近日,有关谷歌TPU和英伟达GPU的讨论争议非常多,著名的半导体分析发文解读了有关谷歌TPU和V7的面貌并且做了对比,笔者这里概况摘录一部分:
谷歌的TPU研发历史可追溯至2013年,当时他们意识到,若想大规模部署AI,就需要将数据中心数量翻倍。于是,TPU项目应运而生,2016年投入生产。
过去九年,TPU主要服务于谷歌内部工作负载。即使在2018年向GCP客户开放后,也从未完全商业化。如今,这一策略正在发生根本性转变。
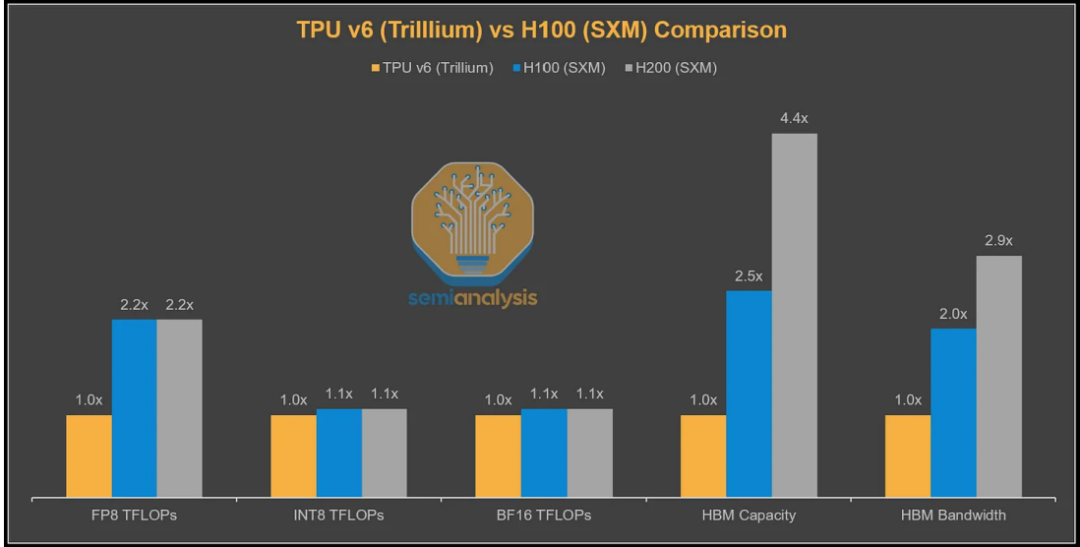
优势何在?TCO低30%以上的秘密:
AI实验室为何选择TPU?答案很简单:更好的性价比和更好的适配性。
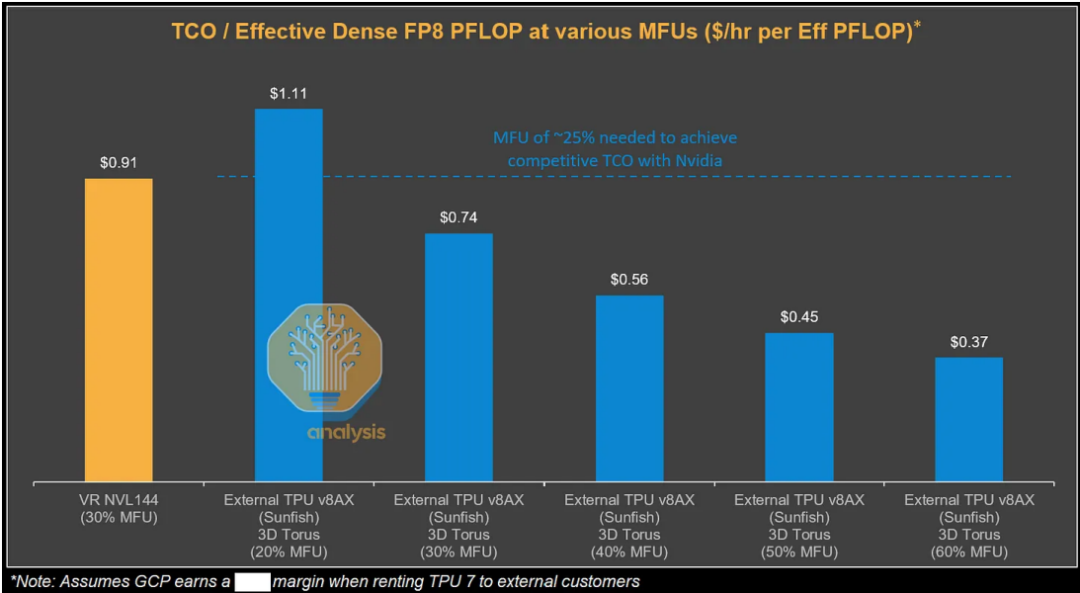
从理论指标看,TPUv7的峰值算力略低于英伟达Blackwell,但其实际性能却往往更优。原因在于芯片厂商通常宣传无法持续维持的峰值算力,而TPU的标称值更为务实。
根据测算,从谷歌视角看,TPUv7服务器的总拥有成本比GB200服务器低44%。即便计入谷歌和博通的利润空间,外部客户通过GCP使用TPU的TCO仍比GB300低30%。
这种成本优势来自多方面因素。TPUv7采用更保守的功耗设计,确保硬件高可用性;谷歌自研的光互连技术大幅降低了通信开销;系统级优化带来了更高的实际利用率。
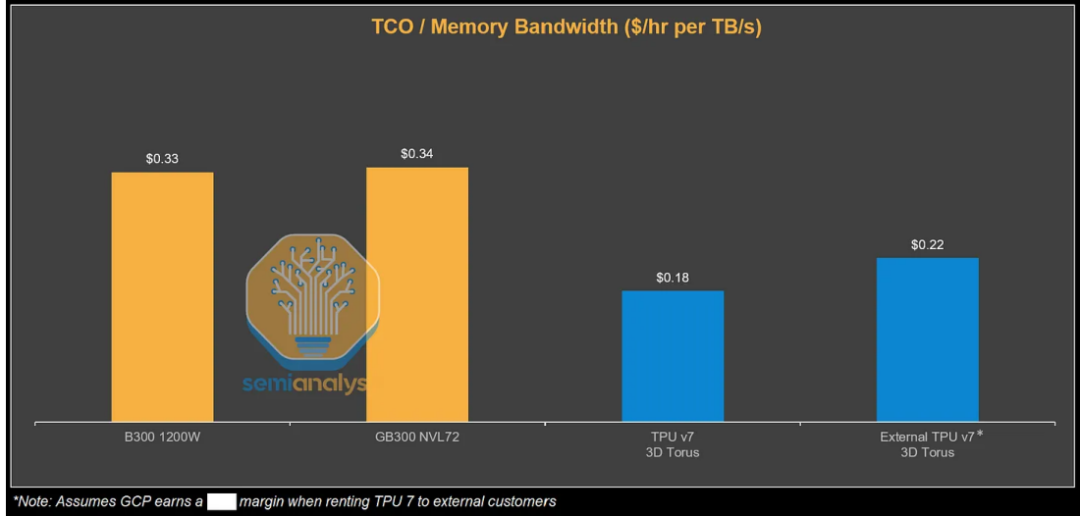
