
VLA 与世界模型之争:谁才是辅助驾驶的正确方向?

芝能科技出品
辅助驾驶的方向,从端到端之后大家就看不明白了,到了2026年自动驾驶与机器人的路线之争被推向了高潮。
但在GTC2026 “选边站队”的辩论,我们将这场纷繁复杂的争论,拆解为三个收敛的维度:技术哲学的分歧、工程实现的瓶颈,以及终极的融合形态。
01
核心争议的细节:
预测“像素”还是预测“逻辑”?
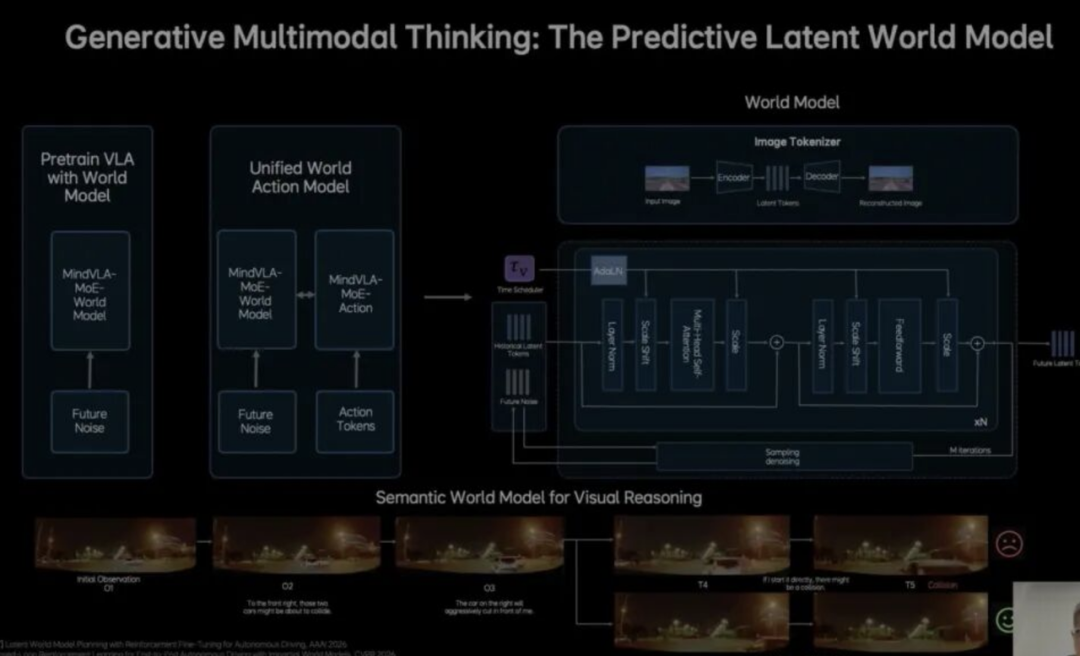
世界模型与 VLA 的根本分歧,在于预测目标的颗粒度。世界模型的细节,真正的世界模型不再试图生成高清的未来视频(那太费算力),而是生成 Latent Tokens,预测的是环境的“状态特征”,比如前方车辆在 0.5 秒后的横向位移概率。
模型不再直接输出动作,而是先预测“下一步世界会变成什么样”,王兴兴认为这种路径“天花板更高”,是指世界模型在训练中学**了重力、摩擦力和运动补偿。
对于辅助驾驶当车辆在雨天侧滑时,模型是基于对路面附着力的物理推演来修正轨迹。
现阶段的视频生成式世界模型算力开销巨大,很难满足辅助驾驶所需的毫秒级实时响应。
VLA 把感知(看到什么)、语义(导航指令/常识)和行动(怎么打方向)压进同一个 Transformer 框架,链路极短,数据从“摄像头”直接流向“执行器”,架构天然适配车规级系统的低延迟要求。
将方向盘转角、加速度直接转化为离散的 Token,与视觉、语言 Token 在同一个 Transformer 空间内对齐。
它的前路在于“语义对齐”,当你说“靠边停车”时,VLA 不需要经过“语音->文本->逻辑规划->控制”的长链条,而是直接在 Embedding 空间里将“停车”语义与视觉中的“路沿”特征耦合,输出 Action。
它强于“拟合”——只要见过足够多的人类驾驶数据,它就能开得像人。但它不理解物理法则,一旦进入从未见过的长尾场景(Corner Cases),泛化能力就会撞上天花板。
02
辅助驾驶前路的核心难点
无论这两条技术路线的如何,终究要回到一个最朴素的迭代和进化的结果,消费者能不能感受到进步,这个系统能不能在真实世界里自己“进化”?
