写给大众用户的大语言模型通俗指南,避开所有数学公式,直击本质、从基础到实践的清晰指南,你不用懂数学、不用会编程,也不用记复杂的提示词。
你不用搞懂 LLM 的每一个 “零件”,但理解token、嵌入、参数这些核心组件,会让它不再神秘。还能帮你看清模型的优势、短板,以及如何让它给出更好的结果。
1. token
大语言模型本质是个数学系统,有个核心问题:它只懂数字,不懂文字。那它怎么 “读懂” 你问的 “什么是微调?” 呢?
第一步就是把文本转换成模型能处理的形式 —— 先将句子拆成最小有意义单位,也就是token。
这个拆分工作由 “(tokenizer)” 完成:
-
先把句子拆成token列表:[“什么”, “是”, “微”, “调”, “?”](不同token器拆分规则略有差异,比如可能拆成 [“什么”, “是”, “微调”, “?”]);
-
再把每个独特的token换成对应的 ID 数字。
最终,“什么是微调?” 会变成一串模型能理解的数字序列,比如 [1023, 318, 5621, 90177, 30]。
但token本身没有意义,只是一串 ID,要让模型理解,还需要另一层处理。

2. 嵌入(embeddings)
通过token化,我们把问题变成了数字 ID 列表,但这些数字只是随机标签 —— 比如 “猫” 的 ID 和 “小猫” 的 ID 毫无关联,模型根本不知道它们的意思和联系。
这时候 “嵌入” 就派上用场了。嵌入是一串特殊的数字(称为 “向量”),专门用来表示token的含义。它不再是随机 ID,而是给每个token分配一组 “意义坐标”,把它放在一个巨大的 “意义地图” 上。
在这张地图上,意思相近的词(比如 “狗” 和 “小狗”)会靠得很近。模型能通过数字计算关系:比如 “国王” 到 “女王” 的坐标变化,和 “男人” 到 “女人” 的坐标变化是一样的。
这也是聊天机器人和搜索引擎能理解不同表达方式的原因 —— 你搜 “汽车”,嵌入技术会让引擎知道 “轿车”“机动车” 相关的内容也符合需求。
这些嵌入并不是杂乱无章的,它们都存在于一个更大的结构里。
3. 潜空间(Latent Space)
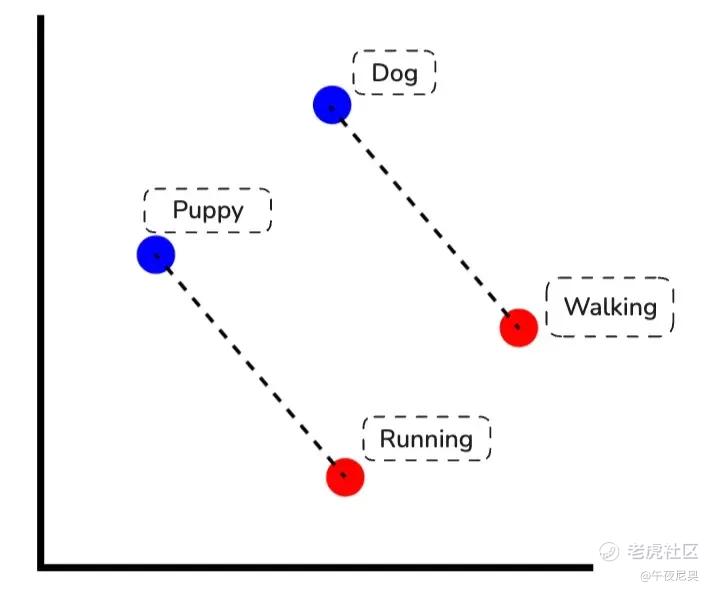