特别值得一提的是,TPU在内存带宽利用率方面表现优异。在小消息大小(如16MB到64MB)场景下,TPU甚至实现了比GPU更高的内存带宽利用率,这对推理性能至关重要。
光互连技术:谷歌的独门绝技。
谷歌TPU最引以为傲的是其Inter-Chip Interconnect(ICI)光互连技术,这是其系统架构的核心创新。
传统GPU集群通常局限于64或72卡规模,而TPUv7集群可扩展至9216颗芯片。这种规模优势来自独特的3D Torus拓扑结构和光路交换机(OCS)设计。
每个TPUv7基础单元是64颗TPU组成的4x4x4立方体,通过铜缆和光收发器混合连接。OCS允许软件动态重构网络拓扑,实现“网络切片”功能。
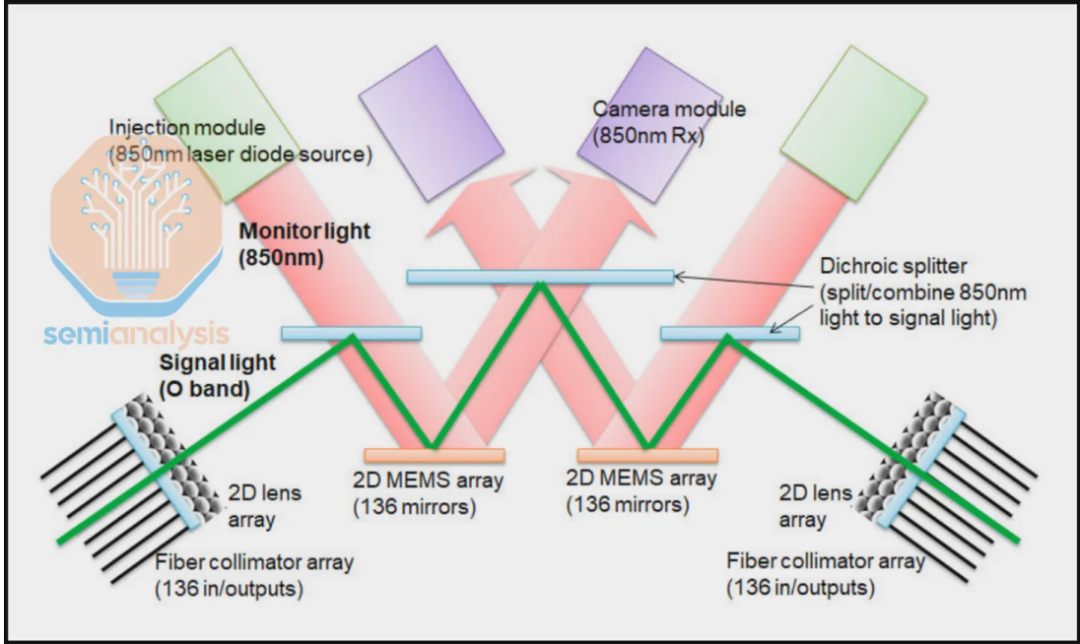
当某部分芯片故障时,系统可在毫秒级内绕过故障点,重新构建完整的3D环面。这种自愈能力大幅提升了集群的可用性,降低了运维成本。
光互连的另一优势是能耗效率。光信号在OCS中无需进行光电转换,直接通过物理反射完成路由,比传统的电子数据包交换节能显著。
软件突围:从JAX到PyTorch的兼容之路。
软件生态曾是TPU的最大短板。全球AI开发者习惯使用PyTorch和CUDA,而谷歌长期主推JAX。这种生态割裂限制了TPU的普及。
现在,谷歌正在积极改变这一局面。TPU团队的KPI已从“服务内部”转向“拥抱开源”,这是公司层面的战略调整。
