
Scaling Law的尽头是什么?|甲子引力X

大模型的“摩尔定律”。
2024年5月15日,由中国科技产业智库“甲子光年”主办、中关村东升科学城协办的“AI创生时代——2024甲子引力X科技产业新风向”大会在北京举办。
在当日下午举行的“AI技术范式的变革:Scaling Law的尽头是什么”圆桌环节,百度集团副总裁侯震宇、中国人民大学高瓴人工智能学院教授卢志武、清智资本创始合伙人张煜、新浪微博新技术研发负责人张俊林、RWKV元始智能COO罗璇与甲子光年高级分析师王艺一起探讨了Scaling Law的发展趋势。
Scaling Law是大模型的“摩尔定律”,它指引了大模型按照大算力、大参数、大数据的方向前行。但对于Scaling Law的发展前景,业内看法不一。
侯震宇坚定地支持Scaling Law,并认为至少在当前,Scaling Law仍然有效且潜力巨大。他还提到了摩尔定律和安迪-比尔定律,认为Scaling Law在AI领域也呈现出类似的效应,即算力的增长被算法和数据的需求所消耗。
卢志武表示有条件地支持Scaling Law,认为它在实现AGI方面可能不够充分。他提出可能需要更好的模型架构,并指出Transformer模型可能不是最终解决方案。卢志武还强调了商业化成功需要考虑更多因素,不仅仅是模型规模。
张煜认为Scaling Law在短期内是有效的,但长期来看可能会遇到极限。他通过比喻说明了Scaling Law的局限性,比如爬树无法到达月球,暗示了可能需要新的方法或技术突破。
张俊林将Scaling Law视为一个经验公式,认为它基于大量实验和数据。他觉得在当前阶段,Scaling Law是成立的,但随着时间的推移,可能会看到它的效果放缓。
罗璇非常相信Scaling Law,但指出Transformer架构的时间和空间复杂度问题导致算力和数据利用率低。他认为未来会有新算法提高数据和算力的效率,并提到了RWKV的架构可能代表了这种发展方向。
以下是本场圆桌的演讲实录,“甲子光年”整理删改:
1.Scaling Law在放缓

王艺 :围绕Scaling Law有很多的争议,有些人是坚定的信仰者,觉得只要堆数据、堆算力就能带领我们达到AGI;但是也有人认为你无限堆数据和算力并不能无限提升模型的性能,它其实会慢慢趋向于一个固定的值。你是Scaling Law的坚定信仰者吗?
侯震宇:我是。从我们的实践和国内外发表的论文中看,至少在当下Scaling Law肯定还是在在发挥作用的,而且我觉得潜力还很大。
我在百度做了十几年,一直都在做大的基础设施和技术架构方面的工作,我们特别喜欢一个状态,就是当发现一个很难解决的问题,如果能通过扩展规模去解决,那我们就会觉得很兴奋。

百度集团副总裁侯震宇
过去的AI更多是各种各样基于模型的调优,而这一轮的大模型,在Transformer之后,到现在大家提到的Scaling Law,算是一种新的研发范式,真的能够在芯片基础设施、系统层面上和算法解耦。
过去几十年指引IT发展最大的共识是“摩尔定律”,其实还有一个“安迪比尔定律”,是说安迪·格鲁夫做出来的算力都会被比尔·盖茨消耗掉,所以他们当年成立了一个Wintel联盟。但是在Scaling Law的情况下,算力、数据和算法也实现了一个微妙的组合,我们相信它还是会持续发展。当然,某种程度上Scaling Law也是模型的学习量和算力的供给之间的换算关系,在我们看来它还有很大的优化空间,希望它可以持续地再演进下去。
卢志武:对于Scaling Law,我是带条件的支持。Scaling Law肯定是很有用的,但是如果从实现AGI的角度来看,Scaling Law又远远不够。
举个例子,虽然现在大家都觉得Transformer很好,但Transformer架构是不是AGI的最终章还是要打个很大的问号,需要国内外学术界再去研究是否会有更好的模型出现,其实这种概率挺高的。我们不能只在Transformer的基础 上去堆算力和数据,那万一路径错了怎么办?这是很有可能发生的。

中国人民大学高瓴人工智能学院教授卢志武