词嵌入通过向量差异体现关系 —— 就像 “狗→小狗” 和 “走→跑” 的向量变化是平行的,这就是意义的几何编码方式。
当模型把问题转换成嵌入后,这个嵌入不会孤立存在,而是进入 “潜在空间”—— 也就是所有嵌入所在的巨大 “意义地图”。
它不是物理空间,而是模型构建的数学空间。训练过程中,模型会在这个空间里整理各个概念的嵌入,让它们的位置和距离能反映真实世界的关系。
比如你问 “什么是微调?”,这个问题的嵌入会和其他关于 “训练方法” 的嵌入靠得很近。模型的任务很简单:在这个 “邻里区域” 里,找到最匹配的内容。
而支撑这种能力的,是模型的内部设置 —— 也就是参数。
4. 参数(Parameters)
ChatGPT 这类系统的基础模型,拥有数十亿个内部变量,这些就是 “参数”。它们不是数据库里的条目,也不是事实列表,而是可调整的 “设置”,让模型能捕捉语法、概念和模式。
你可以把参数想象成一堵巨大的 “旋钮墙”:
-
一开始,所有旋钮都是随机设置的,毫无用处;
-
训练过程中,模型会重复数万亿次 “预测下一个token” 的游戏;
-
每次猜错,就微调一下这些旋钮,让它慢慢接近正确答案;
-
经过无数次微调后,最终的旋钮设置就编码了模型学到的一切 —— 包括语言模式、概念关联和通用知识。
如果不经过训练,数十亿个随机旋钮毫无意义,只有通过漫长的训练,它们才能承载知识。
大语言模型如何学习:“黑科技” 的训练过程
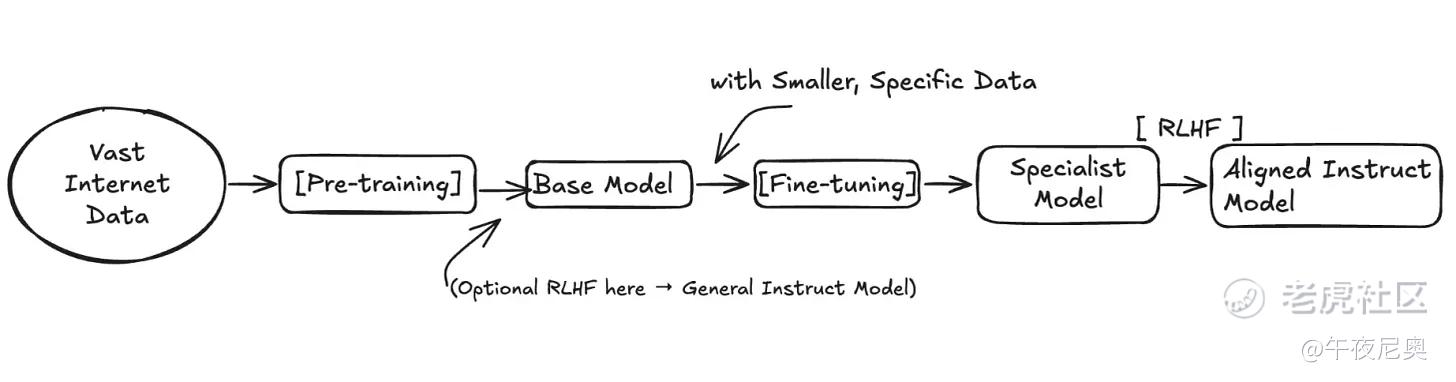
5. 预训练(Pre-training)
把随机参数变成 “知识库” 的过程,就是预训练。
这个基础阶段,模型会接触互联网上的海量文本和代码,核心目标只有一个:预测序列中的下一个token。每次预测后,它会对比真实答案,然后通过训练算法微调数十亿个参数。经过数万亿次重复,这些微小的调整会逐渐编码语言的统计模式 —— 这就是 GPT-5 这类基础模型在适配实际应用前,学习语法、常识和基础推理能力的方式。
这个训练过程可以拆成两步理解:
(1)核心任务:预测下一个token
给模型一段文本片段,比如 “微调是一个____的过程”,它要猜测缺失的部分。一开始猜测是随机的,但每次猜错后,参数会微调,让下一次更可能猜到 “进一步训练” 这类正确答案。