这个进化的闭环被三座大山死死卡住。每一座山,都对应着一个让工程师掉头发的骨头案。
◎ 第一座山:数据闭环——别让“无效里程”淹没AI,现在的自动驾驶测试车每天跑出海量数据,但说白了,99%都是毫无营养的“垃圾时间”。
AI 就像一个学生,天天做一加一等于二的简单题(常规巡航),水平永远提不高。它真正需要的是那些万分之一概率的“奥数题”(事故、极端天气、鬼探头),而这些数据在现实中极难捕捉。
行业正在把“世界模型”当成一个超高级的自动出题机。比如理想的 MindSim,它不再死等现实中的车祸,而是在虚拟世界里生成千万倍于现实的极端场景,再把这些“人造险境”喂给 VLA 模型做强化学**。这种“虚实结合”,让数据闭环第一次有了主动进化的生产力。
◎ 第二座山:推理闭环——在“脑补”与“逃命”之间找平衡辅助驾驶是一个必须跟死神赛跑的强实时系统。
如果让 AI 的“大脑”像拍电影一样,把未来几秒的画面一帧帧高清还原出来(像素级生成),那光算力延迟就能让车撞上三回了。
在时速 120 公里的高速上,毫秒级的卡顿就是生与死的距离。工程师们学会了“抓大放小”,生成完整画面太慢,那就干脆不画了,直接在“隐空间”里做数学题。
系统不再去细抠路边的树是什么颜色,而是把障碍物抽象成一个个带概率的“特征点(Token)”,只预测它们未来 2 秒的位置分布。这种舍弃掉视觉赘肉的“信息压缩”,用工程上的克制换回了保命的实时性。
◎ 第三座山:系统闭环纯神经网络模型最大的问题是它的“不可知性”。
AI 表现得再像老司机,但还是一个黑盒。谁也没法保证,在某种从未见过的光影组合下,它会不会突然抽风把白车看成云朵。这种不确定性,是车规级安全绝对无法接受的。
英伟达等巨头推崇的“混合架构”,给 AI 焊上了一道物理围栏。
端到端模型负责“开得丝滑”,像小脑一样处理日常加减速;底层的安全仲裁器则负责“守住底线”,基于刚性规则的代码。一旦 AI 算出的动作距离前车太近,或者压了实线,规则引擎会瞬间切断 AI 的控制权强制接管。
当前VLA(视觉语言动作模型)正在全面走向“世界模型化”,曾经的技术分歧正在逐渐消失,终局已经明确:
未来的系统将是一个分层的融合架构,我们可以将这个“数字大脑”抽象为三层,分别是负责物理理解与未来推演、为系统提供“常识”和“泛化力”的世界建模层。
负责将认知转化为具体Action、整合多模态信息并输出符合动力学约束丝滑轨迹的决策生成层(VLA Layer),以及负责规则兜底与功能安全的安全执行层(System Layer)。
关于其发展节奏,核心判断是3年看落地,10年看上限。
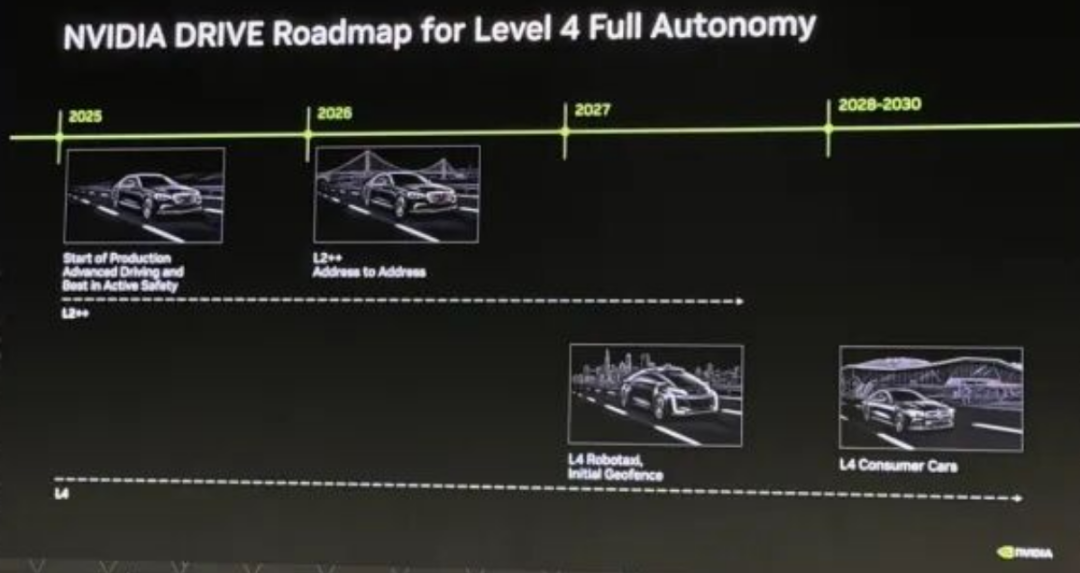
◎ 短期来看(2026-2028)将由VLA主导,它已经具备工程可行性,英伟达和理想给出的2028年L4时间表,正是基于VLA架构的成熟;
◎ 而长期来看(2030+),则由世界模型定胜负,谁能率先完成“世界理解→自动生成数据→现实验证→模型自进化”的全闭环,谁就能真正统治无人驾驶和通用机器人领域。
小结
GTC 2026的争论,VLA是工程师的答案,目标是“先把车开好”,追求工程落地与量产;世界模型是科学家的理想,目标是“先看懂世界”,追求通用与泛化。
而如今这两条路已经完成了在高处的会师——当VLA开始学**3D空间特征(如3D ViT),当世界模型开始被压缩进实时芯片(如Thor),让这套复杂的融合架构,走好的玩家才是赢家。
免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。