另外,要实现AGI,是不是也要研究大模型和机器人(具身智能)的结合?这也正好说明不能简单地堆算力、堆数据。如果从商业化的角度,单纯依靠Scaling Law肯定不行。所以,我还是相信Scaling Law非常有用,但是要在AGI上取得成功,在商业化上取得成功,它还是远远不够的。
张煜:从事物的发展角度来讲,任何事物都有一个极限,大模型也同样适用,所以它一定会发展到一个固定的极限。
但是这跟发展阶段有关,在大模型刚刚起步的阶段,我们大概可以把大模型曲线中很大的某一段拿出来当直线去看,当成有输入输出关系、有成比例关系的法则来对待,也就是我们今天的Scaling Law,因此短期方面肯定是有效的。

清智资本创始合伙人张煜
长期方面我也同意卢老师的观点。从性能本身讲,Scaling Law会有一些不可预知的问题发生,因此可能还存在更好的路径。比如要想登月,有两种方法:一种是爬树,每天在树上多爬一米,明天会比今天更接近月亮一米;另一种是造火箭,每天都停留在地面上,但是我靠爬树永远爬不到月亮上去,靠造火箭的方法一次成功了就发射到月亮上去了。所以Scaling Law和潜在的更好的路径需要两方面并重。
张俊林:Scaling Law其实是个经验公式,最初是OpenAI在2020年提出来的,现在大家遵循的应该是DeepMind在22年提出的Chinchilla Scaling Laws(Chinchilla Scaling Laws:为了使模型达到最佳性能,模型参数量应与训练集的大小成等比例扩张)。尽管它被称为Law,但它是通过大量的实验来得出的关于模型规模、训练数据增长和对应模型效果增长的关系公式。从现阶段来看,如果你承认DeepMind的实验是靠得住的,那么Scaling Law毫无疑问就是成立的,就是你继续提供更多高质量的数据、扩大模型参数,模型效果的确是在不断提升。

新浪微博新技术研发负责人张俊林
但是我觉得Scaling Law曲线的增长陡峭程度可能在放缓,我们可以用最近两天的例子来推断这个结论:前天OpenAI发布了GPT-4o,包括谷歌今天的I/O大会也发布了更强的模型。其实相比GPT-4o,我个人更期待GPT-5的出现,因为从GPT-5的能力能够评估我们目前阶段大模型的Scaling Law能达到什么状态。但是,ChatGPT发布已经一年半了,GPT-4在2022年就训练好了,目前已经经过了一年半到两年时间,GPT-5还迟迟没有出来,只是发布了更偏向多模态产品形态的GPT-4o,这多少是有点不太正常的,我猜测这可能是因为GPT-5在OpenAI内部的测试结果不满意,还需要想办法进一步提升能力后才发出来。而如果这个推论成立,那么很可能意味着Scaling Law增长速度在放缓。
那问题在哪里呢?我个人觉得可能还是出在数据上,可能还是数据不够用,原则上,根据Scaling Law,只要你数据量足够多,那他会沿着增长曲线继续往前走,现在Llama 3已经用了14T的数据,几乎达到了现在所有能用的数据,所以很可能是数据不足导致Scaling Law增长变缓慢。
罗璇:我是非常相信Scaling Law的,它本身并没有问题,如果现有的算力翻一亿倍,数据翻一亿倍,且所有的数据都是高质量数据,这样的模型效果一定会很好;
Scaling Law现在放缓的原因我觉得在Transformer这个神经网络架构上面。因为Transformer时间空间复杂度都非常差,导致算力和数据的利用率都非常低。所以如果当参数翻倍,你需要的数据和算力是二次方的增长;而且当现实世界的数据逐渐枯竭以后,所需要的合成数据的成本也是二次方的增长。

RWKV元始智能COO罗璇
如果Scaling Law是一个二次方的曲线,那么现在的资源确实卡住了Scaling Law的发展;但是大家看一个极端的情况——人。在过去几十年,人吸收的数据远远不到大模型现在训练所用的数据,说明人这样的“人工智能”对数据和算力的利用率是非常高的,那未来一定会找到一种新的算法,把数据和算力的利用率往这个方向发展。
2.数据挑战比模型挑战更大
王艺:现在合成数据是很多厂商解决数据瓶颈问题的主要方法,包括Llama 3也在训练数据集里加入了合成数据。合成数据会是解决数据问题的主要方向吗?