(2)训练结果:一个模式识别引擎
经过数万亿次修正,模型会变得特别擅长识别模式。它见过无数次 “微调是进一步训练的过程” 这类表达,所以能牢牢记住这种关联 —— 但它并不是在 “理解” 或 “思考”,只是在复现学到的模式。
预训练让模型装满了互联网上的模式,但此时它还只是个 “文本预测器”。要明白这为什么是个问题,就得区分基础模型和指令模型。
6. 基础模型(Base Model)vs 指令模型(Instruct Model)
模型完成预训练后,就是 “基础模型”。它虽然知识渊博,但还不是个 “贴心助手”。
比如你用原始基础模型问 “什么是检索增强生成(RAG)?”,它可能只是机械地续写句子,或者给出一个笼统无用的定义。它擅长预测文本,但没被训练过遵循指令或进行对话。
要让它变成聊天机器人、搜索助手这类实用工具,就需要 “指令模型”。
指令模型是基础模型经过额外训练后的产物 —— 这种训练叫 “微调”,用的是专门的 “指令 - 答案” 配对数据集。这个过程不会教模型新事实,而是教它 “怎么做事”:理解用户意图、给出清晰解释、结构化呈现回应。
ChatGPT 和 Claude 都是指令模型,它们从设计之初就是为了提供帮助、响应需求,是任务导向型应用的核心。
而把基础模型变成指令模型的关键一步,就是微调。
7. 微调(Fine-tuning)
微调,就是把完成预训练的模型,用更小、质量更高的数据集再训练一次,让它专门适配某个任务。
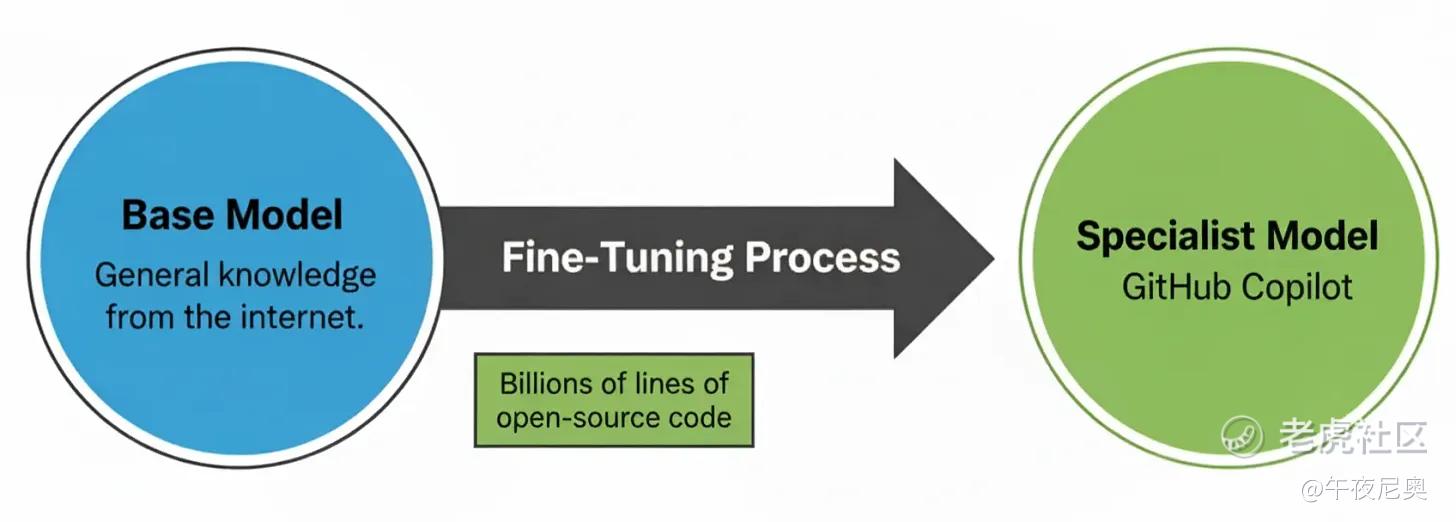
这次的数据集不再是整个互联网,而是几千个和目标场景高度相关的精选案例。
最典型的例子就是 GitHub Copilot:基础模型能生成各种文本,通过在数十亿行开源代码上微调,它学会了写出、补全符合开发者风格的代码。微调后的模型并没有 “懂更多” 编程知识,只是更贴合真实世界的代码模式,实际使用中更可靠。
这种针对性训练会微调模型的参数,让它模仿特定数据集的风格和准确性。
塑造模型行为:从 “知识库” 到 “贴心助手”
8. 对齐(Alignment)
通过微调,模型能遵循指令了,但 “好答案” 的标准是什么?
