科技发展,日新月异,后浪一重重。看到 $谷歌(GOOG)$ 表示,他们新推出的TurboQuant方法能够通过压缩大语言模型推理过程中使用的键值缓存,并支持更高效的向量搜索,从而改善AI模型的运行效率,医药行业也特别的捧场,多篇新闻看到他们利用TurboQuant提高了多少效率。
Google正在解决当今AI系统中最令人头疼、讨论最少的问题之一:推理过程中的内存爆炸!他们通过在不影响输出质量的前提下更积极地压缩这些工作负载,TurboQuant可以让开发人员在现有硬件上运行更多推理任务,并减轻部署大型模型时的成本压力。
要理解Google的 TurboQuant,我们得先把 AI大脑的工作流程拆解开。市场之所以恐慌,是因为它触碰了AI硬件最昂贵的两个字:内存。咱们一层层剥开看:
1.什么是量化Quantization
简单说就是“降精度,省空间”,AI 模型原本用高清格式(如 FP16,每个数字占 16 位)存储。量化就像把 4K 电影压缩成 720P。虽然损失了一点细节,但体积小了数倍,运算速度也快了。
2。什么是 KV Cache?为什么它费内存。
这是理解 TurboQuant 的核心。模型权重(Weights): 相当于大模型的“知识库”,是静态的。KV Cache相当于大模型的“草稿纸”。你在对话时,模型每吐出一个字,都要回看之前的对话。为了不重复计算,它把之前的中间结果存起来,这就是 KV Cache。
区别就在于,权重大小是固定的(比如 Llama-3-70B 就是 700 亿个参数);但 KV Cache 会随着对话长度(上下文)的增加而无限膨胀。当你要处理超长文本(比如读一整本书)时,KV Cache 消耗的内存远超模型权重。
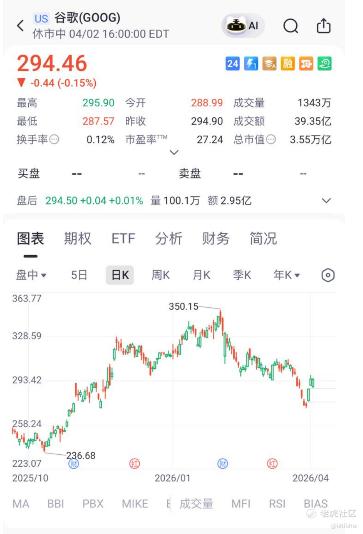
3.Google TurboQuant 到底干了什么,一个这么牛的进步,他们Google的股票,居然也没有大涨。
以往,KV Cache 很难在不严重损伤模型智商的情况下大幅压缩。TurboQuant 的突破在于它实现了一套极高效的算法,能把这张“草稿纸”压缩 6 倍,且推理速度提升8倍。这意味着,原本需要 8 张显卡才能跑的长文本,现在可能1-2张就够了。
4.存储的层级:HBM、DRAM 与 SSD
HBM(高带宽内存)是插在GPU旁边的“超高速缓存”,最贵最快,是AI算力的命门。 $美光科技(MU)$ Micron赚的就是这个钱。DRAM(普通内存)是插在主板上的内存条,速度比HBM慢很多。SSD(硬盘)最慢,用来存数据,不直接参与高速运算。
TurboQuant优化的局部性在于,它主要优化的是推理(Inference)阶段的 KV Cache 效率,而不是训练(Training)阶段,也不是模型权重本身。
5.为什么市场会恐慌
有很多人分析,市场可能是还没从 DeepSeek 的冲击中缓过来。DeepSeek 证明了“通过算法优化可以大幅降低对顶级算力的依赖”。现在 Google 又抛出一个 TurboQuant,散户和算法交易员的第一反应是“完了,AI 硬件的需求逻辑塌了。这真的是“整个产业链崩塌”吗,我不这么认为。
我觉得,这是典型的“局部技术进步”被误读为“需求总量萎缩”。需求创造供给,历史上,存储效率每提升一次,人类就会塞入更多的数据。KV Cache 压缩 6 倍,开发者不会选择少买显卡,而是会去挑战 6 倍长度的上下文(打个比如,从读一篇文章变成读一个图书馆)。
而且,HBM 依然是刚需,无论怎么压缩,推理依然需要极高的带宽来吞吐数据。而且,AI 的训练端(Training)对 HBM 的渴望几乎是无底洞,TurboQuant 这种推理端技术无法替代训练时的物理需求。美光MU的护城河还是非常深的,因为他们不仅卖 HBM,还卖高容量 DRAM。即使 KV Cache 优化了,AI 服务器为了应对多模态、大规模并发,总内存容量的需求依然在指数级上升。
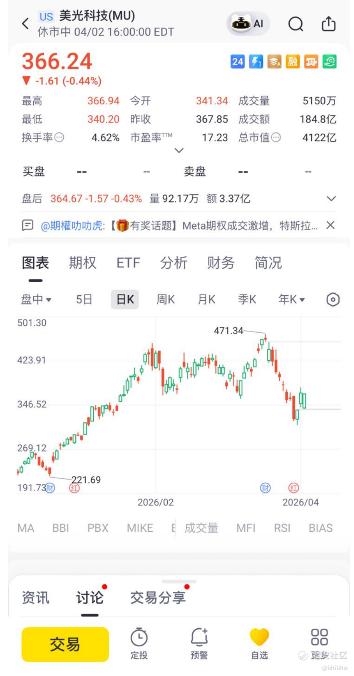
所以,我们可以这么看,TurboQuant 是一个伟大的补丁,它让长文本 AI 变得更便宜、更好用。但它并没有改变“AI 性能上限受限于物理内存带宽”的底层事实。市场恐慌是因为它把“单位成本下降”等同于“总收入下降”。但实际上,AI 领域一直遵循技术进步越快, 门槛越低,用户越多,对硬件的总需求反而越高。现在的美光,应该可以算是一个抄底的机会。[鬼脸]
朋友们觉得呢?[鬼脸]
[财迷]$老虎证券(TIGR)$ [财迷]
精彩评论