$英伟达(NVDA)$ $Cerebras Systems(CBRS)$
AI 算力芯片正在遇到一个共同问题:单颗芯片已经越来越难继续做大。
一方面,先进制程越来越贵,摩尔定律放缓;另一方面,传统芯片还受到光罩尺寸、良率、功耗和散热的限制。于是行业出现了两条不同路线:
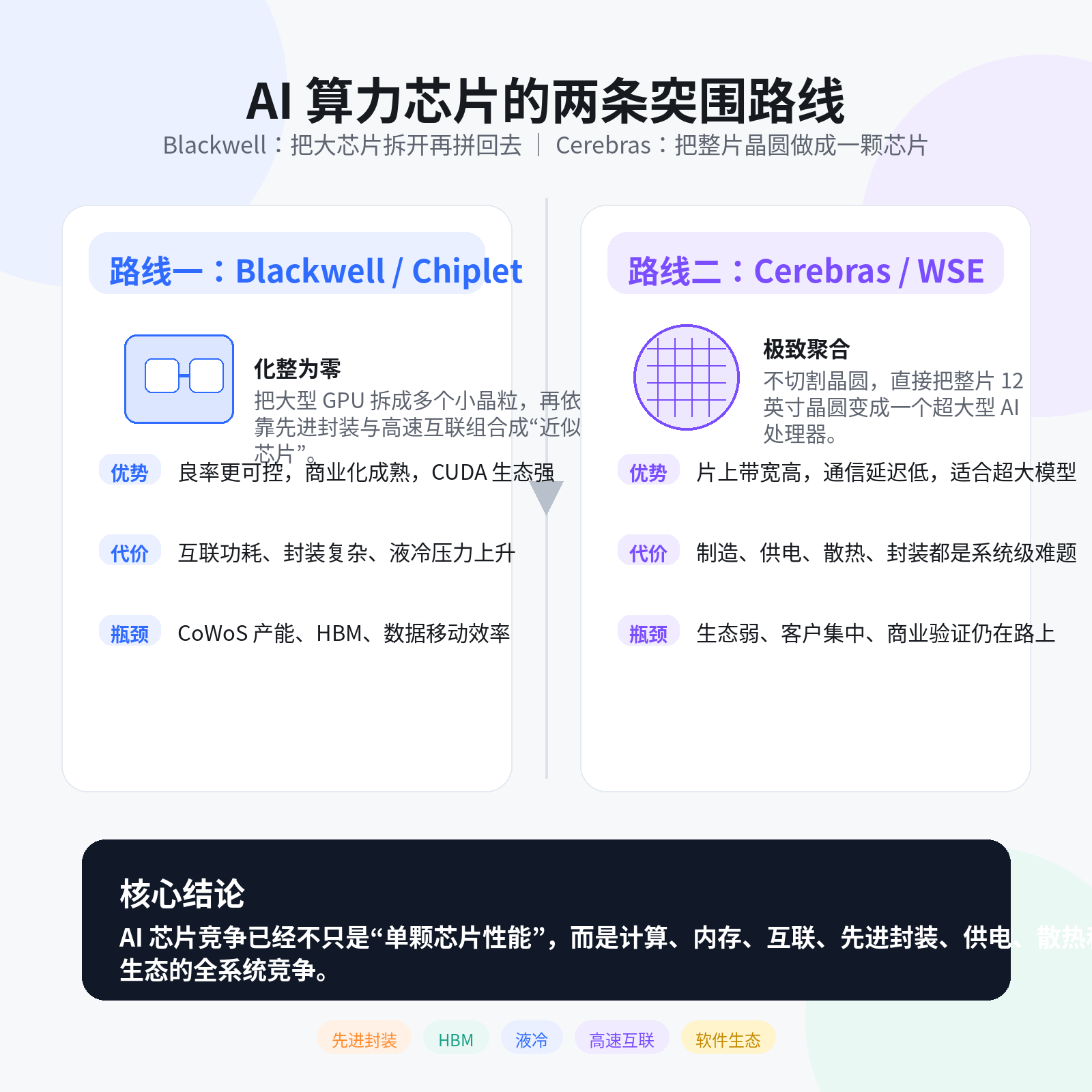
一条是英伟达 Blackwell 代表的 Chiplet 路线:把大芯片拆成多个小晶粒,再通过先进封装重新拼起来。
另一条是 Cerebras 代表的 晶圆级计算路线:不把晶圆切成小芯片,而是直接把整片 12 英寸晶圆做成一个超大型 AI 处理器。
一、Blackwell:用 Chiplet 突破单芯片极限
Chiplet 的核心逻辑是“化整为零”。
传统单片大芯片一旦出现缺陷,整颗芯片都可能报废;但 Chiplet 可以把一个大型系统拆成多个小晶粒,只挑选良品晶粒进行组合,从而提升制造良率。同时,不同功能模块还可以采用不同制程,实现更灵活的异构集成。
Blackwell 就是这一思路的典型代表。它通过两颗 GPU 晶粒配合 NVLink-C2C 互联,在逻辑上让系统看起来像“一颗超级芯片”。
但这种模式并不是没有代价。它本质上是用封装复杂度、功耗、散热和系统成本,去换取更大的算力规模。
Blackwell Chiplet 路线的主要代价
第一,是功耗上的“传输税”。
在单片芯片内部,数据传输距离短、功耗低;但 Chiplet 之间即使有高速互联,数据跨晶粒移动依然需要额外能耗。对于 Blackwell 这种功耗动辄数百瓦甚至上千瓦的芯片来说,部分电力并不是直接用于计算,而是用于维持多颗晶粒之间的高速通信。
第二,是先进封装的成本与产能瓶颈。
Blackwell 依赖台积电 CoWoS-L 等先进封装技术。即使单颗 GPU 晶粒本身良率较高,只要最后封装阶段出现问题,整组昂贵芯片仍可能报废。因此,AI 芯片的瓶颈不只在晶圆代工,也越来越集中在 CoWoS 这类先进封装产能上。
