
与 DreamDojo 一作拆解 “世界模型” buzzword。
文丨实习生付自文
访谈丨程曼祺
过去一年,“世界模型” 成了 AI 圈最热、也最容易被滥用的概念之一。
它边界很宽:视频生成模型可以被称为世界模型,因为它似乎学到了物理规律;自动驾驶领域也需要世界模型,因为要预测道路环境的变化;机器人研究者也在谈论世界模型,因为机器人需要在开展行动前先预测后果。
本期《晚点聊》,我们试图把这个概念拆清楚。
对谈嘉宾是高深远,一位刚从港科大博士毕业、即将正式加入英伟达具身智能实验室 GEAR 的年轻研究者。他从 2024 年以来持续研究世界模型,早期做自动驾驶方向,后来在英伟达 GEAR 参与 DreamDojo 和 DreamZero 等工作,是 DreamDojo 的联合一作。
DreamDojo 是一个服务于 Physical AI 的世界模型;DreamZero 则是一个可能替代 VLA(视觉-语言-动作模型,visual-language-action model) 的新的机器人策略,被称为世界动作模型(WAM,world action model)。
本期前半段,我们梳理了世界模型的大图景,以及 Google DeepMind、NVIDIA、World Labs 等主要团队的各自思路。
后半段,我们进入 GEAR 的具体实践。高深远认为,世界模型的核心价值不只是生成真实视频,而是构造一个自进化闭环:世界模型(DreamDojo)预测世界,policy(DreamZero)产生动作,Agent 负责规划和评估。
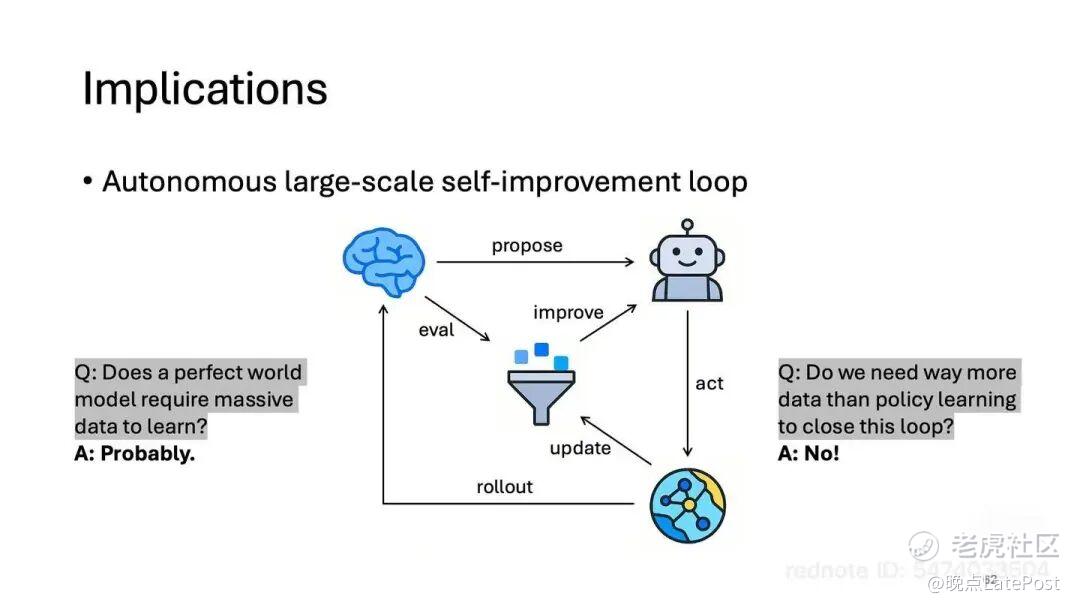
图中大脑代表 agent,机器人代表 policy,地球代表世界模型,中间是数据集。世界模型的输出(对世界下一刻的预测)是 agent 的输入,供 agent 给预测打分,打分可用以优化 policy;同时世界模型的输出也是 policy 的输入,而 policy 的输出(动作)是世界模型的输入。同时,agent 也给 policy 做任务规划。世界模型到 agent 和 policy 是用视频 / 图像通信;policy 到世界模型是用 action 通信;agent 到 policy 是用文本通信;agent 优化 policy 可以是一个打分数值,也可以是由文本媒介转过来的一种分数信号。
这个循环今天还没有真正转起来,因为这 3 个组件的泛化能力都还不够。但如果未来能进入相互强化的正循环,机器人就能像 AlphaGo 那样在虚拟环境下、突破物理限制快速迭代。
这既会服务于机器人、车辆需要的具身能力的训练;也有更多的可能性,比如缩短试验周期、并发地做实验,服务科学发现。
按领域、按表征,世界模型的分类
晚点:世界模型这个词很大,也是现在 AI 领域典型的 buzzword(流行词),做游戏、自驾、具身智能的人都会提到。你作为研究者,会怎么给世界模型分类?