一个只在互联网上训练的原始模型,可能给出技术上正确但对新手来说晦涩难懂的答案,甚至会重复训练数据里的有害刻板印象。
这就是 “对齐” 要解决的核心问题:让大语言模型的行为符合人类价值观和意图,具体来说就是 “有帮助、诚实、无害”。
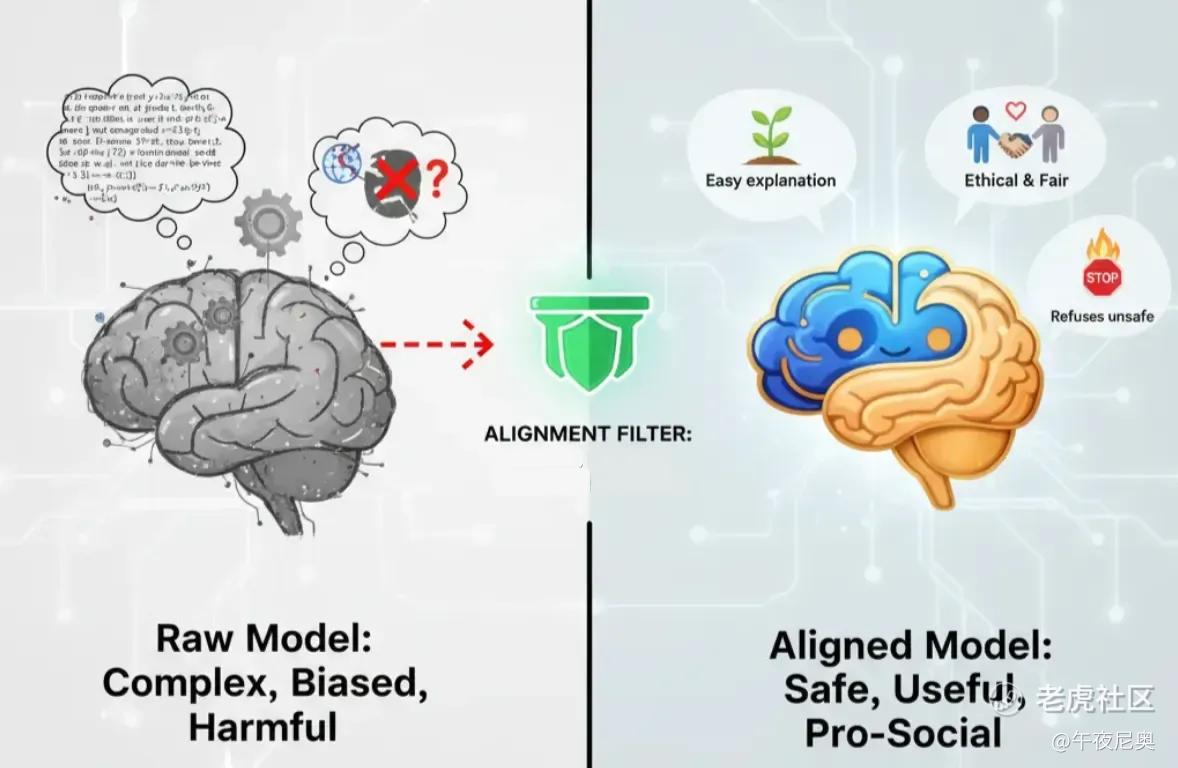
比如 ChatGPT 会拒绝不安全的请求,会应要求简化复杂概念,还会避免偏见或冒犯性语言。对齐的目标不是让模型 “更准确”,而是让它的行为实用、符合社会规范。
9. 基于人类反馈的强化学习(RLHF)
那怎么实现对齐呢?总不能直接告诉模型 “要贴心” 吧?我们需要一种方式,让它明白人类眼中的 “优质” 和 “贴心” 是什么样的 —— 这就是基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)。
它不是只靠文本训练,而是根据人类偏好调整模型,具体步骤如下:
-
人类评分:给模型一个问题(比如 “什么是微调?”),让它生成多个答案,然后由人类评审员给这些答案排序(从好到坏);
-
训练 “裁判模型”:用这些排序数据训练一个单独的 “奖励模型”,它的唯一任务就是预测人类会如何评价某个答案;
