
梁文锋终于低头,DeepSeek首轮融资曝光
这两天,投资圈彻底炸了。
有知情人士爆料,AI明星公司DeepSeek正式启动成立以来的首次外部融资——目标估值不低于100亿美元,计划募集至少3亿美元资金。
而众所周知,就在一年前梁文锋还明确拒绝过VC投资,并对外表示“DeepSeek暂无融资计划”。
当时,有知名投资者找了三拨人想约见,被拒绝;甚至与DeepSeek北京办公室同楼办公的百度风投也没能投进去。
那个曾经把所有投资人挡在门外的梁文锋,为什么突然要钱了?

“从不融资”已是过去
消息一出,讨论立刻分成了两派。
一种说,完了,连DeepSeek都顶不住AI烧钱的压力;另一种说,AI圈要变天了,梁文锋这是要憋个大的。
但如果你只看到“缺钱”两个字,就把梁文锋和这件事看小了。

图源:知乎
据悉,2023年7月,当DeepSeek正式成立之时,梁文锋从第一天就给这家公司划了一条清晰的红线:不接受外部融资,不稀释股权,不被任何人的商业化时间表绑架。
他确实有这个底气。梁文锋是幻方量化的创始人,而幻方是国内顶级的量化对冲基金,管理规模超700亿元,2025年平均收益率高达56.6%。
早在2019年,他就花2亿元自研了深度学习训练平台萤火一号,两年后又砸10亿元建萤火二号,大批采购英伟达A100,把幻方做成了国内屈指可数的万卡集群公司。
有量化基金从业者估算,仅2025年一年,幻方就为梁文锋带来了超过7亿美元的收入。
有钱、有卡、有人,这就是DeepSeek长期拒绝融资的底气。梁文锋说得也很直白:VC都是帮LP管钱,都得赚钱,所以就谈不到一块去。
然而,在过去一年里,这个防火墙似乎被逐渐击穿了。
当下,AI大模型的竞赛,已经到了决胜期或决胜期前夜。
3月31日,OpenAI刚以8520亿美元的估值完成了1220亿美元的融资。Anthropic在2月以3800亿美元估值完成300亿美元融资。
国内同样在加速,智谱AI已于1月登陆港股,IPO前完成8轮融资、累计募资超83亿元。月之暗面Kimi更是在短短数月内先后完成多轮融资,估值已突破100亿美元。
当身边的竞品都在用市场化手段绑定人才、储备算力,梁文锋还能坚持多久?

图源:X
半导体研究机构SemiAnalysis曾估算,DeepSeek的服务器总资本支出接近16亿美元,其中9亿多直接和运行计算集群相关。而越往顶尖走,每往前追一步,边际成本就越高。
从15秒跑到13秒,多练练就行;但从10秒跑到9秒9,每提升0.1秒,都要付出几倍的努力和成本。这不是靠一家量化基金的利润就能无限支撑的。
此外,不少人认为DeepSeek曾经的优势,在于对英伟达芯片的深度绑定和调教。
与多数依赖规模堆叠的大模型不同,DeepSeek是从“效率”入手,通过一系列算法与工程优化,实现了接近SOTA水平的性能,同时大幅压低成本。
但这种效率,一方面建立在梁文锋早年量化交易积累的大量英伟达GPU资源之上,另一方面也深度依赖英伟达的CUDA生态。
一旦出现供应链限制,整个公司的研发、训练、推理都可能受到严重影响。而当前美国对高端芯片的出口管制持续收紧,英伟达最新一代Blackwell芯片的获取存在一定限制。
多重压力叠加之下,不是梁文锋想通了,是他不得不通。

