
效率优化与硬体需求的博弈
2026年3月25日,也就是周二,Google Research发布了一项名为TurboQuant的AI记忆体压缩技术,宣称可将大型语言模型(LLM)的记忆体使用量降低至少6倍,同时维持模型准确性不受影响。消息公布后,记忆体类股,立马就在周三(也就是隔天3月26日)遭遇集体重挫。
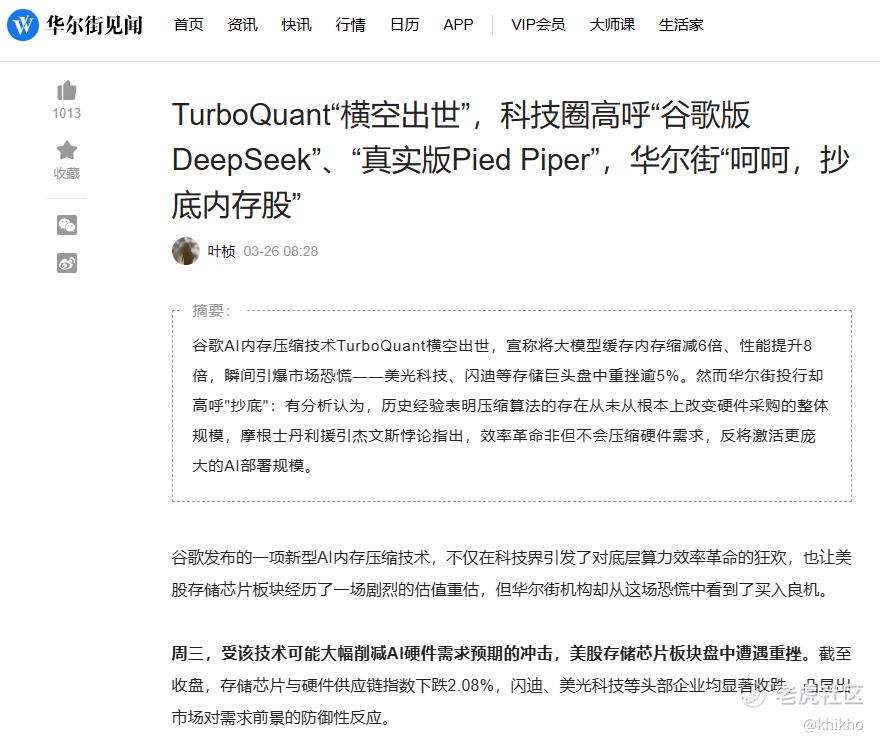
$美光科技(MU)$ 连续第五个交易日走低, $西部数据(WDC)$ 和 $闪迪(SNDK)$ 也相继暴跌不少。这一跌势发生在整体科技股表现强劲的背景下,要知道当日标普500指数上涨了0.4%,纳斯达克综合指数也上涨0.8%,也就是特别凸显记忆体板块的异常弱势。
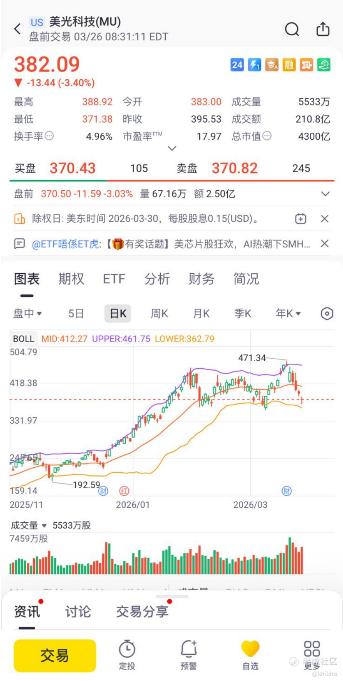
值得注意的是,美光此前公布的财报表现极为亮眼,营收达136.4亿美元,年增57%,非GAAP每股盈余4.78美元,超出预期21%。公司甚至给出更强劲的季度前瞻指引,预期营收187亿美元、EPS 8.42美元,毛利率将达68%。然而,即便基本面如此强劲,股价仍因Google技术消息而下跌,显示市场情绪已发生微妙转变。
此次市场反应的核心逻辑在于, $谷歌(GOOG)$ 的技术突破可能改变AI产业对硬体记忆体需求的成长轨迹。当软体演算法能够显著降低记忆体门槛时,市场开始重新评估记忆体厂商的长期成长动能与定价权。Google Research于2026年3月24日发布的官方博客中详细介绍了TurboQuant的技术架构。这项技术是一套无需重新训练或微调即可部署的压缩演算法组合,专门针对LLM的Key-Value(KV)快取进行优化。

据报道里看到的,这个TurboQuant是采用两阶段压缩流程,大概就下面这样:
第一阶段,是PolarQuant坐标转换。传统向量量化方法使用标准笛卡尔坐标(XYZ坐标系)编码向量,需要为每个数据块存储高精度的量化常数,产生额外的记忆体开销。PolarQuant将向量从笛卡尔坐标转换为极坐标系统,将每个向量分解为半径(代表数据强度)和角度(代表数据方向)两个维度。由于角度分布具有可预测性和集中性,该方法消除了传统量化器所需的昂贵逐块归一化步骤,实现零开销压缩。
第二阶段,是QJL误差校正,Quantized Johnson-Lindenstrauss(QJL)演算法将残余量化误差投影到低维空间,将每个值缩减为单一符号位(正或负)。这一步骤引入零记忆体开销,并通过将高精度查询向量与简化存储数据配对计算注意力分数,维持模型准确性。
根据Google Research在NVIDIA H100 GPU上的基准测试,TurboQuant展现出惊人的效率提升,特别是记忆体压缩率,KV快取可压缩至3位元(3-bit)精度,记忆体使用量减少至少6倍。
运算效能也是大大的加强了,4位元TurboQuant在计算注意力对数(attention logits)时,相比未压缩的32位元键值,效能提升高达8倍。
准确性维持的也不错,在LongBench、Needle In A Haystack、ZeroSCROLLS、RULER和L-Eval等长文本基准测试中,TurboQuant实现了零准确性损失,在"大海捞针"检索任务中达成完美下游表现。
此外,TurboQuant在向量搜寻Vector Search应用中也展现出色表现。在测试中,TurboQuant超越了Product Quantization(PQ)和RabbiQ等现有最佳方法,且无需大型码本或数据集特定调优。Google Research强调,TurboQuant的"数据无关"(data-oblivious)特性意味着它无需针对特定数据集进行校准,可直接部署于生产环境的推理系统和大型向量搜寻引擎中。这项技术的核心价值在于:
降低AI部署门槛:企业可在不升级昂贵硬体的情况下运行大型语言模型。
延长既有设备生命周期:现有GPU资源可支援更大的上下文视窗。
加速边缘AI发展:资源受限的终端设备(手机、IoT装置)可运行更复杂的AI模型。
