
汽车界“印钞机”,保时捷也绷不住了
美女学霸空降!华福证券,杀疯了
来源丨硅基见闻
近日,AI 开源社区因一场围绕数据抓取与镜像平台的争议而引发广泛讨论。
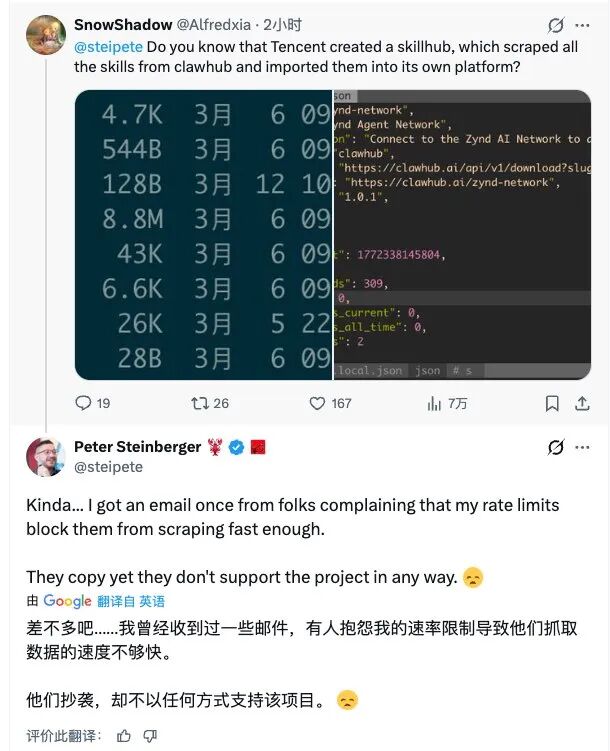
开源项目OpenClaw创始人Peter Steinberger在社交平台公开指责腾讯团队未经沟通大规模抓取其技能库ClawHub的数据,并将其同步至腾讯自建平台SkillHub。
这一事件迅速在开发者社区发酵,再次引发关于开源许可、商业使用以及社区文化边界的讨论。
1
创始人指控:大规模抓取导致服务器成本飙升
OpenClaw 是一个面向 AI 工具与自动化技能的开源平台,而 ClawHub 则是其核心技能库,开发者可在其中发布各类 AI 插件、自动化工具和 Agent 技能。
据Steinberger表示,近期ClawHub的服务器流量出现异常增长。经过排查,他发现部分高频请求来自腾讯团队的自动化抓取程序。
Steinberger称,腾讯团队曾通过邮件抱怨ClawHub设置的访问速率限制过于严格,影响其数据同步速度。
Steinberger指出,由于大量数据请求,ClawHub的服务器费用迅速上涨至“每月五位数美元级别”。
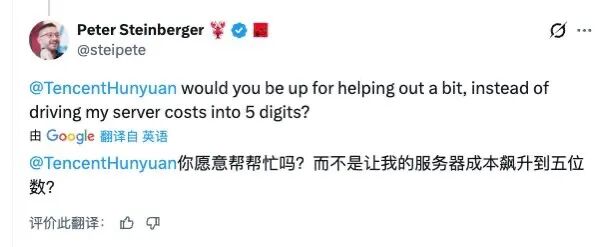
他表示,腾讯在进行大规模数据抓取前并未提前沟通,也未提供任何形式的技术或资金支持,因此决定公开表达不满。
该帖子发布后,迅速在开发者社区引发讨论,一些开发者认为大型科技公司在使用开源资源时应承担更多责任。
2
腾讯回应:SkillHub是本地镜像站
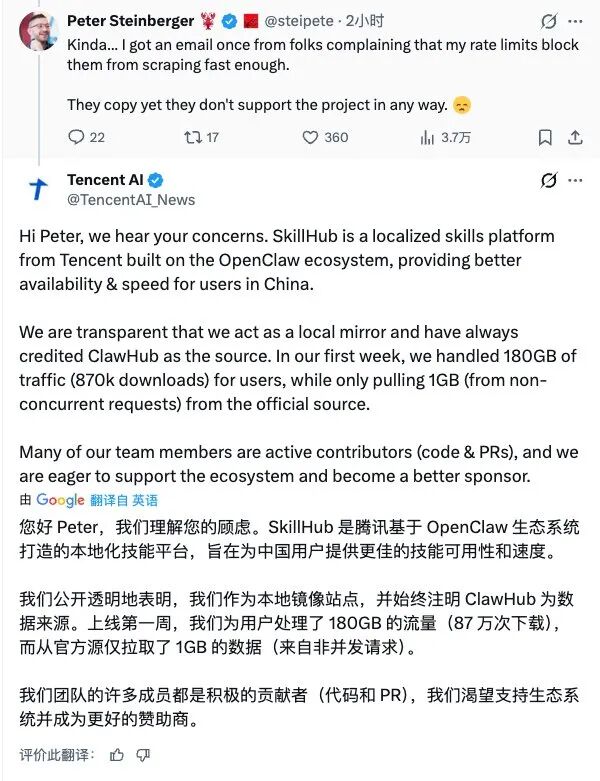
针对争议,腾讯随后作出回应。腾讯表示,SkillHub的定位是OpenClaw生态的中国本地镜像站,目的是提高国内开发者访问速度,并非竞争性产品。
腾讯团队公布的一组数据称:
•SkillHub上线首周共向用户分发约180GB数据
•但从ClawHub官方源同步的数据约为1GB
•同步请求为非并发抓取
腾讯方面还表示,SkillHub页面已明确标注ClawHub为原始来源,并强调腾讯团队成员本身也是OpenClaw的贡献者。
同时,腾讯表达了愿意成为该项目赞助者的意愿。
3
开源许可与社区文化的边界
从法律层面来看,开源协议通常允许复制、抓取和再分发代码或数据资源,因此类似行为在许可框架内往往属于合法使用。
但在开源社区内部,开发者更强调 “社区礼仪”。许多项目维护者认为,当大型公司从开源生态中获得商业价值时,除了遵守许可协议,还应通过赞助、贡献代码或提前沟通等方式回馈社区。
因此,本次争议的核心并不在技术实现,而在于开源生态中的 责任与合作模式。
4
AI开源生态中的典型摩擦
分析人士指出,随着 AI 工具和 Agent 平台迅速发展,越来越多创新项目由小型开发团队维护,而基础设施成本却不断上升。
与此同时,大型科技公司对开源生态的依赖程度也持续加深。
在这一背景下,围绕镜像站、数据抓取和商业利用的争议可能将更加频繁。
目前来看,双方态度均有所缓和。腾讯表示愿意提供赞助支持,而 Steinberger 也未排除未来合作的可能。
业内人士认为,此次事件很可能不会演变为长期冲突,但它为 AI 开源生态提出了一个重要问题:在技术许可之外,如何建立更加稳定和公平的社区合作机制。
深蓝财经新媒体集群发源于深蓝财经记者社区,已有15年历史,是国内知名财经新媒体,旗下账号关注中国最具价值公司、前沿行业发展、新兴区域经济,为投资者、上市公司高管、中产阶级提供价值内容,欢迎关注。