高深远:从上往下可以分成两类。最 high level 的是用一个 model 模拟环境去做决策;另一类是做基模、多模态,有 world knowledge,能回答各种问题,也叫世界模型。
做决策的人更关注一个预测未来状态的模型,而且预测过程受条件控制,这个条件一般就是 action。简单说,它根据过去的历史和所做的 action 预测未来。
世界模型变热,和 Sora 这样的视频生成技术有关。OpenAI 当时说 Video generation models as world simulators,也就是模型用不同 text 控制未来画面,这个 text 也可以看作一种 action,是对世界的编辑或干预。所以很多做 VideoGen(视频生成)的说自己在做世界模型。
但真正对决策有用,光用 text 控制是不够的。就像机器人输出的是 action,游戏角色输出动作或技能,自动驾驶输出自车轨迹(Ego-vehicle Trajectory,自动驾驶系统对本车未来运动路径的预测或规划)。
晚点:你刚刚说的 action,包括文本指令、车的轨迹、机器人动作。如果从 AI 或计算机科学角度,更准确描述,action 是什么?
高深远:action 就是对世界的一个干预。世界状态可以是画面或其他表示。action 输入之后,会对这个世界产生影响。
晚点:那 action 的主体是不是要区分?比如车和机器人在世界里是主体,但视频生成,用户输入文本更像 “上帝视角”,这该怎么区分?
高深远:构建决策智能体时,一般只关心自身 action。比如具身智能的一个本体,很难凭自己的意志改变别人。
世界模型可以接受对其他 agent 或者环境的编辑。比如自动驾驶或者游戏场景,Multi-agent(多智能体,多主体交互系统)或可控环境的世界模型很有用。但对通用智能体来说,目前还是只能控制自己的 action。
晚点:现在讨论的还是单个机器人,但如果未来真的像马斯克说的,有一百亿台机器人,可以互相联网通信,那它们会组成一个更复杂的世界系统。
高深远:从安全和决策质量的角度考虑,肯定能通信是更好的。长远看,Multi-agent 的世界模型确实有必要。但从通用性角度,现在还不能假设机器人部署到任何环境里都互相通信,所以自身的世界模型还是最基础的。
晚点:当年的自动驾驶路线也有类似讨论。中国曾经有车联网的创业项目,比如在路灯上装激光雷达,让环境给车信号,不完全靠车自己适应环境。但后来主流还是发展单车智能。
高深远:国内有基建优势,V2X(vehicle-to-everything,车与外界对象通信)当时很火,现在可能也还在推。但从通用性角度,还是先开发自身智能比较好。
晚点:你可以继续说世界模型的分类。
高深远:按表征来分会比较清楚。世界模型核心就是 action、condition 和要预测的 world state。world state 有不同表征。
第一种比较抽象:用几何图结构表征世界。好处是模拟高效,只需要矩阵乘法,也不需要特别多数据。但泛化性不够好,不同性质的物体可能都要专门定义粒子表征。
第二种是显式 3D 表征,比如李飞飞老师的 World Labs。把世界重建成 3D 表示,比如点云(刻画物体几何表面的离散三维坐标点集)、3D Gaussian Splatting(用 3D 高斯表示并实时渲染场景的方法),或者 occupancy(占据表示,描述空间是否被物体占用的概率模型)。用 3D 表示可以很方便地操控物体、做空间编辑,而且一致性很好,因为有绝对坐标。但决策最终依赖的还是观测,所以它要先重建 3D,再渲染成 2D 画面。这个多阶段过程不太容易 data driven(数据驱动,主要依赖数据学习规律),也通常需要 3D 标注,不是完全 end-to-end(端到端,从输入到输出由同一训练目标整体优化)优化。
第三种是 Yann LeCun 推的隐空间表征,代表是 JEPA(Joint Embedding Predictive Architecture,联合嵌入预测架构)。它学习一个表征空间,比视频更紧致,易预测,计算量少,也更偏与决策相关 high level 信息。这个思路就像人在街上走,不需要精准预测每个行人的脸,只要知道大概有个人,就足够决策。但要先构建这个隐空间,而且要和其他决策模型接起来。评测和使用问题,都会带来障碍。
