
HBM 之后,AI 内存开始卷到整机了
如果只看表面消息,最近 AI 内存似乎出了一个利空:NVIDIA Vera Rubin 相关 SOCAMM 配置被市场理解为降配,单 CPU 内存内容量从 192GB 调到 96GB。很多投资者第一反应是,CPU 侧内存需求是不是降温了,AI 服务器里的内存增量是不是没有之前想象得那么大。
但我更倾向于把这件事理解为一次误读。
真正的问题不一定是 AI 内存不需要了,而是内存供给太紧,系统必须在容量、数量和配置之间重新平衡。换句话说,表面上是降配,底层可能是缺货。
这篇文章想讨论的是一个更重要的变化:AI 内存的投资主线,正在从 GPU 旁边的 HBM,扩散到整机内存架构和推理数据管线。
训练时代,市场最容易理解的是 HBM,因为它直接贴着 GPU,决定带宽,也决定 AI 加速卡性能。但推理时代不一样。模型要处理更长上下文,Agent 要进行多轮规划和工具调用,RAG 要频繁检索和写回,KV Cache 要不断存取和迁移。这个时候,内存和存储不再只是“容量”,而是推理效率的一部分。
所以,我对这条主线的判断是:
AI 内存没有降温,只是从 HBM 单点扩张,进入 HBM、SOCAMM、LPDDR、eSSD、KV Cache 共同重估的新阶段。
SOCAMM 降配,不等于需求下降
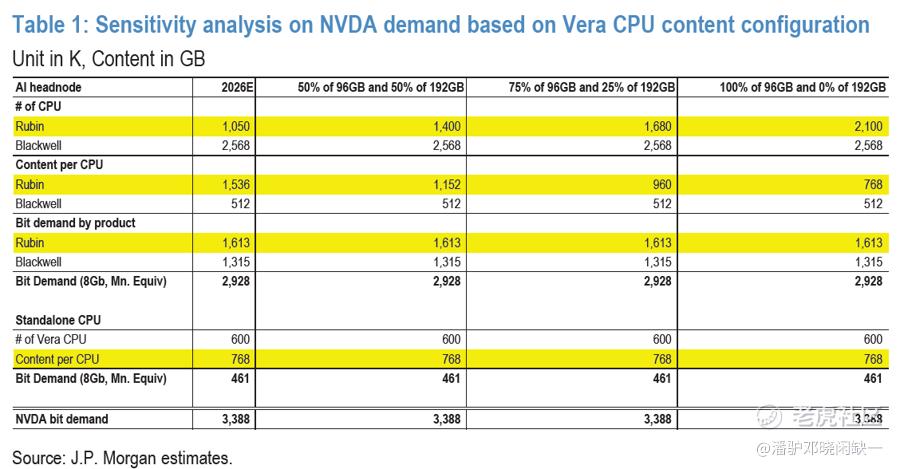
市场最关心的点,是 Vera Rubin NVL72 rack 里 SOCAMM 内容量下调。原本部分投资者期待更高规格配置,如果单 CPU 内容量从 192GB 降到 96GB,很容易被理解为 CPU 侧内存需求变弱。
但这不认为就是需求下降。
关键在于,内存需求不是只看单颗 CPU 搭多少容量,还要看整机系统里 CPU 数量、模块数量和总 bit demand。敏感性测算显示,在不同 96GB 和 192GB SOCAMM 配置组合下,即使 96GB 模块占比提高,NVDA 对应的总 bit demand 仍可以保持不变。原因是单颗 CPU 内容量下修,会被更高模块需求或更多 CPU 数量补偿。
这和消费电子里简单的“降配”不一样。
如果一台手机从 512GB 降到 256GB,那可能确实意味着单机价值量下降。但 AI 服务器是系统工程。客户面对的是有限内存供应、算力交付节奏和整机性能平衡,不是单独挑一个配置表。供给紧的时候,系统设计会在容量、数量、交付和成本之间重新排列。单点规格下调,并不必然代表总需求下滑。
市场看到的是 192GB 到 96GB,我更关心的是总 bit demand 有没有变。如果总 bit demand 没变,甚至未来在推理负载扩张下继续增加,那么这不是需求降温,而是供给约束下的架构重排。
NVIDIA 与 SK Hynix,不只是 HBM 绑定
另一个更长期的信号,是 NVIDIA 与 SK Hynix 的多年技术合作。
这件事不应该只理解成 HBM 供货锁定。更重要的是,合作范围已经从数据中心 HBM,延伸到 NVIDIA 的多条平台路线:Vera Rubin 超算、Vera CPU、RTX Spark PC、Jetson Thor 机器人平台。对应的内存形态,也不只有 HBM,还包括 SOCAMM、LPDDR、NAND 等更完整的组合。
这意味着 SK Hynix 的角色正在发生变化。
过去市场看存储厂,更多是看周期品:价格涨跌、库存变化、产能扩张、下游补库存。现在,头部存储厂开始绑定 AI 平台路线图,提前参与下一代系统架构定义。它们不再只是卖标准内存颗粒,而是在和 AI 平台公司共同设计下一代内存方案。
这个变化很关键。
HBM 是入口,但不是终点。真正的变化,是内存公司从单一零部件供应商,向 AI 基础设施伙伴升级。谁能更早绑定平台路线图,谁就更可能获得更长的需求可见度、更强的产品定义权和更稳定的产能规划。
