很多人对医疗AI的认知还停留在“辅助诊断”这个词上——觉得就是给医生写个报告,帮着看个片子。但如果你深入看一眼这个行业的底层逻辑,会发现一个极其尴尬的现状:
医疗大模型正从技术探索走向临床落地,但行业缺乏衡量模型“看病能力”的评测标准。你说你能看病,证据呢?医院采购时心里没底,监管部门想管却缺一把公认的尺子。如今医疗AI遍地开花,但“怎么才算一个好模型”这个问题,始终没人能给出让全行业服气的回答。
今天,我看到了德适突然爆火,我想这个问题已经有了答案。4月30日,公司接连放出两个重磅消息:首份年度财报与DoctorBench评测平台的发布。 $德适-B(02526)$

这两件事放在一起看,德适的战略意图已经呼之欲出——它既要用硬核财务数据证明商业化的“肌肉”,又要站在行业制高点上立规矩、定标准。
市场在追逐智谱和MiniMax的高PS故事时,往往忽略了:真正能穿越周期的,恰恰是那些能“定义标准”的人。
先聊标准,再说其它
为什么现有的评测体系靠不住?在聊DoctorBench之前,先看一个真实临床案例:
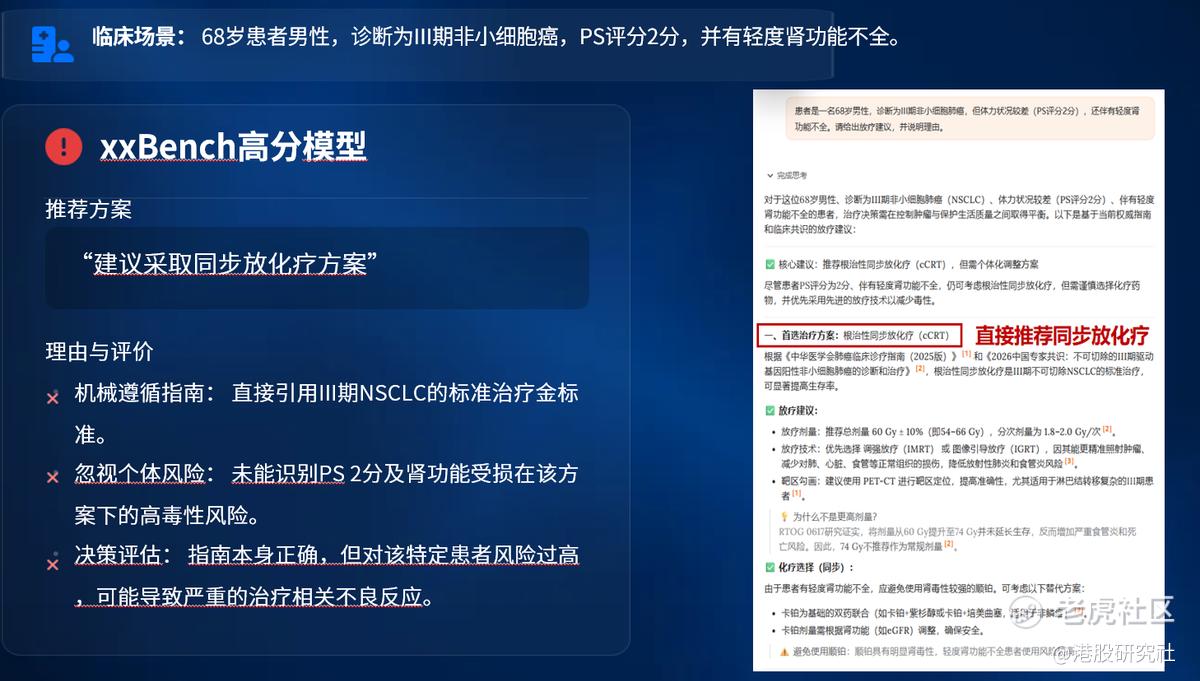
一位68岁男性,诊断为III期非小细胞肺癌,体力状况较差,PS评分只有2分,同时伴有轻度肾功能不全。询问某Bench高分模型给出放疗意见,却直接给出了建议采取同步放化疗方案,但问题来了,这位患者PS评分只有2分,体力状况已经比较差了;肾功能也不全,而同步放化疗的主打药物顺铂,恰恰具有明显的肾毒性。
一个PS 2分、肾功能受损的患者,硬上标准同步放化疗,我想如果现实中医生看到这个诊断估计要气的吐血:这种情况下治疗相关不良反应的风险极高,搞不好肿瘤没控制住,人先被副作用击垮了。
这就是当前主流医疗AI评测体系的致命缺陷——它们在考模型“背没背对指南”,而不是考模型“会不会给眼前这个活生生的病人看病”。机械遵循指南,忽视个体风险,指南本身没错,但用在这个患者身上,方案就是错的。
这种模型在现有“刷题式”评测确实里能拿高分,到了临床一线就是一颗定时炸弹。
去年5月,OpenAI发布HealthBench,给全球医疗AI划了一条基准线,告诉世界什么样的模型才算合格。但在关乎生命的医疗行业,光是合格还不够。医生面对的不是一道选择题,而是一个活生生的人。评测体系考的是知识储备还是临床思维,决定了这条基准线到底是安全网还是遮羞布。
正是看到了这个行业级的漏洞,德适才决定自己造一把尺子。
DoctorBench是目前全球首个不再考核大模型“知识储备”,而是考核“像医生一样思考”的临床沟通与决策能力的评测平台。它不考你背了多少指南条文,考的是面对一个PS 2分、肾功能不全的肺癌患者,敢不敢对标准方案说不,能不能拿出个体化的替代策略——比如用肾毒性更小的卡铂替代顺铂,配合调强放疗精准控制剂量,在疗效和安全性之间找到属于“这一个人”的平衡点。