罗璇:合成数据在某些领域是完全可用的,比如以前的Alphago,其实就是用合成数据训练的;还有另外一类的模型,比如写小说的模型,怎么样去给它输入合成数据?在现有的生成式AI模型中,即使是文本大模型,要生成小说也需要一定的宇宙观,这是非常难的。
所以还是要看我们希望大模型生成的是什么样的数据,不同的数据对大模型的要求是不一样的。如果你需要模型生成那种“很容易辨别正确性”的数据,那合成数据马上可以落地;如果你需要模型生成一些“模糊的、很难判断正确性”的数据,那用合成数据生成可能很难。现在具身智能也想做合成数据,但是你很难判断使用合成数据训练的具身智能是否符合物理规律。
张俊林:如果数据就是决定文本大模型未来能力天花板的最关键因素,未来我们可能面临数据短缺问题,那么只有两条路能够驱动文本大模型继续往前走:
一条路是提高大模型对数据的学习效率。喂给模型的数据量大小是一样的,但是好的模型能够从同样的数据中学到更多的知识。这意味着我们在不扩充数据量的前提下就能继续提升模型效果,对数据量的需求就会降低,但是目前这条路上我个人并没有看到特别好的解决方案。
第二条路是继续喂给大模型新数据,但是已经没有更多可利用的人产生的数据了,那就只能依靠合成数据了。
至于合成数据的可用性,目前在有些地方还是用的比较成功的。举个例子,做大语言模型很多时候会做instruct-tuning,会人工制造“问题-答案”的数据对去调整模型,让模型理解人的命令。去年上半年其实很多厂商就开始拿到问题之后,让GPT-4给答案,然后用这些“问题-答案”数据去训自己的模型,这其实就是典型的一种合成数据的做法,应该说在这个场景还是比较成功的。
另外一个比较成功的例子是DALL-E 3和Sora的做法。它们之所以成功,跟怎么有效制作合成数据是有一定关系的。但DALL-E和Sora的做法可以看作“半合成数据”,而不是完全自动化的合成数据,这样更贴切一些。因为要训练多模态模型,DALL-E 3得有文本对应的图片,Sora得有文本对应的视频,必须得是成对数据。
DALL-E 3和Sora做了这么个事儿——它们把已经有的、人标好的“文本-图片”或“文本-视频”数据对里的文本部分用AI模型扩写,改得更详细、更丰富一些,然后再用扩写后的“文本-图片”/“文本-视频”合成数据去训练模型。所以它们用的合成数据其实不是靠机器完全自由生成的,而是在已有人工数据的基础上进行了进一步的改造。这算是一种“半合成数据”的做法,是可行并能产生好的效果的。
然后我们再讲“全合成数据”,想要完全用机器、不受限制地生成所需的训练数据,确实非常难。因为人产生的数据其实是有主题和自然风格的分布的,机器还难以做到自由生成并完全符合人类数据的分布,这个难度比较高。“全合成数据”我认为是个方向,但是业界公开的资料里还没有看到很成熟的做法。
王艺:卢教授的团队也在做多模态,您是用半合成数据的方法吗?在训练多模态大模型的过程中有没有用到合成数据?
卢志武:可以说合成数据,但我更喜欢称之为“数据生成”,数据生成不限定为非得是“合成”的。从数据生成的角度看,不仅仅是通过生成模型,还可以通过其他模拟器生成数据。比如在自动驾驶领域,仿真数据或合成数据有两个用途:一是在自动驾驶系统初期训练阶段,先在模拟数据上训练一个基本版本,然后再进行路测;二是处理自动驾驶中的bad case或corner case,即在现实中几乎不可能出现,但一旦出现就可能非常危险,这种情况只能通过合成数据来处理。所以,我认为合成数据肯定是有用的,关键在于怎么使用它。
王艺:corner case问题只能通过合成数据来解决吗?