第三,是散热难度大幅上升。
两颗高性能晶粒被紧密放在同一基板上,会形成极高热密度。为了避免芯片过热降频,数据中心不得不从传统风冷转向更昂贵、更复杂的液冷系统。
第四,是软件透明度并不完美。
虽然英伟达希望让开发者感觉“两颗芯片像一颗芯片”,但在极限性能场景下,访问另一颗晶粒上的 HBM 仍然会有更高延迟。因此,在大模型训练和推理中,数据布局依然会影响最终性能。
第五,是扩展存在边际限制。
Chiplet 不是无限堆晶粒就能无限扩展。晶粒越多,互联占用的面积、功耗和复杂度越高,最终会挤压真正用于计算的空间。
所以,Blackwell 的本质是:通过 Chiplet 和先进封装,在物理极限附近继续榨出更高算力。
它是当前 AI 军备竞赛下非常现实的最优解,但代价是系统越来越重、越来越贵、越来越依赖先进封装和液冷基础设施。
二、Cerebras:直接把整片晶圆变成一颗芯片
Cerebras 走的是另一条更激进的路线。
传统半导体制造会把一整片 300mm 晶圆切割成数百颗芯片,而 Cerebras 反其道而行之:不切割晶圆,而是把整片晶圆直接做成一个超大型处理器。
它的 Wafer Scale Engine,也就是 WSE,本质上是一个晶圆级 AI 引擎。WSE-3 面积高达 46,225 平方毫米,远远超过传统芯片的光罩极限。
这条路线最大的好处是:
它几乎消除了传统多芯片集群之间的通信瓶颈,让计算单元和片上存储高度靠近,从而获得极高的片上带宽和极低的通信延迟。
但问题也很明显:晶圆越大,理论良率越低。
传统良率理论认为,芯片面积越大,遇到缺陷的概率越高。如果按照普通芯片设计思路,一片这么大的晶圆级芯片几乎必然报废。
Cerebras 的关键突破,就是它重新定义了“缺陷”。
三、Cerebras 如何解决良率问题?