-
模型向 “裁判” 学习:让语言模型再次生成答案,由奖励模型打分,然后微调语言模型的参数,让它更倾向于生成高分答案 —— 慢慢学会符合人类偏好的回应方式。
这个过程能让 ChatGPT、Claude 这类模型明白,人类看重的是清晰、贴心、礼貌和安全,而且不用手动编码这些行为。
但模型只有收到输入,才会生成回应 —— 那我们该怎么和它 “对话” 呢?
与模型对话:交互层的秘密
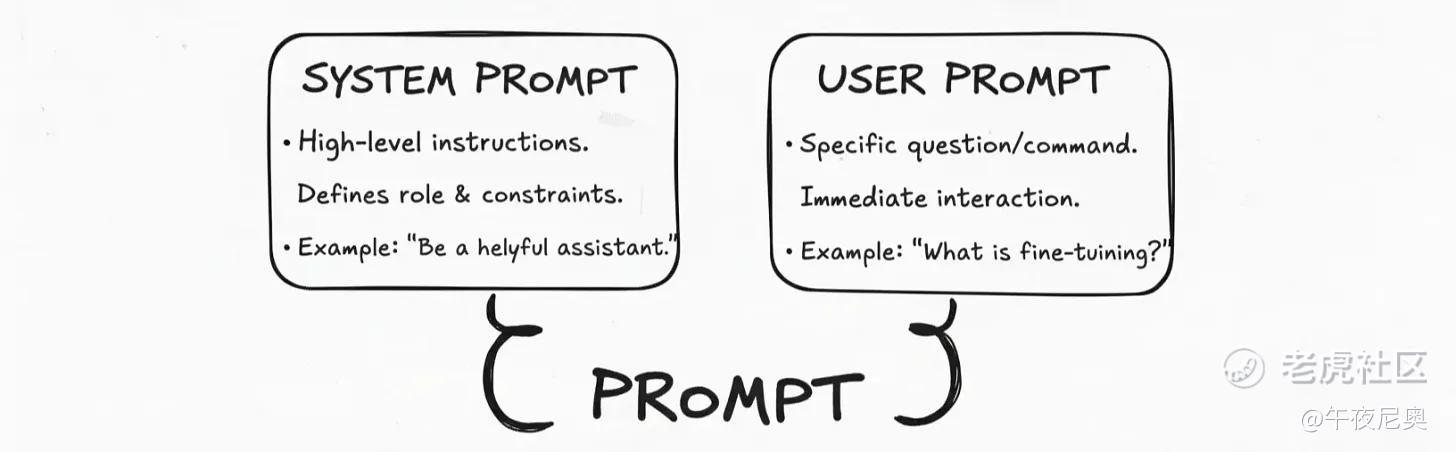
10. 提示词(Prompt):系统提示词 vs 用户提示词
-
系统提示词(System Prompt):高层级指令,定义模型角色和约束,
-
用户提示词(User Prompt):具体的问题或指令,即时交互
发送给模型的完整指令和上下文,就是 “提示词”。一个设计良好的提示词通常包含两部分:
-
系统提示词:设定模型的核心角色和边界,是每次交互都生效的 “永久指南”。比如 ChatGPT 可能有个隐藏的系统提示词:“你是一个贴心的助手,回答要清晰简洁,避免不安全或有偏见的内容。”
-
用户提示词:用户当下的具体问题或指令,比如 “什么是微调?”