卢志武:是的,corner case在自动驾驶中发生频率非常低,但一旦发生就可能造成严重后果,无法通过现实数据获取,只能通过合成数据来解决。所以,在极端情况下,合成数据是唯一可行的方法。
张煜:合成数据无论效果如何,都是一个必须要用的方法。
第一,因为数据量有限,刚才卢老师也讲到极限情况下数据样本很少,但是大模型高度依赖数据,必须通过合成数据来补齐;第二,合成数据的方法有很多,比如模拟方法或按物理世界规律生成的方法,这些方法决定了数据的可用性;第三,像AlphaGo那样通过自我博弈生成的数据在简单规则下有效,但在复杂规则下可能会产生不可预知的错误,所以使用全合成数据时需要小心一些。
罗璇:端到端合成优质数据的前提是,你要知道怎么端到端生成这个数据,所以模型能力要非常强。去年年初的时候我们就知道硅谷湾区在大规模使用合成数据。
侯震宇:合成数据现在几乎大家都在用,效果也很明显,生成数据的方式确实非常关键。很多情况下需要多个模型交叉生成数据,然后用这些数据训练另一个模型。对于训练过大模型的人来说,数据量、数据质量以及数据在模型中的分布都非常重要。所以某种层面上,如果你不想去训一个特别大的纯通用的模型,在某一个领域上你完全可以用一个更大的模型,或更大的几个模型去生成它所在领域的数据,现在很多人也在这么做。尽管如此,纯生成的数据并没有增加新的知识,还需要引入更多人工反馈,提升数据质量。
王艺:现在OpenAI和DeepMind关于Scaling Law有两种不同的思考的路线——OpenAI认为parameter要增加5.5倍,Token的数量只需要增加1.8 倍;DeepMind认为paremeter和token要等比例扩展,每个扩3倍。您更认同哪条路线?
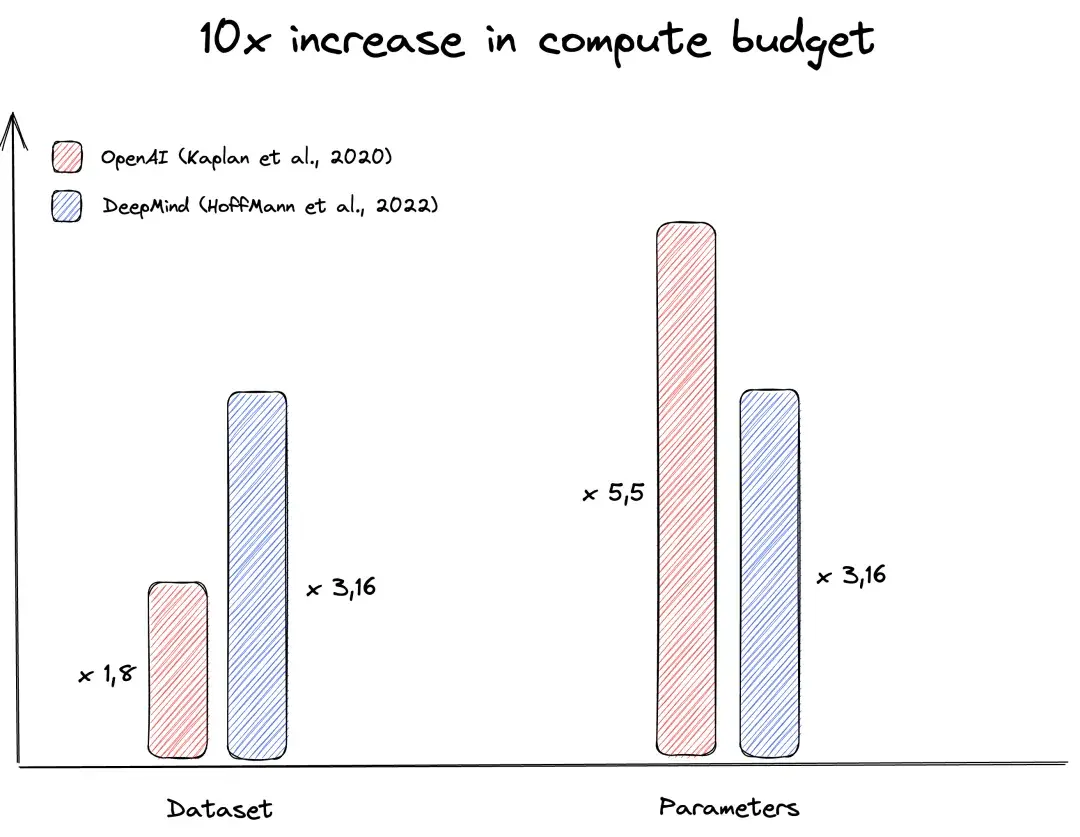
OpenAI与DeepMind对于参数量与数据量的不同配比
侯震宇:其实不能完全说数据和模型参数之间存在线性配比,因为很多知识在整个训练过程中并不是等价的、等比例的。比如,数学和化学的数据在训练中的比例不会完全相同。
当我们训练一个实用模型时,需要专门针对数据的分布进行设计。现在“如何去训一个模型”大体的思路已经比较清楚了,但是“如何去做数据工程”,还是一个很大的挑战。
特别是在讨论模型商业化时,Scaling Law依然在起作用,只是成本非常高。因此,我们需要在垂直场景中找到适合自己的数据分布,并设计出适合自己的模型,这是一种更加现实的做法。
3.Transformer是唯一解吗?