对 SK Hynix 来说,多年合作的意义不只是 2026 年多卖一些 HBM,而是需求可见度可能延伸到 2027 年甚至更远。对其他存储厂来说,这也不是纯粹利空,因为如果高端内存供给持续紧张,整个行业都会处在“供不应求先于份额重新分配”的状态里。

AI 内存主线,从 HBM 扩到 SOCAMM
过去两年,AI 存储链最清晰的主线是 HBM。
这个逻辑非常直接。GPU 算力越强,越需要高带宽内存喂数据。训练大模型时,HBM 决定带宽、容量和能效,是 AI 加速器最核心的瓶颈之一。SK Hynix 能够成为这轮存储行情里的最强资产,很大程度上就是因为 HBM 领先。
但进入 Vera Rubin 和推理放量阶段后,内存主线会变宽。
GPU 旁边需要 HBM,CPU 侧需要 SOCAMM,边缘和个人 AI 设备需要 LPDDR,AI 数据管线需要 eSSD,长上下文推理需要 KV Cache 分层。换句话说,AI 内存不再只围绕 GPU 一处堆料,而是整机系统都在提高内存和存储密度。
这也是为什么 SOCAMM 重要。
SOCAMM 可以理解为 AI 服务器 CPU 侧内存架构的一部分。它不像 HBM 那样直接贴在 GPU 上,但它承接的是 CPU、推理任务、系统内存和整机数据流转的需求。当 AI 服务器从单纯训练机器变成训练、推理、RAG、Agent、多模态共同运行的平台,CPU 侧内存的重要性会提高。
Agent 不是一次问答,而是一条任务链。任务链越长,上下文越长,工具调用越多,系统就越依赖内存容量、读写速度和数据调度。未来 AI 基础设施的瓶颈,不会只出现在 GPU 算力,也会出现在内存层、存储层和数据移动层。
所以,SOCAMM 的意义不在于它是不是马上成为下一个 HBM,而在于它证明了 AI 内存需求正在从 GPU 侧扩散到整机。
Computex 的信号:eSSD 进入 AI 数据管线
Solidigm 的信息非常关键:不同类型 SSD 正在对应 AI 流程里的不同层级。Local SSD 用于数据准备、训练和推理;高性能 SSD 用于推理中的 KV Cache tier;共享存储用于 inactive KV 和归档。这说明存储不再只是把数据放在那里,而是在参与推理效率优化。
更直观的一个数据是,把 KV Cache offload 到 NAND,相比重新计算上下文,TTFT 可以快到 27 倍。
TTFT 是 time to first token,也就是用户发出请求后,模型输出第一个 token 的时间。对推理服务来说,TTFT 直接影响用户体验和系统吞吐。如果 KV Cache 可以通过更合理的存储分层降低重复计算,NAND 和 eSSD 的价值就不只是便宜容量,而是推理效率。
这就是 NAND 重新进入 AI 基建逻辑的原因。
过去市场看 NAND,主要看手机、PC、服务器补库存,看价格周期,看供给出清。现在看 NAND,要多一层:AI 推理、RAG、KV Cache、Agent 工作流和数据管线。
Kioxia 与 NVIDIA 的合作也在指向这个方向。通过面向大规模 RAG 的服务器方案和软件能力,NAND 厂商开始尝试从硬件供应商,向存储系统和软件协同方向延伸。这个变化如果继续推进,NAND 的投资逻辑就不再只是周期修复,而是 AI 推理基础设施的一部分。
为什么 NAND 的位置会变
训练时代,数据流相对更容易被理解:模型训练需要大量 GPU,需要高带宽内存,需要高速网络,需要海量训练数据。
推理时代更复杂。
用户请求不是一次性的。多轮对话要保存上下文,Agent 要规划、调用工具、读取文档、写回结果,再继续推理。RAG 要从外部知识库检索内容,模型要把检索结果和历史上下文一起处理。复杂任务越多,数据不可能一直放在最贵、最快的显存里。
这就带来一个问题:哪些数据要放在 HBM,哪些要放在 DRAM,哪些要放在 eSSD,哪些可以放进共享存储?