我自己更相信视频表征,也就是直接预测 video,输入输出都是 video。它是端到端的,可以直接用互联网视频训练。现在 video model 已经有能力预测很多细节,而细节预测本身也是采样,不一定会拖累决策。
简单说,世界模型大概分成四派:抽象表征、显式 3D 表征、隐空间表征、视频表征。目标都是用 action 控制预测,再做决策。
晚点:你最相信的视频路线,是不是包括你们做的 DreamDojo?Google 的 Genie 系列应该也算?(注:DreamDojo 是 NVIDIA GEAR 等团队开发的机器人世界模型;Genie 是 Google DeepMind 的交互式世界模型系列。)
高深远:对。视频模型可以用数据驱动方式 scale up(扩大模型、数据或算力规模)。从视频出发,模型本身已经对世界有很好的理解。
包括具身智能,我觉得通往 AGI 的思路,是从数据非常多的 domain 开始,再往数据稀缺的 domain 对齐。目前两个数据最富足的空间是语言和视频。机器人数据有 action data,但相对视频来说还是稀缺。所以从视频开始接入 action,再做机器人世界模型,是比较合理的。
如果重新构造一个新的表征空间,可能会有效率优势,但很难直接利用现有语言和视频模型的泛化能力。
晚点:你前面说 3D 表征的劣势,在于它不是端到端。那 LeCun 的 JEPA 选择的隐空间路线是端到端的吗?构建隐空间可以端到端训练吗?
高深远:从他们之前的研究脉络看,可能是端到端的,具体技术细节大家也不完全知道。问题在于它切换到了一个新的隐空间,不是现在 GPT、Gemini 或者 Sora 这些模型能直接读懂的。
如果想利用其他基模能力,就需要把这些模型往新的隐空间上对齐。但我觉得,目前语言和视频这两个表征,对通往 AGI 来说已经比较足够。
晚点:你觉得那条路线至少有一个明显限制:不能受益于现在整个行业的技术进展和红利。
高深远:对。它可能更高效、更适合决策,但这个空间构造出来以后,预测出的隐空间不能直接给语言或者视频模型看。
晚点:在英伟达 GEAR(Generalist Embodied Agent Research,NVIDIA 的具身智能研究团队),你们是都比较看好视频生成路线,还是也有很多不同方向,取决于研究员兴趣?
高深远:首先是看大家兴趣,各种有希望的路线都会尝试。我觉得视频首先是数据非常富足的模态,有很强的可扩展性。另外随着技术和芯片的优化,视觉预测的效率问题也会被逐步解决。
但隐空间可能有更高效的优势。对机器人来说,尤其要部署在真机上,效率是关键。但不管怎样,数据来源肯定还是视频。隐空间也是从视频数据中学出来的。
世界模型为何热起来?数据增多 + 策略变强了
晚点:你两三年前开始研究世界模型,明显感觉今年更火了。你觉得为什么?大家看到了它的什么价值?
高深远:最大因素是视频生成模型的发展:从一开始什么都模拟不了,到现在可以模拟非常逼真、符合物理规律的场景。
第二是数据。具身智能这几年变热后,数据供应商和开源数据集越来越多。过去大家更关注训练 policy(策略模型,根据观测选择动作的决策模型),通过模仿专家轨迹做决策;但世界模型做的是模拟器,不仅要模拟好轨迹,也要模拟差轨迹,才能得到更无偏的 action 反馈。
第三是 policy 本身发展到了一定水平。以前 policy 只能在实验室里做简单任务,这时候用不着世界模型。它的价值是帮助 policy 泛化,包括场景、task 和 action 泛化。当 policy 输出的 action 不那么乱之后,世界模型要模拟的 action 分布会变窄,更容易提供可靠反馈,进一步优化 policy。
这两者关系可以理解为:世界模型根据过去状态和 action 预测未来世界状态,policy 根据当前观测输出 action,两者可以形成循环交互。
晚点:policy 也是一个模型吗?