王艺:无论谈Scaling Law还是数据,其实都是基于一个大前提,就是生成式模型。但有一位AI大牛Yann LeCun一直在反对生成式模型,认为它不能真正理解世界。他觉得自回归方法缺乏常识、没有记忆、无法规划答案。因此,他提出了自监督路线的预测式模型(I-JEPA和V-JEPA)。你们怎么看待现在对自回归模型(next token prediction)的质疑?
罗璇:我其实非常看好杨立昆的方向,但具体是不是这样做的还可以再研究。Yann LeCun的世界模型一直是基于人理解世界的逻辑,但是现在的生成式AI本质上就是预测模型,只是单纯的预测模型并不解决理解物理世界的关键问题。比如,如果用模型去合成数据,但模型不理解物理世界,这样合成的数据是无法用于模型训练的。
还有一个关键点是如何更好地利用数据,包括合成数据和现有数据的高效利用。人脑理解世界并不需要那么多数据,所以一定会有一条新的路,让模型更好利用数据。
以及,Scaling Law在现实中存在一个限制,就是模型越大,推理成本越高,并且成本不是线性增长的,而是二次方增长的,所以现在大部分商业落地的问题就在于推理成本太高。
王艺:元始智能做的RWKV和Transformer具体有什么不同?
罗璇:RWKV和Transformer是完全不同的路线,核心是算法的计算复杂度不同。RWKV的推理时间复杂度是线性的,空间复杂度是常数。Transformer的KV cache不断变大,这就是Transformer吃显存的核心原因,它每推理一次都要遍历一遍所有的tokens。而RWKV会做一个固定大小的state存储KV cache,而且这个State 会有衰减机制,信息会丢失,从而保证state是固定的。
我们是最早做这个方向的,这个方向在去年下半年已经被海外的很多高校和公司验证了,比如有个模型叫Mamba,它其实就是RWKV第六代的变种;再比微软亚院和清华的合作项目RetNet,那个是RWKV第五代的变种。现在学术界已经认可这个方向可能能够推动下一步的Scaling Law。
王艺:你们现在有没有做一些实验,证明RWKV对于显存的消耗确实没有那么大?
罗璇:有两块,第一个是我们的论文上面已经做过测试,用Flash Attention V2来做的话,相同的上下文,比如 4096 tokens,RWKV占的内存只有Transformer的50%左右;第二,在海外有商业公司用类似于RWKV的架构训练了模型,比如说以色列公司AI 21 Labs,包括Meta和DeepMind最近出的混合模型也是用了类似于RWKV的架构,所以这个在工业界也得到了验证。在美国,也有团队在用我们的架构训练70B的模型。
王艺:除了罗总提到的RWKV、Mamba、Retentive Network,还有其他更好的模型架构吗?
