
性能与效率兼顾,阿里通义千问320亿参数Qwen1.5-32B模型亮相
美股研究社讯,4月7日,阿里通义千问继上线了5亿、18亿、40亿、70亿、140亿和720亿参数大语言模型后,又开源了一款320亿参数的Qwen1.5-32B模型。这款新模型在性能、效率和内存占用之间实现了更加理想的平衡。
通义千问表示,尽管现有的SOTA模型如Qwen1.5-72B和DBRX等性能卓越,但仍存在内存消耗大、推理速度慢、微调成本高等问题。而当前参数量约300亿的模型很受用户青睐。他们针对这一需求,精心研发了Qwen1.5-32B-Base及Qwen1.5-32B-Chat两款模型。
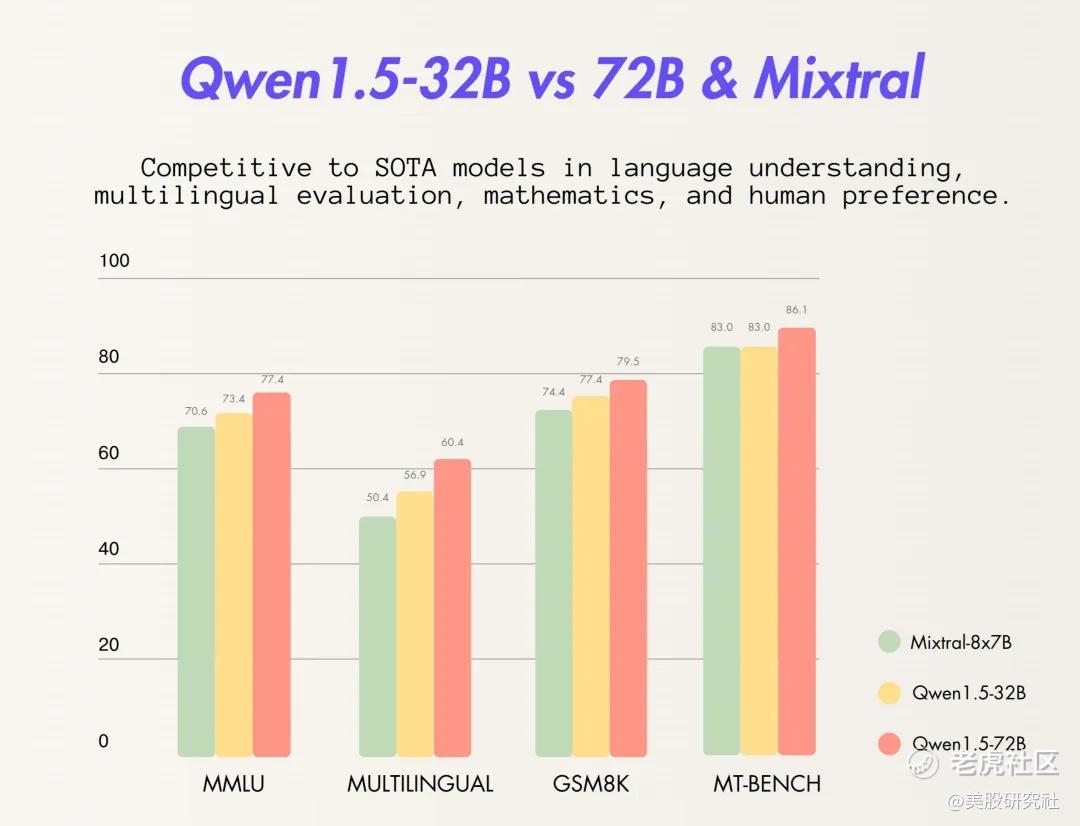
Qwen1.5-32B-Base模型的性能对标了目前最先进的30B模型水平。Qwen1.5-32B-Chat则在对齐方面(特别是RLHF)有所突破,对话能力提升。相较72B模型,32B系列内存占用显著下降,运行速度明显加快。阿里希望32B模型能帮助用户获得更优的下游应用解决方案。
在基础能力测评中,Qwen1.5-32B展现出颇具竞争力的水平,虽略逊于72B模型,但优于其他30B级别模型。在Chat模型测试中,32B-Chat模型得分超过8分,与72B模型仅有小幅差距。多语言评测也显示,32B具备出色的多语种能力。此外,32B-Chat在长文本场景中也有优异表现。
目前,用户可通过魔搭社区ModelScope、Hugging Face等渠道体验Qwen1.5-32B模型。阿里同时提供了相关的安装部署教程及技术博客,指导用户在不同框架上使用该模型。
免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。
点赞
举报
登录后可参与评论

暂无评论