高深远:对,policy 可以是各种各样的模型,比如之前很主流的 policy 就是 VLA(Vision-Language-Action,视觉-语言-动作模型)。
晚点:那世界模型要部署到具身机器人上吗?
高深远:可以部署到机器人上,也可以部署在云端。
晚点:所以世界模型其实在大小上的限制比 policy 要更宽泛?比如 VLA 就要尽量做的小一点,因为要跑在端侧,而世界模型可以在端侧,也可以在云端。
高深远:VLA 也可以部署在云端,主要看部署环境。如果网络很好,policy 和世界模型都可以在云端。
晚点:GEAR 发布了 DreamDojo、DreamZero 之后,国内很多文章说你们提出了新的范式,叫 WAM(World Action Model,世界动作模型)。WAM 和 VLA 是对等的吗?WAM 是策略还是世界模型?
高深远:DreamDojo 和 DreamZero 都可以称为世界模型,但功能不一样。
WAM 输入是 text,也就是任务指令,输出未来视频和 action。严格说,WAM 不是纯粹的世界模拟器,它其实也是一个 policy,和 VLA 在功能定位上接近。不同的是,VLA 只输出 action,而 WAM 还输出未来 world state。
就像人做决策时有很多层次的 action space(动作空间),可以在文本空间完成。如果把文本也看作一种 action,WAM 接收文本,并模拟它对应的未来世界状态,从这个意义上说,它也是世界模型。
晚点:所以它是同时输出机器人的轨迹和动作,也用文本方式输出世界状态?
高深远:对。WAM 相比世界模型,多了 action 预测功能;相比 VLA,多了视频预测功能。它既具备 high level action planning 下的世界模型功能,也具备 VLA 的功能。但平时我们会把它当作 policy 来用。
晚点:如果把它作为 policy 放到机器人上用,还需要另一个世界模型给它状态吗?
高深远:对,你可以把 WAM 当作 policy,用它输出 action,再接给 DreamDojo 或其他更常见意义上的世界模型。
世界模型的作用,是你给它 action,它预测未来状态。这样在执行 action 之前,不需要真的和现实世界交互,就能看到不同 action 的后果,就可以先搜索再决策。人脑里也在做这件事,只是很快。
实际应用里,可以用 DreamZero、WAM 对不同文本步骤做预测,选出最佳方案。确定子任务后,把更 low level 的动作轨迹交给 DreamDojo,继续优化接近速度、抓取角度、力度等细节,最终做出更好的决策。
晚点:你刚才讲了世界模型最近进展快的原因,包括视频生成、数据、策略变复杂。长期来看,它的价值是不是也来自一种仿生思路:提前预测后果,让智能体更高效、更能自主泛化?
高深远:对,更泛化,也更安全。人做决策时,本来就会先在脑子里想象后果。没有世界模型,决策就像不管后果,先做了再说;有了世界模型,就可以在做之前知道后果,决策更安全。
它还可以用于评测。具身智能现在评测很难,也不够公平。每次都要真机部署,还要有人看着;如果模型很烂,可能会损坏设备。不公平在于现实环境很难每次完全一致,光照、物体位置、传感器状态都会变化。
但如果在世界模型里评测 policy,就能反复把场景重置到同一状态,更高效也更公平,本质上是用算力替代真实实验成本。
另外,世界模型还能生成数据。过去要遥控真实机器人采集 action 数据,再训练 policy;DreamDojo 有一个例子,是把世界模型做到实时,就可以直接遥操虚拟机器人,生成训练数据。
晚点:遥操过程中还是要带传感器或设备吧?
