
智谱发布GLM-5.1高速版API,刷新全球大模型API速度纪录
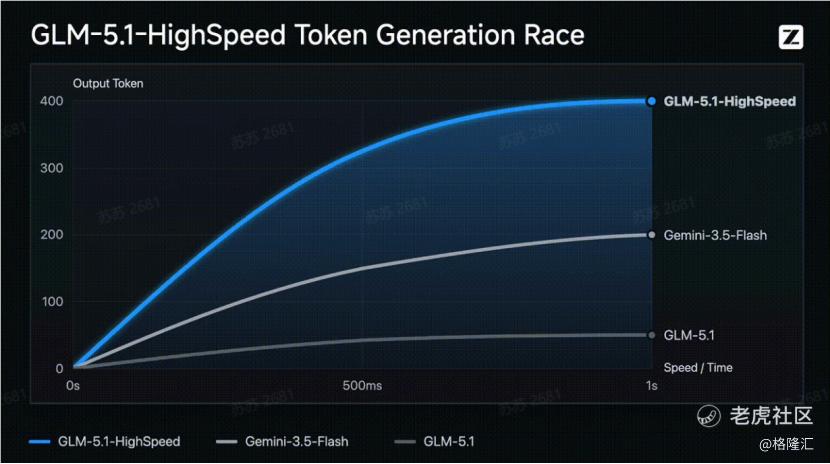
智谱近日推出GLM-5.1高速版API“GLM-5.1-highspeed”,其模型输出速度达到400 tokens/s,刷新了当前全球大模型厂商API的速度上限。 $智谱(02513)$
长期以来,高速模型几乎总是轻量级模型,但GLM-5.1高速版打破了这一行业惯例。它首次在国产大模型中,将旗舰级能力与极致低延迟同时带入生产环境,用户无需再为响应速度牺牲模型质量。
实测显示,在AI编程场景中,写代码仿佛开启了10倍速,模型能够一边理解工程上下文,一边持续生成代码与修改方案;在3D游戏中,玩家控制一个角色在3D地图里移动并输入文字,模型会根据输入的文字瞬时建模,场景实时改变,此前因延迟而无法实现的全新产品形态,开始真正具备落地可能;在交互界面上,在用户提出需求的那一刻,模型可以即时生成恰好匹配该需求的工具与交互,甚至可以做出意图判断。
实现这一速度的核心是TileRT高性能推理引擎。该引擎由智谱GLM团队与TileRT团队联合打造,在推理引擎、调度系统与底层基础设施三个层面进行了系统级优化。其设计思路是彻底抛弃Runtime层的动态调度,在编译期(AOT)将整个计算图静态编排为一个常驻GPU的persistent Engine Kernel。
目前,GLM-5.1高速版适用于AI编程、实时交互、商业决策、实时语音等速度敏感场景,并通过智谱MaaS平台向部分企业客户开放。
免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。
点赞
举报
登录后可参与评论

暂无评论