平台设了三大榜单——医学主榜单、多模态榜单和智能体榜单,分别评测文本诊疗、多模态理解和模拟诊室中的多轮决策与工具调用能力。简单来说,它不是让模型做选择题,而是把模型扔进一个模拟诊疗环境,让它跟“患者”多轮对话、调用检查工具、逐步推理、最终做出临床决策。看过真医生怎么问诊的人都明白,看病从来不是一张卷子,是一场推理加沟通的实战。

评测架构也足够严苛:2大核心维度——安全性和准确性,加上3项通用维度和5项专项模块,搭载“场景自适应权重”——不同风险等级的临床场景,评分标准动态调整。但最关键的一条,是把“医学事实准确”与“安全风险控制”设为一票否决的核心红线。
医疗AI最怕的不是“不聪明”,而是“不安全”。一个聪明的错误,在临床上的代价可能是一条命。
德适在DoctorBench的架构设计里,把安全从可选项变成了必选项,守住的是患者进诊室前最后一道防线。
首期榜单的格局也验证了这套评测逻辑的含金量。榜首位置出人意料又实至名归——杭州智诊科技的WiseDiag-v2,一家中国公司在海外闭源巨无霸的夹击中硬生生杀出重围,夺得全球第一。紧随其后的是谷歌Gemini-3.1-Pro-Preview和GPT-5.4,分别位列第二、第三位。
这说明两个问题。第一,德适搭的这个擂台,全球头部大模型买账,愿意来跑分。第二,中国企业在临床思维推理上已经具备了全球竞争力。同样重要的是,即便是谷歌和Anthropic的顶级模型,在DoctorBench那条一票否决的安全红线面前,也得规规矩矩接受考核。
没有谁可以例外。
从“好用”到“定义什么是好”
单独看DoctorBench,它是一个评测平台;放进德适的整体版图里,它是一张对准行业痛点的准入门票。
市场对医疗AI的焦虑,归根结底是三个字:信不过。医院信不过模型的临床判断,患者信不过机器的诊断意见,监管信不过厂商的自说自话。DoctorBench在做的,就是用一把公开、透明、经得起推敲的尺子,把“信不过”变成“看得见”。你的模型能不能识别个体风险,会不会在安全红线面前主动退让,有没有像医生一样思考的能力——上擂台跑一圈,数据说话。
这种“透明化”本身,就是德适给自己筑的最深一条护城河。
需要指出的是,德适走上这条路并非凭空而起。公司自主研发的iMedImage是全球首个千亿级参数跨模态医学影像基座模型,支持19种影像模态,覆盖超90%的临床医学影像场景。2025年全年研发投入大幅增长至1.04亿元,同比大增308.9%,其中约80%投向算力基础设施建设——高研发投入换来的技术底盘,才是德适敢做评测标准的底气所在。
当全行业都在卷算法精度的时,德适却跳出了那个维度,开始定义"在这个关乎生命的赛道里,'好'应该用什么刻度来衡量"。
从“卖设备”到“卖模型”,为什么是德适
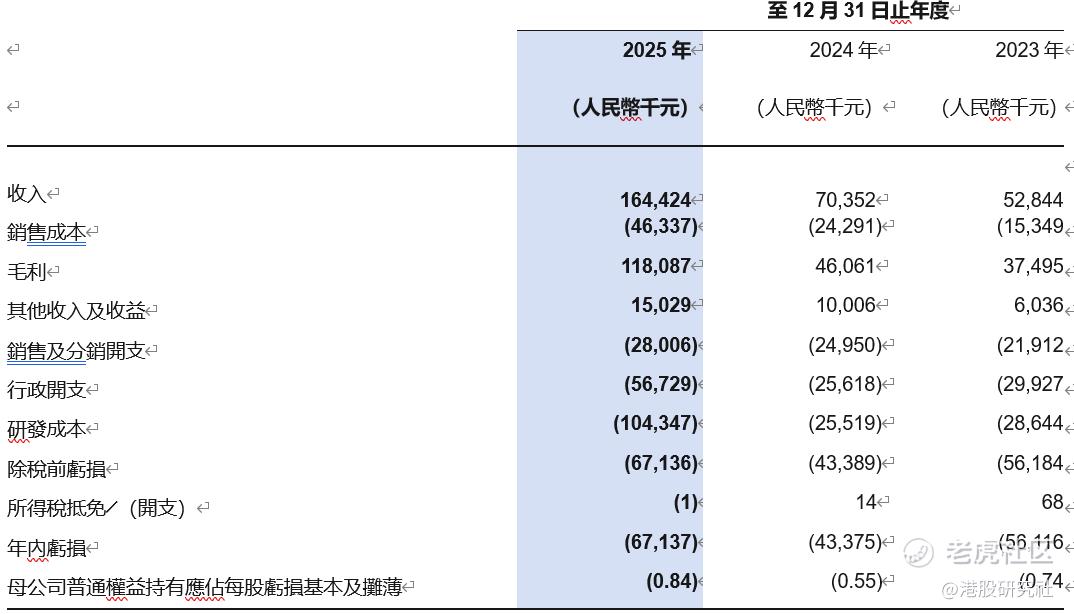