高深远:设备可能还是需要的。不过随着硬件发展,遥操设备也会越来越简单。然后可以让 policy 跑在世界模型里,人用遥操设备对它做干预,得到纠正后的轨迹,再提升 policy。
除了这些,世界模型还能做强化学习,在里面试错非常安全。现在机器人没有办法像阿尔法狗那样进步的最大限制是物理时间:一天只有 24 小时,人也要上下班。但在世界模型里能并行开很多环境、快速迭代。而且如果和现实世界之间没有 gap,跑一段时间后可能涌现出新能力。当然现在还远没到这个阶段,但这是很有前景的方向。
世界模型、Policy 和 Agent 的自进化循环
晚点:哈萨比斯(Demis Hassabis,Google DeepMind 联合创始人兼 CEO)之前也讲过,DeepMind 的 Genie 和 SIMA(Scalable Instructable Multiworld Agent,可按自然语言指令在多种 3D 虚拟环境中行动的智能体)有一个很有前景的应用,就是在模拟世界里做实验、搞科学,甚至加速可控核聚变这类科研。但有个问题:如果世界模型真能模拟到那个程度,AGI 可能已经实现了,那具身智能是不是也该在那之前就实现了?
高深远:我比较认同哈萨比斯的思路:一个 video space 里的世界模型,加一个通用智能体,比如 SIMA,也是类似于 VLM(Vision-Language Model,视觉语言模型)的架构,两者组成自我进化的循环。
现在确实离那个阶段还很远,但不代表必须完全成熟后才能开始做循环。它是循环上升的过程。现在主要有三个部分:一个强的 VLM 链接循环,定义 agent 做什么任务,并评判世界模型预测出的 world state 质量;agent 根据任务提出 action;世界模型根据 action 想象未来,再交给 agent 做评测。这个循环转起来后,就可以实现自进化。
当前各个组件的泛化能力还不够,所以容易出现级联误差:agent 不能稳定给出高质量反馈,policy 不能在各种场景下可靠输出 action,世界模型也不能稳定预测真实未来。但现在大家都在往泛化性推进,到未来某个点,我觉得可能就发生在今年,比如一旦误差累计到可接受程度,policy 就会开始提升,整个循环反而会越来越简单。
过去 policy 太差,机器人可能打坏东西,甚至损坏机械臂。但如果它达到一定水平,就能在新环境里采集数据,即使数据质量不高,但因为是 policy 自己产生的,所以这是个自动化过程。
这些 data 又能训练世界模型,提升它的物理理解和 action 控制能力,这两点决定了世界模型的世界预测能力,然后再反过来优化 policy。这样循环下去,policy 输出的动作分布会越来越集中合理,世界模型要模拟的范围更小,反馈也更准确,整个系统就会进入正向迭代。
晚点:你说 policy、世界模型和通用 agent 这三个要素,泛化到一定程度后循环跑通,就会进入更快的自进化过程。你还说可能 2026 年某个时间会发生。现在已经 4 月了,你们是看到什么迹象了吗?
高深远:很多 paper 也在讨论。在一些简单任务上,已经把这个循环连起来了。
这也是我觉得没必要重新构造新表征空间的原因。现在 agent 基于 VLM,世界模型基于 video,policy 比如 DreamZero 也可以基于 video backbone(视频骨干模型),它们都从数据最丰富的模态出发,更容易接起来。agent 和 policy 的交互是语言,policy 和世界模型之间是 action,世界模型和 agent 之间是 video。这几个模态都相对富足,也能利用现有基模能力,所以很有前景。
晚点:Google 那边如果对应这个循环,视觉模型是 Genie,agent 是 SIMA。那英伟达的公开成果里可以怎么对应?
高深远:英伟达这边是 Cosmos(NVIDIA 面向物理 AI 的世界基础模型平台)在做基模,它偏向 VLM 和 video foundation model(视频基础模型)。它本身不一定直接负责决策,也不一定天然带 action 控制,更多是通过后训练再获得 action 的输入输出。
Google DeepMind 的 Genie 3(实时交互式世界模型)是键盘控制,理论上这套流程也能用到机器人上。但他们很喜欢从游戏出发,好处是数据可以无限造,验证也更方便;机器人数据从产生阶段就受物理时间限制。
晚点:那 DreamDojo 相当于 SIMA,还是 Genie 3?