这背后其实是推理基础设施的成本优化。
HBM 最快,也最贵;DRAM 承接系统内存和中间数据;eSSD 在速度、容量和成本之间找到平衡;共享存储负责更低频、冷一些的数据。未来 AI 系统的竞争,不只是算力竞争,也会是内存与存储分层的竞争。
它不像 HBM 那样显眼,但会越来越多地出现在推理集群、RAG 服务器和 KV Cache 管理里。尤其当 Agent 需求放量后,模型调用次数、上下文长度和任务链复杂度都会上升,存储分层的重要性只会提高。
所以,NAND 不是突然变成 HBM,也不是所有 NAND 都值得重估。真正值得看的,是企业级 SSD、高性能 SSD、软件定义存储、KV Cache offload 和 AI 数据管线这些方向。
回调怎么看:关键是市场有没有误读需求
最近 memory shares 一周回调约 11%,同期 SOX 回调约 6%。表面原因包括 SOCAMM 内容量噪音和地缘因素。
如果 SOCAMM 的内容下调代表 AI 内存需求见顶,那回调当然合理。但如果它只是供给紧张下的配置重排,总 bit demand 没有下降,那么这轮回调更像预期扰动。
我倾向于后者。
这不是说存储股没有风险。恰恰相反,这条线已经涨得很充分,市场对 HBM、AI DRAM、eSSD 的预期也不低。后面任何内容量调整、客户节奏变化、地缘扰动、资本开支变化,都可能带来波动。
但中期逻辑没有变:AI 内存需求不是降温,而是结构变复杂。训练继续需要 HBM,推理增加 CPU 侧内存,RAG 和 Agent 增加 eSSD 与 KV Cache 需求,NVIDIA 与头部存储厂的合作拉长需求可见度。
所以,我不会把这次 SOCAMM 事件理解成 AI 内存周期反转。它更像是在告诉市场:AI 系统正在进入供给紧张下的架构重排阶段。
真正应该观察的,不是某一个配置从 192GB 变成 96GB,而是总 bit demand、模块出货量、HBM4 量产、SOCAMM 放量、eSSD 渗透和客户长期协议。
公司映射:谁受益于这轮内存架构扩散
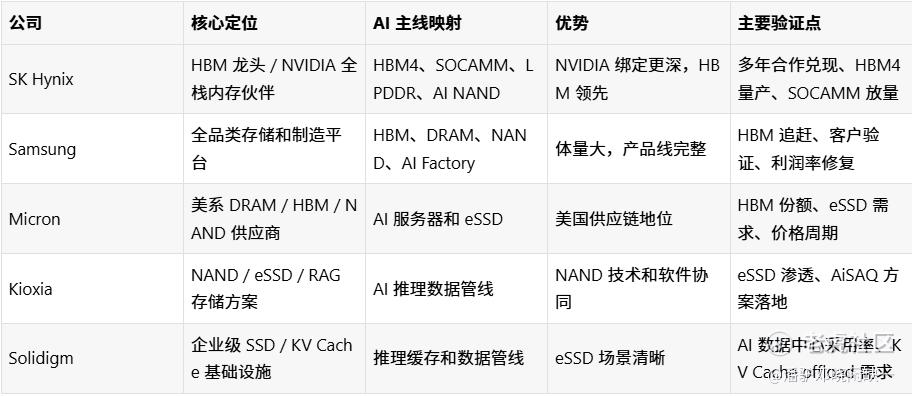
HBM 是最确定的高价值环节,但不是唯一环节。SOCAMM 代表 CPU 侧和整机内存扩张,LPDDR 代表个人 AI 和边缘设备,eSSD 代表推理数据管线,KV Cache 代表上下文成本优化。
未来市场不会只问谁有 HBM,还会问谁能进入 NVIDIA 和云厂商的系统路线图,谁能参与推理基础设施,谁能在内存和存储分层里拿到更高价值的位置。
SOCAMM 降配是假利空,AI 内存主线变长了
这件事更像是供给紧张下的架构重排。单 CPU 内容量下修,不代表总 bit demand 下降;在系统层面,模块数量、CPU 数量和整机配置都可以重新平衡。市场把它简单理解为需求减少,可能低估了 AI 内存架构正在发生的变化。
真正重要的是,AI 内存主线已经从 HBM 扩散到 SOCAMM、LPDDR、eSSD 和 KV Cache。训练时代看 GPU 旁边的高带宽内存,推理时代要看整机内存、数据移动、缓存分层和存储效率。
资料来源:本文综合整理自 J.P. Morgan 存储市场更新、NVIDIA 及相关公司公开资料、行业公开信息,数据与观点来源于上述资料,仅供研究交流参考,不构成任何投资建议。
免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。
