
黄仁勋的Vera Rubin来了,这次不止AI超算,还有这些........
3 月 17 日凌晨,美国加州圣何塞 GTC 大会现场,黄仁勋径直登台。没有多余铺垫,英伟达创始人兼 CEO 只一句 “这是一次代际飞跃”,便正式揭开新一代 AI 超算平台 Vera Rubin 的神秘面纱。


整场演讲硬核十足、节奏干脆,既复盘了英伟达十年 AI 超算迭代之路,也直白拆解了 Vera Rubin 如何击穿智能体 AI 算力瓶颈,重新定义整个 AI 产业的算力格局。
十年迭代:从 DGX-1 到智能体超算时代
一切要从十年前说起。2016 年 4 月 6 日,英伟达推出DGX-1—— 全球首款深度学习专用计算机,8 颗 Pascal GPU + 第一代 NVLink,单机算力 170 TFLOPS,为 AI 研究者打开全新大门。随后 Volta 架构登场,NVLink 交换机让 16 颗 GPU 全互联,化作一颗 “巨型 GPU”。
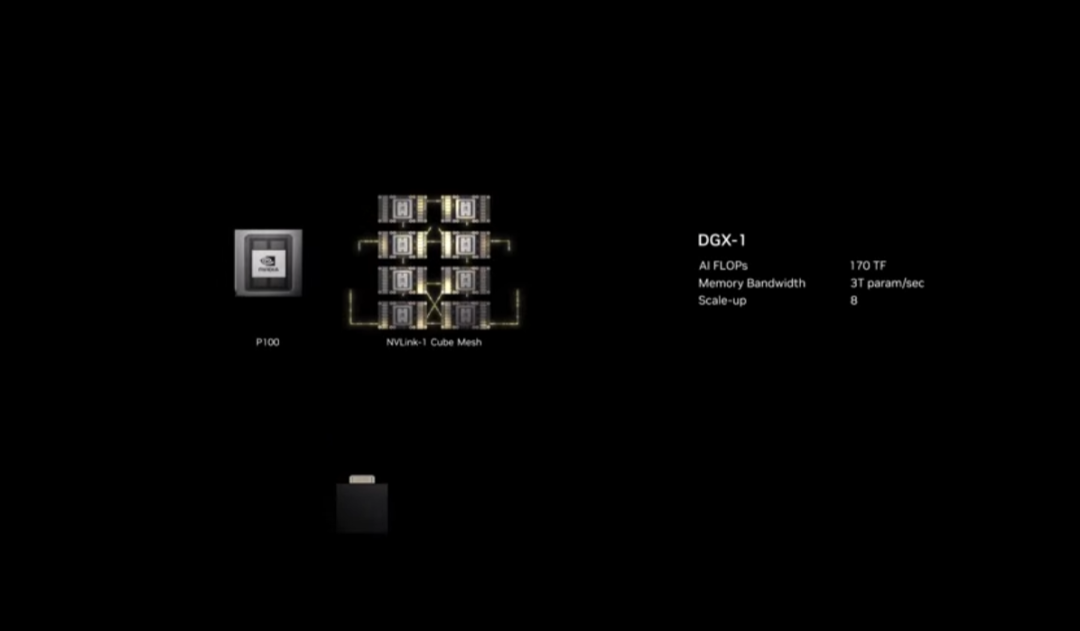
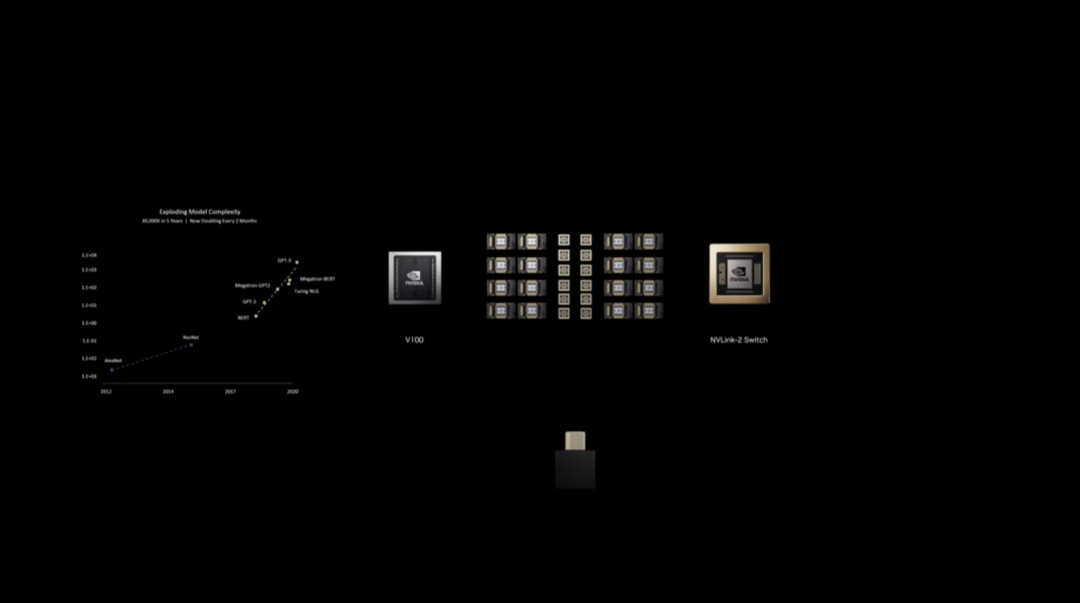
模型规模疯涨,数据中心必须成为统一计算单元。2020 年 Mellanox 加盟,DGX Superpod 成为首款支持纵向扩展和横向扩展的 GPU 超算。Hopper 架构携 FP8 Transformer 引擎到来,正式开启生成式 AI 时代。Blackwell 架构再破边界,以 NVLink 重构 AI 超算系统。