张俊林:现在业界无论是提出全新模型,还是在Transformer基础上改进,要解决的根本问题其实是相同的,都是解决Transformer在推理阶段长上下文处理时的内存和时间消耗问题。
如果归纳新架构的一些做法,我认为有两个不同的方向,但可能殊途同归。一种是从RNN入手来改出新模型,另一种是从Transformer入手直接改它的缺点。RNN类新模型的好处是推理效率特别高,内存占用少、计算量低,这是它的优点;它的问题是模型训练效率低、并行度差,尤其当训练数据量变大,这个问题就会很突出。Transformer的优劣势正好和RNN相反,它在训练时候并发度高、训练效率高,它的并行架构导致数据量大的时候,训练效率比RNN类改进模型好很多,效果也比较好。而Transformer的问题在于它的self-attention机制,推理的时候每生成一个token都要遍历所有前序的token,导致模型推理的时候KV Cache消耗的内存高、计算量大,尤其当输入上下文比较长的时候,这个问题就很突出。
与从RNN入手相比,我个人更倾向第二种方案,就是基于Transformer去改造模型来提高它现有的推理效率问题。现在这方面的具体做法有很多,效果也不错,所以我们看到谷歌Gemini已经能在推理的时候支持二百万长度的上下文,而随着技术进步,这个长度应该很快能拓展到五百万、一千万甚至更长,把上下文做长目前看不是很难解决的技术问题。
总之,无论从RNN出发,还是从Transformer出发,这两种思路应该都可以,也存在相互借鉴,最终很可能会经过相互借鉴后形成融合。
4.MoE、长文本与多模态
王艺:你怎么看待MoE(Mixture of Experts)模型?
张俊林:我觉得MoE模型是在模型规模变大时不得已或者说不得不做出的选择。
Scaling Law代表的趋势是,如果想要做最好的模型,就得增加数据量和模型规模。因为当数据量和参数量增加,训练和推理成本也会增加;MoE相对Dense模型的优势是训练和推理成本非常低,所以当模型规模特别大的时候,出于成本考虑,你不得不选择MoE。
我觉得MoE是一种“想得很好但是做得不够好”的一种模型,就其设计初衷来说是非常好的——有多个专家,每个专家处理某个领域的问题,“专业的人做专业的事”;但是,这是理想,在实际训练中很难保证能做到这一点,甚至可以说,目前基本还做不到这一点。目前的MoE更像是一种比较灵活的集成模型(Ensemble Model)。当然,在成本和效率方面确实MoE有优势。
王艺:MoE不是最优解,是次优解。结合Transformer和RNN的优势会更好。RWKV模型是不是结合了这两者的优势?
罗璇:短期内,在100B以内的模型,RWKV的线性attention和Attention-2的混合会是最优解,无论在效果还是性能上都是最优的。超过100B以后,RWKV的state记忆已经足够强,不需要再加attention。这是我们的测试结果。
王艺:现在各家都在卷长文本,但是长文本确实很耗费显存,除了LoRA,还有没有一些新的架构,解决Transformer对硬件资源的消耗问题?
张俊林:这是一个纯技术问题,随着多模态模型的推广和普及,long context是很有必要的。比如,我希望模型能够理解一个视频,输入的context必然很长,这就面临KV cache特别大的问题。那么怎么解决这个问题呢?现在有很多解决方案,可以归纳为两种大的思路:
第一种思路是直接对KV cache下手,减小其模型的大小。比如,可以用模型量化或压缩的方法。有个工作对KV Cache做3bit量化,可以做到GPU单卡处理1百万Token长度的上下文。DeepSeek v2里引入的对KV 做类似Lora的低秩分解效果也很好,这是模型压缩的路子。很多方法还可以一起用,总之,大部分对大模型参数进行压缩的工作,原则上都可以经过改造迁移到KV Cache上来。
第二种思路是直接对输入的context进行压缩,而不是压缩模型内部的KV cache。这种方法有很多具体做法,但核心思路都差不多。现在RAG(Retrieval-Augmented Generation)是大模型应用的标配,即把很多内容放在外存数据库里,需要时根据prompt取回相关的部分,从而减少输入的长度。第二种方法在概念上可以理解为把RAG放到内存中,在内存中维护一个memory,把长的输入切成块放到memory里,相当于内存版的RAG。谷歌前一阵子推出的支持无限上下文输入的工作基本思路也是类似的,效果也不错。
总结起来,解决long context问题主要有这两种思路:一是减小KV cache的大小,二是压缩输入的context。
王艺:卢老师在四年前就在智源研究院做了中国最早的多模态大模型文澜BriVL,后来又做了视频生成模型VDT,比Sora更早。大模型现在的融合还不彻底,理解和生成是分开进行的。如何解决这一问题?