去年10月,谷歌工程师Robert Hundt在XLA仓库中宣布,将从非原生的惰性张量后端转向“原生”TPU PyTorch后端,支持默认的急切执行模式。
这一转变主要为了满足Meta等客户的需求——他们希望使用TPU但不打算迁移到JAX。新的PyTorch后端将与torch.compile、DTensor和torch.distributed等API深度集成。
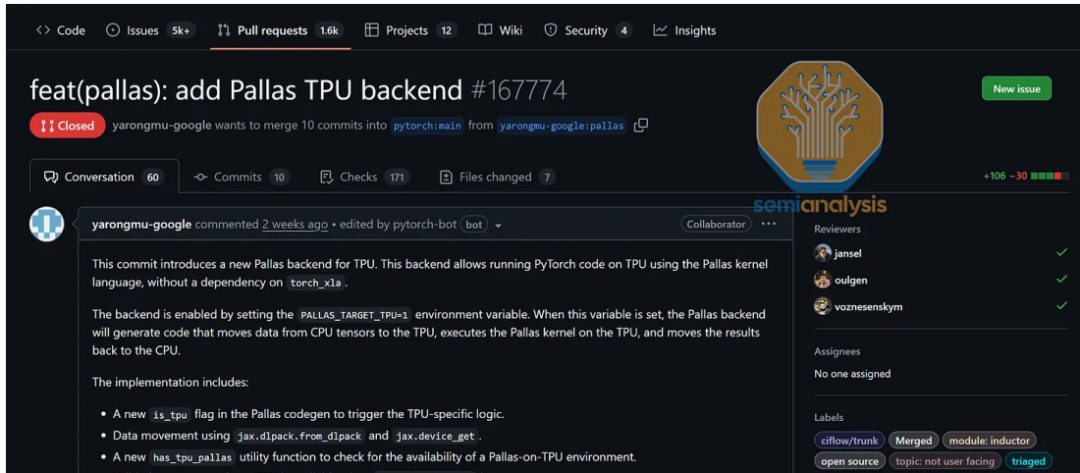
在推理生态方面,谷歌也开始向vLLM和SGLang等开源框架贡献代码。虽然TPU上的vLLM支持仍处于早期阶段,但谷歌已经开源了多个优化内核,包括分页注意力内核和量化矩阵乘法内核。
TPU的性能优势不仅体现在理论指标上,更在实际应用中得到了验证。目前世界上最好的两个大模型——Gemini 3和Claude 4.5 Opus,主要都运行在TPU上。
Gemini 3完全在TPU上完成训练,展示了TPU处理最前沿大模型的能力。相比之下,OpenAI自2024年5月发布GPT-4o后,尚未成功完成新的全规模预训练运行,这从侧面反映了TPU系统的稳定性优势。
在具体能力测试中,Gemini 3在工具调用和智能体能力方面表现突出。特别是在“Vending Bench”测试中——该测试模拟模型长期运营自动售货机业务的能力——Gemini 3大幅领先竞争对手。
