
第三类:尚未被数字化的数据。它停留在人脑中,或存在于尚未探索的世界中,需要人与AI互动才能产生。
吴明辉将第三类数据称为"品鉴数据":"这是人类拓展世界所产生的新Context。第二类和第三类数据,是今天不同行业、不同科学家、不同企业真正做创新的人,守住自己存在的核心部分。"
Scaling Out:AI的另一个扩展维度
Scaling Up和Scaling Out是分布式系统的经典概念。前者是把单台机器做大,后者是把多台小机器连成网络。从IBM大型机到云计算,计算基础设施领域的演进已经验证了横向扩展的可行性。吴明辉认为,AI领域存在同样的机会。
明略科技的技术路线正是沿着这条逻辑展开:不追求训练一个超大模型,而是让多个可私有化部署的开源模型组成智能体网络,通过MOA(Mixture of Agents)架构展开协作。
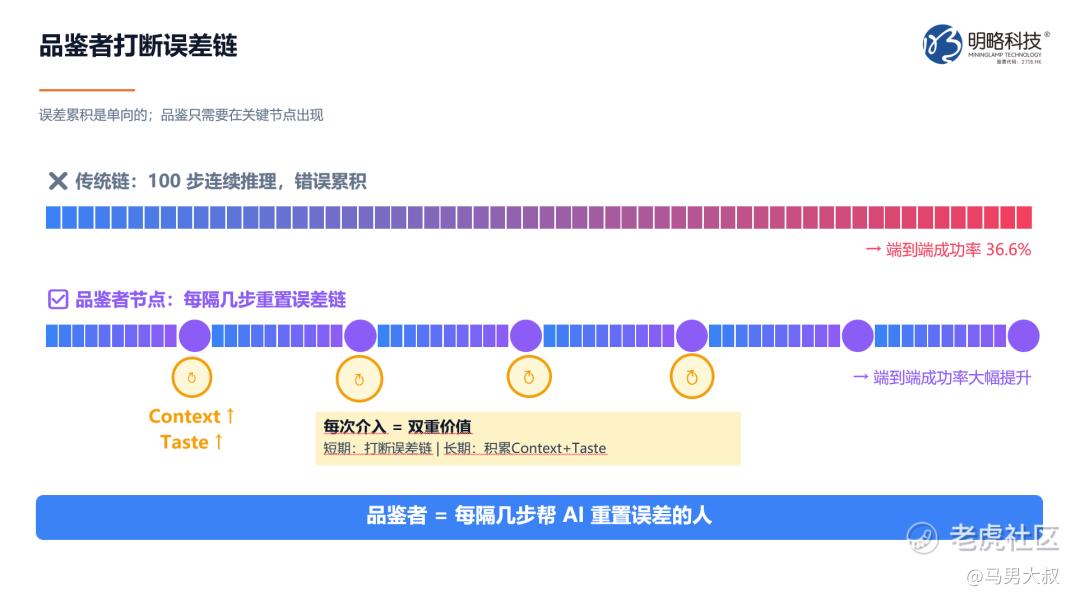
为什么不依赖单一强模型完成所有任务?一个现实挑战是长程任务的精度衰减。
数学上,如果单步准确率为99%,连续执行100步后总准确率仅剩约36.6%(0.99¹⁰⁰≈0.366);即使单步达到99.9%,100步总准确率也只有约90%。在关键任务(Mission Critical)场景中,这远远不够。
多智能体协作提供了另一种解法:不要求单个模型一次做对100步,而是多个智能体各做5-10步,人在关键节点介入纠偏并补充新的Context。
吴明辉表示:"今天,DeepSeek V4等开源模型已经具有极强的能力。多个这样的模型在一起协作,将形成集体智慧的涌现。就像我们现代智人靠更强的语言能力和协作能力胜过脑容量更大的尼安德特人一样。"
围绕这一技术路线,明略科技打造了开源Agent协作网络平台———Octo(Open Context Taste Orchestration)。其中,Open是开源开放,数据归你所有;Context涵盖线上线下各类信息;Taste强调人的判断权:80%-90%的执行工作Agent都可以做,但决策标准由人来定,不同的人有不同的品鉴标准;Orchestration是多Agent的协同编排,人和Agent、Agent和Agent在同一网络中协作,形成集体智慧的涌现。
目前,明略科技内部已运行2900余个智能体,每天在协作中产生大量数据。这条路线还带来三个关键优势:数据主权(私有化部署,数据不出域)、可审计(开源白盒),以及人在关键决策节点的不可替代性。

持续学习:让AI越来越懂你
多智能体架构还解决了一个根本性问题:持续学习。
吴明辉指出,当前大模型存在一个类似"顺行性失忆症"的局限,训练截止之后的知识无法自主习得,只能不断追加算力缩短版本迭代周期,但模型仍不可能知道每位研究者当前正在探索的课题。
明略科技的解法是在智能体层面实现持续学习:每个Agent通过Memory机制持续积累用户交互数据,将关键信息沉淀到长期记忆中,与私有化部署的小模型结合。用得越久,Agent越懂用户,不靠改变模型参数,靠外化的知识积累。
基于Octo的Agent协作网络,明略科技针对科研写作场景推出了可私有化部署的实时协作LaTeX编辑工具——CoCraft。研究者可以带着自己的Agent协作写论文,选中文本、说出意图,Agent生成修改提案并以差异高亮展示;一键审稿,问题标注到行列。所有改动以提案形式呈现,人做最终决定。
吴明辉指出,真正的学术突破往往诞生于多位研究者独立探索、彼此激发的过程中,集体智慧的力量远大于任何单一大脑。AI的发展同样如此。人与AI如何在协作中共同进步、Scaling Up与Scaling Out之间如何实现最优资源分配,这些问题背后都蕴含着深刻的数学规律,也是明略科技当下正在攻克的核心课题,未来明略科技愿与各界展开深度共创、合作,助力更多企业与组织向AI Native转型。
关于数学促进企业创新发展论坛
数学促进企业创新发展论坛由CSIAM于2020年发起创办,至今已成功举办六届。论坛紧扣“数学赋能·创新驱动”的学术主线,重点聚焦数学成果的转化落地以及面向国家战略需求的关键技术攻关,已成为连接数学界与产业界的重要桥梁。
关于明略科技
明略科技(2718.HK),成立于2006年,中国领先的具备自研模型能力的Agentic Service企业。2025年作为"全球Agentic AI第一股"登陆港交所。曾两度斩获吴文俊人工智能科学技术奖,多次入选Gartner、IDC相关报告,拥有2400余项技术专利及500余项软件著作权。
近年来,明略科技在Agentic AI领域持续突破:2024年,自研超图多模态大模型(HMLLM)技术成果斩获全球顶会 ACMMM 2024 最佳论文提名;2025年,全面推出DeepMiner 专有大模型产品线,其中VLA模型Mano登顶Mind2Web、OSWorld全球双榜SOTA;2026年,开源端侧 GUI-VLA 智能体模型 Mano-P,登顶OSWorld,ScreenSpot,MMBench等9个榜单,其中OSWorld专用模型榜单排名第一名;开源Apple Silicon推理SDK Cider,端侧推理提速最高约1.9倍;开源 Agent 协作平台 Octo,打造IOA时代Agent协同网络,并推出首款AI Native录音硬件Octic,将 AI Agent 能力从平台延伸至硬件,构建Agentic AI“模型-平台-硬件”闭环。
依托20年技术积累,明略科技已服务135家财富世界500强、约2100家品牌客户及超24万家企业用户,覆盖零售、消费品、汽车、3C等行业。
免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。