卢志武:多模态大模型中,理解和生成确实要分开,因为它们的应用场景不同。理解模型主要是与智能硬件结合,像无人机、机器人、摄像头等,在很多to B场景中已经探路成功;生成模型主要是用于视频生成、3D生成,这些应用场景可能更多是to C。它们面对不同的商业场景,硬要放在一起不太合适。从模型或架构角度看,理解和生成硬放在一起效果确实不好,像Google Gemini也是把理解和生成分开的。
王艺:也就是说,现在分开才是主流,融合反倒不是。
卢志武:对,从一些成功的例子来看,分开是更好的选择。
5.如何把算力变便宜?
王艺:虽然Scaling Law是个很好的定律,但是它太耗费算力了。目前现有的算力能否满足下一个阶段人工智能发展的需求?作为算力的提供方,百度是怎么降低成本的?
侯震宇:首先,在Scaling Law下,即使单个算力价格、单张卡的价格再便宜,总价也会很高。所以,尽管我们认可Scaling Law的发展趋势,但我们不建议小公司去卷入大模型的训练,因为这是一个巨大的成本。
百度一直有个观点:虽然我们认可Scaling Law的发展,但不建议更多的公司,特别是一些创业公司,去卷入基础大模型的竞争。基础大模型的规模和成本对小公司来说是难以承受的。真正能够创造价值的其实是最终应用在AI原生的场景上。当你在AI原生应用上能赚到钱,商业逻辑才能成立,你才能承担这些费用,进而去训自己的模型。我们鼓励大家更多地利用基础云算力和模型能力,走向上层应用。
事实上,当算力资源很贵时,我们应该如何更高效地利用它。当使用超过1000张、5000张、10000张卡时,单一任务跑集群会有大量故障。许多客户能搭建2000、3000张卡的集群,但能跑起来就很困难。如果跑不起来,不管多便宜都是浪费。所以我们帮助大家解决故障检测问题,故障发生后迅速识别并排除,重新跑任务。我们在万卡的单一任务集群上实现了98.8%的训练任务有效率,这其实是一个很高的水平。
另外,在训练上,目前的MFU(Model FLOPs Utilization)大约为50%,后续还有很多优化空间。不管是长文本还是MoE(Mixture of Experts),对资源的使用都不是特别友好,所以无论是在在显存KV cache、还是计算通讯重叠设计上,我们都有大量的工作要做。当涉及到10万卡集群时,我们会面临更多问题,包括电力问题等。我觉得在整个系统层面上还有很多优化空间。当然,是否有突破Transformer架构的可能性,这些都是需要认真考虑的。
王艺:今天上午火山引擎在发布会上说,字节大模型每千tokens是0.0008元,比市面上低了99%。百度的token在价格上能比过他们吗?
侯震宇:今天上午火山刚发布,我们也在关注。当然我们不评价友商,我们最终看重的是效果。所以大模型的效果、调用费用,以及承担大模型训练或推理的裸算力费用,都在持续发展。Scaling Law的整个篇章其实从去年才真正开始。两年前,一两亿参数的模型也被称为大模型,所以整个领域还在持续发展。这真的是AI发展的黄金时代,我们可以看看几大厂商接下来的布局。
6.创业公司的机会在哪?
王艺:在大模型创业的时代,有一种声音认为这是大厂的天下,因为大厂有钱、有资金、有技术、有资源。清智资本作为一个投资孵化器,被称为中国的YC,是怎么看待大模型竞争中创业公司的机会的?