Cerebras 的核心思路不是避免缺陷,而是接受缺陷,并让系统绕过缺陷继续运行。
1. 把核心做得极小
WSE-3 的每个处理单元面积只有约 0.05 平方毫米,远小于传统 GPU 的核心单元。
这意味着即使晶圆上出现一个缺陷,也只会影响一个极小区域,而不是毁掉一大块计算资源。缺陷从“整颗芯片报废”,变成了“屏蔽一个小单元”。
2. 预留大量备用核心
WSE-3 上有约 97 万个物理核心,但对外宣称可用核心数为 90 万个。也就是说,它预留了大量冗余核心,用来替代制造过程中可能损坏的区域。
这让 Cerebras 可以在存在缺陷的情况下,依然交付规格一致的产品。
3. 动态绕线与容错网络
当某个核心或通信路径失效时,系统可以通过动态路由绕过故障区域。整片晶圆不是一个脆弱的整体,而是一个具备自我修复能力的分布式网络。
4. 跨光罩互连
传统光刻设备单次曝光面积有限,因此晶圆级芯片必须解决不同曝光区域之间如何连接的问题。Cerebras 与台积电合作,在切割道区域布置高密度金属连线,实现跨区域高速互联。
这使得整片晶圆可以像一个统一处理器一样工作,而不是许多小芯片的简单拼接。
四、晶圆级计算的系统级挑战
Cerebras 解决的不只是芯片设计问题,还包括供电、散热、封装和材料物理问题。
供电方面,WSE 功耗高达 15kW,如果从晶圆边缘供电,会出现严重电压下降。因此 Cerebras 采用垂直供电,让电流从晶圆上方直接注入。
散热方面,15kW 的热量已经远超传统风冷能力,因此必须采用定制水冷系统。
材料方面,硅晶圆和主板材料的热膨胀系数不同,升温后会产生应力和形变。Cerebras 需要设计特殊连接器,在保持高电流和高速数据传输的同时,吸收热膨胀带来的位移。
也就是说,Cerebras 做的不是单纯一颗芯片,而是一整套从芯片、封装、供电到散热的系统工程。
五、两条路线的本质区别
|
对比维度 |
Blackwell / Chiplet 路线 |
Cerebras / 晶圆级路线 |
|
核心思路 |
把大芯片拆小,再重新封装 |
不切割晶圆,整片晶圆作为处理器 |
|
主要优势 |
良率更可控,生态成熟,商业化能力强 |
片上带宽高,通信延迟低,适合超大规模 AI |
|
主要代价 |
封装复杂、功耗高、散热难、互联有损耗 |
制造难度极高,系统工程复杂,生态弱 |
|
关键瓶颈 |
CoWoS 先进封装、HBM、液冷 |
良率容错、垂直供电、晶圆级散热 |
|
商业护城河 |
CUDA 生态、客户基础、供应链掌控 |
架构创新、极致推理/训练效率 |
|
适用场景 |
大规模通用 AI 训练和推理 |
超高带宽、低延迟、特定大模型推理/超算场景 |
六、投资视角:真正受益的不只是芯片公司
这两条路线虽然技术路径不同,但共同指向几个确定性趋势:
第一,先进封装的重要性会继续上升。
无论是 Blackwell 的 Chiplet,还是 Cerebras 的晶圆级系统,都离不开台积电、CoWoS、SoW、SoIC 等先进封装能力。未来 AI 算力竞争,已经不只是“谁设计芯片强”,而是“谁能拿到先进封装产能”。
第二,液冷会从可选项变成刚需。
AI 芯片功耗越来越高,Blackwell 需要液冷,Cerebras 更需要液冷。数据中心基础设施会成为 AI 算力扩张中的重要投资主线。
第三,互联效率会成为下一阶段核心竞争点。
AI 模型越来越大,真正限制性能的往往不是单颗芯片算力,而是芯片之间、内存之间、节点之间的数据移动效率。因此,NVLink、硅光、CPO、先进封装互联都会变得更加重要。
第四,英伟达的优势仍然不只是硬件。
Cerebras 的架构很激进,但英伟达最大的壁垒在 CUDA 生态、开发者习惯、软件库和客户部署经验。这也是新架构想要挑战英伟达时,最难跨越的一道门槛。
结论
Blackwell 和 Cerebras 代表了 AI 芯片突破物理极限的两种方向。
Blackwell 是现实主义路线:
用 Chiplet、先进封装和高速互联,把多颗芯片尽量做成一颗芯片。
Cerebras 是激进主义路线:
直接把整片晶圆变成一颗芯片,用容错设计对抗传统良率定律。
前者更成熟、更商业化,也更依赖现有生态;后者更极致、更具想象空间,但工程和商业风险也更高。
从产业趋势看,AI 算力竞争已经从单纯的芯片设计,扩展到先进封装、HBM、供电、散热、互联和软件生态的全系统竞争。
真正的核心变化是:
未来 AI 芯片拼的不是单点性能,而是谁能把“计算、内存、互联、封装、散热、软件生态”整合成一个更高效的系统。
精彩评论