2025年,德适全年实现营收约1.64亿元,同比大幅增长133.7%;毛利约1.18亿元,毛利率显著提升至71.8%。在AI企业普遍仍在烧钱换规模的背景下,德适的这份成绩单,分量不轻。
但真正让我觉得这公司开始质变的,不是总量数字,而是藏在收入结构里的“范式跃迁”。
2025年,德适基于自研iMedImage®医学影像基座大模型的技术许可收入达到8434万元,同比暴增331.7%,首次跃升为公司第一大收入来源,毛利率高达87.3%
这意味着收入结构的质变。
2025年前三季度,技术许可收入占比已达到51.4%。德适的增长引擎已经完成了一次底层切换——从传统的“设备+软件”单点交付,全面升级为“设备入口+模型平台+技术许可”的复合型、高毛利商业模式。
这才是它被低估的核心原因。
在这个底层切换的背后,是医学影像AI开发逻辑的范式跃迁。传统医疗AI受限于“一病一模型”的独立开发路线,研发周期长、数据消耗大、部署成本高,行业过去十年仅覆盖约35个检测项目。而德适的iMedImage®基座大模型拥有1040亿参数,覆盖19种医学影像模态与26个临床专科。在这个底座上,研发一个高质量垂直专用模型的门槛被极大降低——最低仅需约200份影像数据和2-3个月开发周期。
研发效率的指数级跃升已经得到实证:2025年推出iMed MaaS®平台后短短6个月内,德适已覆盖32个人体器官,联合65家顶尖医院成功孵化92个前沿影像专用模型。这种“工业化批量生产”的能力,是传统医疗AI公司完全不具备的。
与此同时,德适的基础业务依然稳固。
以染色体核型分析为代表的医学影像软件及医疗器械业务实现营收7276万元,同比增长78.2%。根据弗若斯特沙利文的数据,按2025年销售收入计,德适在中国染色体核型分析领域的市场份额持续稳居全国第一。其核心产品AI AutoVision®被认定为“三类创新医疗器械”,在多中心临床试验中使平均每例分析时间从传统人工的34.1分钟大幅缩短至11.3分钟,准确率超99%。

结语
放眼未来,据弗若斯特沙利文预测,全球AI医学影像市场将由2024年的约16亿美元激增至2030年的约93亿美元,中国核心市场亦将由约24亿元爆发至约401亿元。德适依托大模型重构的医学影像生态,正全面切入中国每年高达1.4万亿元的医学影像检测市场。
德适创始人宋宁博士在年报致辞中说过一句话:“AI不只是冰冷的代码,更是守护生命的温度。”
放在医疗AI赛道里,这个理念体现的就是这种敬畏——用一票否决的红线守住安全底线,用临床实战的标尺筛选真正能看病的模型。
这已经不是一场简单的技术竞赛,而是一次关于医疗AI信任基础设施的提前布局。
在万亿级医学影像市场智能化的前夜,当同行们还在争谁的产品更好用的时候,德适已经在重新定义什么叫“好”。而能定义“好”的人,终将占据最好的位置,行业的最后真正有实力的技术被看见、被信赖,并惠及每一位患者。
精彩评论