高深远:DreamDojo 更像 Genie 3。SIMA 相当于一个 policy,控制游戏里的 agent。我们的是物理世界的 policy,比如 VLA 或 DreamZero,控制的是机器人。
晚点:在具身智能的语境里,世界模型就是 DreamDojo,策略是 DreamZero,机器人就相当于是 agent。
高深远:对,在这个循环里,agent 起到连接循环的作用,可以是 Gemini 这类 VLM。它输出文本,也给 world state 打分。如果 world state 是 video,就能直接用现有基模来处理。
泛化瓶颈、测评痛点、Google、NV、OpenAI 等团队进展
晚点:你觉得现在世界模型探索里比较大的瓶颈是什么?
高深远:现在还是早期,有三个方向值得做:泛化能力、长程稳定性和效率。后两点也重要,但我觉得泛化最关键,它决定世界模型应用的上限。
泛化首先是物理理解的泛化,就是希望世界模型即使在机器人数据没覆盖到的场景和物体上,也能模拟得很好,帮助 policy 提升泛化能力。否则 policy 还是只能在见过的物体和场景里进步。
另一个是 action 泛化。世界模型应该尽可能公平地模拟所有 action,而不只是专家动作。过去几年 policy 积累的数据多是专家数据:抓东西就是抓成功。这对 policy 合理,但对世界模型不应该对动作有偏好。你给它一个抖的动作,它就应该模拟抖;给它一个抓偏的动作,它就应该模拟抓偏。否则给它一个差 action,它可能仍然抓成功。这就没反馈区分度。
这不是最终瓶颈,因为 policy 达到一定水平后,可以自动采集一部分自己可能输出的动作数据。世界模型只需要模拟 policy 可能输出的动作空间。但现阶段 policy 还不够强,所以世界模型仍然需要无偏地模拟不同 action。
晚点:你提到三个方向:泛化、长程稳定性和效率。后两个是在泛化之后自然解决,还是业界也在努力?
高深远:长程稳定性与效率和视频生成的需求是对齐的。现在视频生成要生成电影了,行业自然会解决误差累积和效率问题。它们不是限制 policy 的主要瓶颈,但长程仍然很重要。
现在的短程任务,比如 1.5 秒左右的瞬时决策,世界模型模拟一下就能给反馈。但未来通用机器人要做长程任务,需要世界模型有长程模拟和记忆能力,有助于长程 policy 训练。不过现在还没到那个阶段。
晚点:可以举一个长程任务的例子吗?
高深远:比如你把一个东西放到柜子里,关上门。如果模型没有长程记忆,关上之后可能就忘了东西在哪里,再打开时,东西在不在就变成随机猜。
现在的视觉模型,包括 DreamDojo,都还没有这种长程记忆。这对决策很灾难,因为 policy 得不到可靠的世界预测,收到的都是随机信号。
晚点:如果未来家庭服务是具身智能最大的场景,机器人要像管家一样知道家里的东西放在哪里。这种长时记忆是靠机器人自己记,还是把家里的信息直接告诉它?
高深远:这方面具身智能的 research 没那么关注。首先这种场景更适合在文本空间做,用视频记冗余度太高;它更多是大模型在解决的问题,技术上也共通。
具身领域更关注任务确定后,怎么把它变成成功率很高的 action。
晚点:那在这三个方向之外,世界模型怎么测评?有比较公认的 Benchmark 吗?前面说世界模型可以测评具身智能模型,但反过来,怎么测世界模型?
高深远:这是世界模型最大的痛点。你读论文会发现,几乎每篇都自己搞一个 Benchmark,而且通常只比少数几个模型。主要是机器人决策世界模型很难 zero-shot(零样本,指未经特定训练直接适配新任务或新对象)到不同机器人上。
世界模型输入 action,预测未来 state。但不同机器人自由度不同,action space 也不一样。所以世界模型往往一一对应机器人本体。语言模型和视频生成模型输入输出空间天然统一,容易有公开 Benchmark。但机器人领域很难把模型放在一起公平评测。
所以要么有一个很强的世界模型,掌握所有的 action space,要么所有团队收敛到同一种机器人。否则大家只能把别人的世界模型拿过来,在自己的机器人本体和 action space 上重新训一遍,成本很高。
晚点:那业界怎么判断谁做得好?
高深远:没有直接指标。只能拿过来试。即使大家用同一种机器人,action space 一样,但相机装不同位置,训出来的世界模型也会不同。
晚点:这对投资人来说就更难判断了。
高深远:对。现在就是比较早期。
题图来源:《盗梦空间》
精彩评论