Anthropic最近发布的Opus 4.5不仅能力提升,还将API价格降低了约67%。这种降价空间部分来自TPU带来的成本优化,同时也受益于模型更高的token效率。
尽管TPUv7表现出色,但竞争不会停止。英伟达的VeraRubin平台将在2026年上市,而谷歌的TPUv8要等到2027年。
第八代TPU将采用双轨策略:TPU 8AX与博通合作,TPU 8X与联发科共同设计。这种多元化合作反映了谷歌希望降低对单一供应商依赖的战略考量。
TPU 8AX基本延续Ironwood架构,仍采用N3E工艺,但内存升级为12层HBM3E,带宽提升约30%。TPU 8X则更为激进,采用单计算芯片设计,使用N3P工艺。
然而,TPUv8的性能提升相对温和,而英伟达Vera Rubin计划使用HBM4,单芯片带宽将达到20TB/s。如果英伟达按计划实现这一目标,TPU的TCO优势可能会缩小。
谷歌面临的另一个挑战是供应链速度。从芯片制造到机架组装再到数据中心部署,TPU的整个供应链节奏慢于英伟达。在AI算力需求日新月异的背景下,这可能成为竞争劣势。
笔者认为,目前谷歌TPU仍在放量,博通的ASIC也在加快获取先进封装产能和出货。未来,大厂的资源会更多倾向于ASIC,对英伟达的投入增速会放缓。不过,由于GPU和CUDA的通用性,预期未来成立的初创AI企业仍是优先选择英伟达方案(笔者之前已经讨论过),这会给英伟达带来新的增长动力。12月11日盘后,博通会公布25FYQ4财报和未来的指引,让我们来看看这家定制芯片巨头会不会迎来明显的再加速。
精彩评论