记忆体股的重挫反映了市场对"需求高原化"(Demand Plateauing)的深层担忧。过去两年,AI产业被视为记忆体的"超级吃货"——每个AI服务器需要TB级别的HBM(高频宽记忆体)和DDR5 DRAM,推动记忆体价格飙升。然而,TurboQuant的出现让市场意识到,软体效率优化可能显著降低单位运算量的硬体需求。
Wells Fargo分析师在报告中指出,类似TurboQuant的技术可能导致美光高阶记忆体晶片的需求趋缓。这一担忧并非空穴来风:若AI模型可在压缩6倍记忆体的环境下维持相同效能,资料中心采购记忆体的总需求量可能面临向下修正。
更深层的产业结构性转变正在发生。AI算力竞争的焦点正从纯粹的"硬体规格竞赛"转向"软硬体协同优化"。这对纯记忆体厂商(如美光、Western Digital、Seagate)的定价权构成潜在压力。
过去,记忆体厂商受益于AI模型的"记忆体饥饿"特性——模型越大、上下文越长,所需的KV快取就越多。但TurboQuant等技术打破了这种线性关系,让软体优化成为记忆体需求的关键变数。当Google、OpenAI等AI巨头可以通过演算法创新降低硬体依赖时,记忆体厂商在产业链中的议价地位可能受到侵蚀。
此外,SK Hynix计划下半年在美国主要交易所上市的消息,也为美光带来竞争压力。分析师认为,SK Hynix的上市可能分流原本投向美光的投资资金,尽管这不影响美光的基本面业务。
尽管TurboQuant引发短期恐慌,但AI记忆体需求的长期展望仍存在多个支撑因素:
HBM需求依旧坚挺,TurboQuant主要针对的是LLM推理阶段的KV快取压缩,而非训练阶段的高频宽记忆体需求。目前最顶尖的AI训练仍极度依赖HBM——NVIDIA H100/H200 GPU、AMD MI300系列等加速器均需要大量HBM堆叠。美光的HBM产品已售罄至2026年,订单甚至延伸至2027年。短期内,这类高毛利产品的需求受演算法优化的冲击较小。
边缘AI(Edge AI)的爆发潜力,TurboQuant等技术对资源受限的终端设备尤为重要。随着压缩技术的进步,更多消费性电子装置(AI PC、AI手机、IoT设备)将具备运行复杂AI模型的能力。这可能带动记忆体总出货量(Total Addressable Market, TAM)的扩张,尽管单机记忆体容量可能下降,但整体装置基数将显著增长。
资料中心建设的持续动能,hyperscalers(微软、Google、Meta、亚马逊)的AI基础设施建设仍处于高峰期。根据IDC分析,2026年AI资料中心可能消耗全球约70%的高阶DRAM,这一结构性配置短期内难以逆转。即便单机记忆体效率提升,整体资料中心规模的扩张仍可能支撑记忆体需求。
记忆体产业的供给面同样存在支撑价格的因素:
产能配置的零和博弈,HBM与传统DRAM共享相同的晶圆产能。每生产一片HBM晶圆,就意味着减少三片DDR5晶圆的产出。SK Hynix、三星、美光三大厂商已将大量产能转向HBM生产,导致标准DRAM供给吃紧。这种产能配置的结构性转变,意味着即便AI推理记忆体需求因TurboQuant而减少,释放的产能也可能被HBM生产所吸收,而非流向消费性市场。
新产能投产的时间落差,新晶圆厂的建置需要数年时间。Micron的Idaho新厂预计2027年投产,New York新厂则要等到2028年;SK Hynix的Yongin厂也预计2027年完工。在2027-2028年新产能大规模释出之前,记忆体供给仍将维持紧张状态。
地缘政治风险溢价,中东局势紧张、美中科技战持续,为记忆体供应链增添不确定性。美光作为美国本土的记忆体大厂,虽可能受益于"友岸外包"趋势,但其全球供应链仍面临潜在的地缘政治风险。
对于我们这些普通的美股投资人而言,当前的记忆体股修正,提供了重新评估持仓结构的契机。在效率优化成为产业共识的背景下,拥有HBM技术领先优势和多元化产品组合的记忆体厂商,将比依赖单一标准DRAM产品的公司更具韧性。美光、SK Hynix、三星三大厂商的竞争格局,也将因软体技术的进步而进入新的动态平衡。
朋友们觉得呢?[鬼脸]
[财迷]$老虎证券(TIGR)$ [财迷]
免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。
- ReginaEipstein·03-26机会来了,准备进场!点赞举报