张煜:从过去的发展来看,每个时代都有自己的标志性企业,所以我相信新兴的企业会不断涌现,并替代今天的传统企业。当然,在AI时代创业确实更难,因为创业成本太高了,需要算力、数据、电力等外界条件,这些条件占据了很大的成本比例,导致创业更难。
在AI的所有生态上,包括算法、算力、数据、系统和应用都有大量机会。最多可能的机会还是在应用端,现在许多创业者有自己的行业知识,加上现有的大模型能力或AI能力,就能建立很好的竞争壁垒。在to B领域,因为各个行业都有不同的行业知识,这些知识的数据相对有行业壁垒,使得行业创业者更有竞争力。
从大模型本身的角度,可能更多是一个“赢家通吃”的局面。现在的“百模大战”很多都是做AGI通用模型,但最终可能只剩下几个主要的模型厂商。很多大模型厂家是我们的合作伙伴,目前都在发展阶段,不太好评价未来,百川智能是从我们清智孵化器成长起来的,我们观察感觉技术领先和快速商业落地的创业公司更有机会。
我们看到的优秀项目还是挺多的,比如卢老师的项目和罗总的项目,都特别亮眼。我们投的第一个项目是华深智药,从蛋白质生成出发,在AI驱动的大分子制药领域走到世界前列,已经拿到顶级国际制药厂的订单。我认为在科学技术变革和转型的时代,最可能会出现特别亮眼的创业项目,尤其在AI科技高速发展的时代,各种应用都在以各种方式同AI紧密结合,希望我们投资人和创业者共同发掘下一个激动人心的应用。
7.对大模型的未来畅想
王艺:请每位嘉宾聊聊对大模型未来的畅想,或者对未来大模型商业化的畅想。
罗璇:我非常看好未来的人工智能。未来的AI会有新的架构、新的算力,合成数据会更加优质。未来在端侧,手机、XR、机器人、车上可以运行100B以上的模型,云端是10T以上的模型,创造完全不同的AI。另外,AI不再是单纯依靠数据拟合,而是真正掌握世界规律甚至宇宙规律的AI。未来的AI得出的结果是可追溯、可解释的,而不是现在这种充满幻觉的AI。
张俊林:一方面我觉得我们现在处于一个全新的时代,每个人需要找到自己合适的位置。另外一方面,最近两年可能会是最关键的两年,对AGI和大模型来说都是如此。当数据快用完时,如何解决危机,包括GPT-5出来之后的数据危机怎么解决,这些都会决定AGI能走多远。所以我们应该密切关注最近一两年的业界进展。
张煜:我关注几个问题。首先,大模型可能可以解决过去无法解决的一些问题,比如健康问题。我们能否发明未来的抗体,通过AI结合分子动力学、生物进化学等来模拟、预测病毒演化的过程,提前研发出抗体来。这是很有意义的事情;第二是人类寿命问题。人类寿命大约100年,那么限制寿命的要素在哪里?肯定在基因上。用大模型分析和改造基因,可能解决这个问题;
还有模型和模型之间的对话机制。现在大家都用数据做训练,很多数据是重复的,训练重复性也很高,造成资源浪费、效率也不高。能否让模型之间可以对话,像人类一样传递认知和推理逻辑,而不用重复数据训练过程。
最后,未来大模型最好能解决科学发现的问题。过去200年,数学和物理进展不大,一种可能是因为人类的知识逻辑能力到了瓶颈。大模型能否在海量数据训练的基础上做推理,发现我们过去发现不了的科学规律,这是更有意义的方向。
卢志武:我对多模态大模型的理想是中国的老话——顶天立地。在技术探索上,希望能做得比美国还强,至少在方向上要保持领先。从落地的角度,希望我们的应用有真正的价值,有人愿意为应用付钱。
侯震宇:我有两个期待。第一是作为多年做系统架构的工程师,现在确实是架构的黄金时代,因为如果要训一个这么大的模型,从机房到芯片、网络协议、系统,都需要重新设计,包括训练框架和Transformer模型,这是技术狂欢,希望能持续高速发展并带来效果。
第二是模型训练出来后要进到应用中,才有意义。我经历了国内互联网和移动互联网的发展,也期待这一轮AI原生的发展,能够让AI原生应用爆发,形成繁荣的中国AI应用生态。
END.
免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。