而今天,智能体 AI 的算力需求呈指数级爆发,预训练、微调、推理三大定律全速运转 ,Vera Rubin 则应运而生。
全新 Vera Rubin:七颗芯片,一台超算,专为智能体而生

Vera Rubin 从一开始就瞄准智能体系统,是软硬件端到端优化、垂直整合的 “巨型系统”,标志着 AI 超算进入全新时代。

全新Groq系统、第六代NVLink、Vera Rubin(从左至右)
这套革命性平台由七颗全新芯片、五种机架组成一台完整 AI 超算:Rubin GPU、Vera CPU、NVLink 6 交换机、ConnectX-9 SuperNIC、BlueField-4 DPU、Spectrum-6 以太网交换机、Groq 3 LPU。
它的实力堪称恐怖:

算力高达3.6 exaFLOPS,NVLink 全互联带宽260 TB/s
十年算力提升4000 万倍,十年前 DGX ONE 仅 170 TFLOPS
100% 液冷,45℃热水散热,布线大幅简化,安装从 2 天缩短至 2 小时
第六代 NVLink 独步全球,难度极高,是英伟达核心 “秘密武器”
Vera CPU:全球唯一数据中心 LPDDR5 CPU

Vera CPU(中间)
作为英伟达第二代自研 CPU,Vera CPU 专为智能体 AI 工具调用场景打造:
88 个定制 Olympus 核心,Arm v9.2 架构
1.5 TB LPDDR5X 内存,NVLink-C2C 直连带宽 1.8 TB/s
极致单核性能与能效,全球唯一数据中心级 LPDDR5 CPU
Rubin Ultra:全场压轴,性能狂飙 14 倍
本次大会终极杀招 ——Rubin Ultra:

GPU 封装内置 4 颗计算 die(普通 Rubin 为 2 颗),1 TB HBM4e 内存
单封装 FP4 推理算力100 PFLOPS
全新 Kyber 机架,垂直插入、中板直连,抛弃传统铜缆
单机架 144 个 GPU 封装,FP4 推理达15 exaFLOPS,365 TB 高速内存
性能较 Blackwell GB300 NVL72 直接提升14 倍
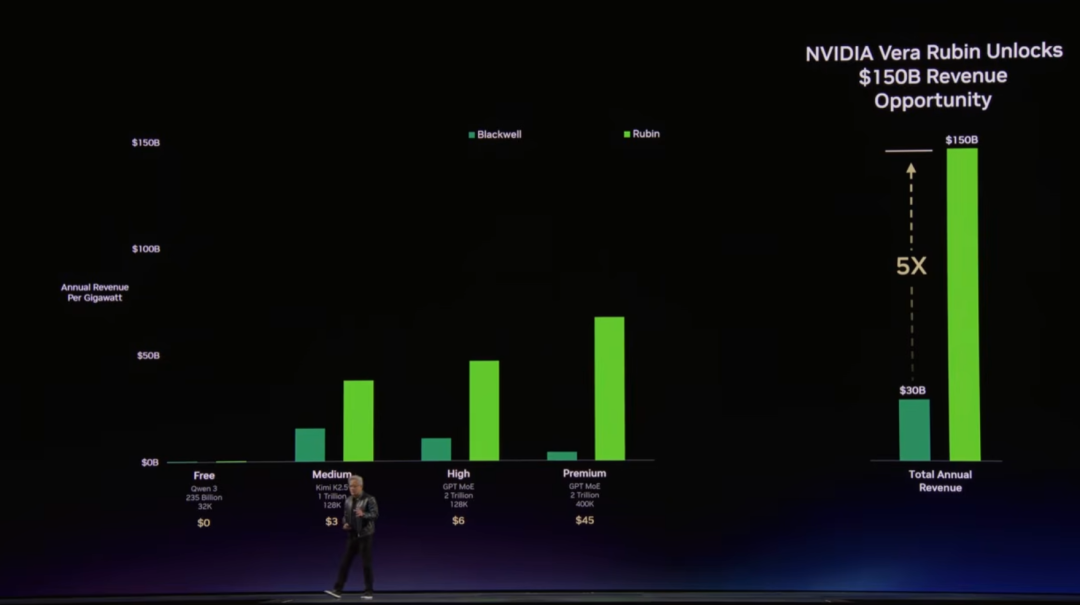
一张让所有CEO关注的图:Token 就是AI 工厂的货币
黄仁勋亮出一张未来 AI 工厂核心图表,直言全球每位 CEO 都会紧盯它。

横轴:Token 生成速度 纵轴:等功耗吞吐量
数据中心就是 AI 工厂,电力是产能,Token 是产品。他将服务划为四档:
免费档:高吞吐、低成本小模型
中等档:更大模型、更长上下文
高价档:高性能深度推理
超级档:关键任务,定价高达150 美元 / 百万 Token
按 1 吉瓦数据中心简单测算:Grace Blackwell 相较 Hopper 吞吐量提升35 倍,收入增 5 倍;Vera Rubin 再提升 5 倍,收入再翻 5 倍。
首次集成 Groq:推理性能狂飙 35 倍
英伟达以200 亿美元授权费拿下 Groq LPU 技术,引入创始团队,打造出最强推理组合。
Groq 3 LPU 是完全不同的芯片:

确定性数据流处理器,静态编译、编译器调度
片上 500 MB SRAM,带宽却高达150 TB/s(接近 Rubin 的 7 倍)
天生为低时延 Token 生成而生
通过Dynamo 软件解耦推理流程:
Prefill 与 Attention 交给 Vera Rubin(算力 + KV 缓存)
解码与 Token 生成卸载给 Groq(极致带宽 + 低时延)
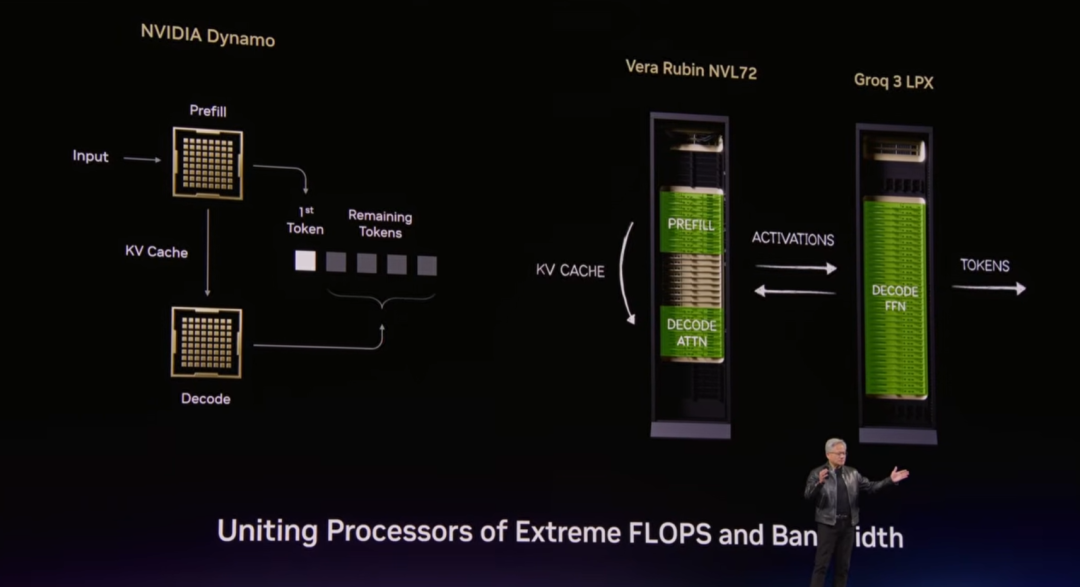
最终在最高价值的超级档位,性能再提升 35 倍,突破 NVLink 72 极限。
Groq 3 LPU 由三星代工,已量产,2026 年 Q3 出货;单 LPX 机架 256 颗 LPU,扩展带宽 640 TB/s。

部署建议
高吞吐训练 / 批量推理:100% 使用 Vera Rubin
代码等高价值 Token 生成:25% 配 Groq,75% 用 Vera Rubin
短短两年,软硬件协同让 Token 生成率从 2200 万飙升至 7 亿,暴涨 350 倍。
未来路线图 + 太空算力:英伟达扩张无边界
英伟达年更节奏锁定:Blackwell → Blackwell Ultra → Rubin → Rubin Ultra → Feynman(2028 年)

Feynman 将搭载 LP40 LPU、Rosa CPU、BlueField 5、CX10,首次同时支持铜缆与 CPO 扩展,每代推理提升 3-5 倍,训练提升 2-3 倍。
甚至延伸至太空:

Vera Rubin Space-1 轨道模块,推理性能较 H100 强 25 倍
Thor 芯片通过辐射认证,下一步在轨建数据中心
从黄仁勋演讲中给出了一个明确的判断,AI的重心正在从训练转向推理,从模型为王走向全栈基建为王。而Vera Rubin的推出,正是这一判断的最好佐证。它不仅是英伟达自身的一次代际飞跃,更将改变整个AI基础设施的格局。当算力成本大幅降低、效率大幅提升,无论是企业级的智能体应用,还是消费端的AI交互,都将迎来爆发式增长。
对于普通人而言,Vera Rubin带来的改变或许不会立刻显现,但它正在悄悄铺垫一个“智能体无处不在”的未来:你的手机AI能自主帮你整理邮件、规划行程,企业里的智能体能自动处理财务、对接业务,工厂里的AI能自主控制机器人完成生产……而这一切,都始于今天这场GTC大会上,英伟达递出的这把“算力钥匙”。
正如黄仁勋所说,Vera Rubin标志着英伟达史上最大规模基础设施建设的开端。这场由算力驱动的革命,已经拉开序幕,而智能体AI的黄金时代,也将在这份强大的基建支撑下,加速到来。
图形学的GPT时刻!英伟达DLSS 5,游戏的下一个世代来了.....
没有一行代码,这只果蝇自己会爬了
AI迈入“星际时代”:英伟达黄仁勋发布Space-1 Rubin模块
免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。