DeepSeek V4背后,梁文锋的野心彻底暴露
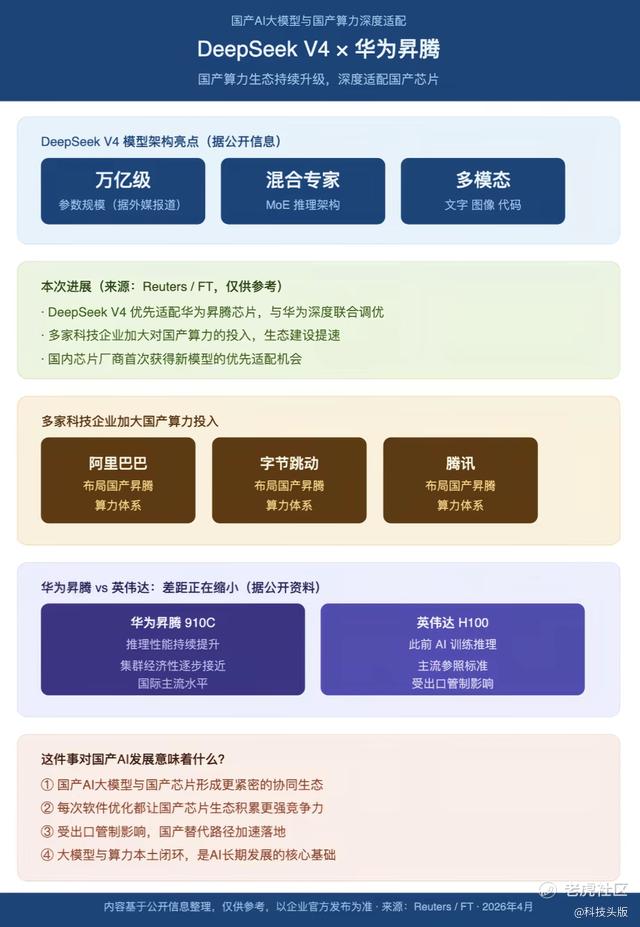
很多人盯着融资的数字,却忽略了这次事件里最影响行业格局的一件事:DeepSeek即将发布的V4模型,正在全力从英伟达的CUDA生态向****芯片迁移。
结合前面所说,V4的技术野心,远超外界想象。
根据目前披露的信息,V4的参数规模跃升至万亿级别。它采用MoE架构,总参数约1万亿,但每个token仅激活约370亿参数,推理成本几乎与V3持平——这个设计思路延续了DeepSeek一贯的效率优先哲学。
上下文窗口扩展到100万token,并引入了一套名为Engram的条件记忆架构,实现超长上下文的恒定时间检索。据内部测试,在100万token长度下的信息召回率达到97%,远超V3在128K上下文时的表现。
更重要的是,V4将是DeepSeek首个原生多模态模型,支持文本、图像和视频生成。此前DeepSeek的模型一直以纯文本为主,而其他旗舰模型早已拥抱多模态。
据悉,该模型代码能力也被大幅强化,内部benchmark显示SWE-bench成绩超过80%,HumanEval达到90%,据称V4能处理整个代码仓库级别的复杂bug修复。
此外,V4预计将分两个版本发布:完整版超万亿参数,面向****芯片;轻量版约2000亿参数,面向通用对话和API服务。
图源:抖音
当然,行业的关注点不会停留在模型本身。
DeepSeek V4对****算力生态的深度适配,大幅降低了对英伟达生态的依赖。这件事的意义之大,以至于英伟达创始人黄仁勋在近期采访中公开表达了关注。
外媒爆料,黄仁勋私下表示,“如果有一天DeepSeek先在**芯片上发布,那对我们来说将是一个可怕的结果”。
当然,这条路并不好走。与英伟达CUDA生态的深度绑定,使得切换国产芯片需要“重写”大量核心代码,迁移成本高昂。
据多家行业媒体报道,DeepSeek原计划今年2月发布V4,但因工程问题多次推迟,团队正在投入大量精力进行适配迁移工作。这也是DeepSeek已有15个月没有大版本更新的重要原因之一。
然而,这件事一旦做成,意义将远远超出DeepSeek自身。
它将成为全球第一个不依赖英伟达的顶尖AI大模型,为中国AI产业链的自主可控提供一个重要的技术支点。
从这个角度看,梁文锋的融资,买的是算力,更是一个生态自主的机会。

融资的深层逻辑
那么,除了这些,融资的真正意义是什么?
首先,融资解决了期权定价的问题。
DeepSeek此前一直没有进行大规模市场化融资,公司估值没有明确的市场标尺,团队成员手里的期权价值缺少清晰的参照。
这次融资,通过市场化方式给公司定了估值,本质上就是给团队搭建了合理的长期激励体系。这比给员工涨工资更重要——在AI这个高度依赖顶级人才的行业,没有市场化的激励机制,留人就是一句空话。
其次,融资为V4的研发和部署提供了弹药。
V4要实现万亿参数、适配国产芯片、做到原生多模态,每一项都是烧钱的大工程。虽然幻方量化持续为DeepSeek供血,但AI大模型竞赛的本质已经变了——这不是接下来一两年可以结束的,未来三年有可能争出个分晓。
梁文锋这次启动融资,核心就是为了长期研发储备充足的算力弹药。
第三,融资开启了商业化的通道。
DeepSeek的开源路线决定了它的商业化路径必须走差异化。闭源玩家的商业化路径更清晰,但DeepSeek必须通过API调用和企业定制来变现。
而企业级客户,尤其是政府客户和大型国企,选择AI供应商时,看的不是技术指标,而是资质和背景。
本轮融资如果引入国有资本,意味着DeepSeek可能获得政府AI项目的优先供应商资格;美元基金入场,则为国际化扩张铺平了资质道路。
但融资也带来了一个无法回避的问题:DeepSeek正在从一家“例外”走向一家正常的商业公司。
过去DeepSeek最特殊的地方,恰恰在于它不像一家典型AI公司。它背后有幻方量化供血,梁文锋不急着融资,也不急着把公司推上估值、商业化和资本退出的流水线。
DeepSeek对自己的定位,与其说是一家商业公司,不如说更像是一个完全独立于资本市场而运作的开源研究机构。
但今天的AI竞争已经不是单点模型能力的竞争了。
字节有豆包、有即梦,阿里和腾讯开始把世界模型推到台前,智谱、MiniMax已经登陆港股。
如果只看DeepSeek至少100亿美元的估值,它当然还是一家很贵的AI公司。可放在今天的中国AI坐标系里,智谱、MiniMax在港股高点的市值都曾突破3000亿港元,月之暗面最新估值已经达到了180亿美元。
DeepSeek过去可以靠技术理想和开源声望行走江湖。但当行业从技术竞赛转向生态和商业化竞争,一家公司终究需要治理结构、估值体系、薪酬激励、商业化收入和长期预算。
研究理想可以继续存在,但公司终究要面对现实。
不是理想不好,是现实太贵。算力成本在涨,人才价格在涨,竞争对手的估值在涨——当所有生产要素都在涨价,技术理想主义本身也在涨价。
梁文锋用三年时间证明了一件事:用更少的钱可以做出很好的模型。但现在他需要证明另一件事:用市场化的方式,能不能让这家公司走得更远。
毕竟,AGI不是靠理想就能抵达的。
作者| 刘峰
免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。