模型会同时处理这两部分:系统提示词告诉它 “怎么表现”,用户提示词告诉它 “做什么”。这种分离能确保模型的回应始终贴心、不跑偏。
但对话很少只有一轮,要让模型记住上下文,就需要 “上下文窗口”。
11. 上下文窗口(Context Window)
聊天助手要实用,必须能处理后续问题。比如你问 “能换种方式解释吗?”,模型得知道 “那种方式” 指的是什么 —— 这就靠上下文窗口来管理 “记忆”。
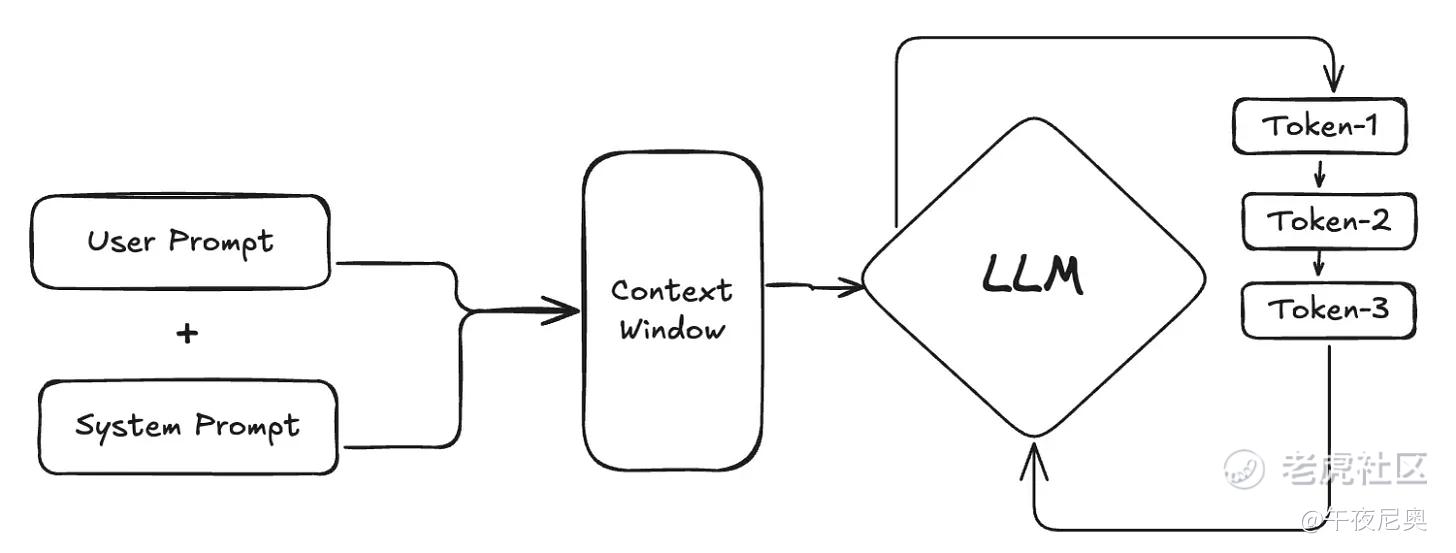
上下文窗口是模型一次能 “看到” 并处理的最大token数量,包括系统提示词、完整的对话历史,以及它正在生成的回应。模型看不到这个窗口之外的内容。
这个 “记忆上限” 很关键:如果和 ChatGPT、Claude 的对话太长,应用会自动缩短历史记录(通常删掉最早的消息),避免模型忘记近期上下文。
而在这个窗口内,提示词的结构会直接影响单个答案的走向。
12. 零样本学习(Zero-shot)vs 少样本学习(Few-shot)
这两个术语描述了两种控制模型输出的核心提示词设计方式,选择哪种取决于模型完成任务需要多少引导。
-
零样本提示(Zero-shot Prompting):只给指令,不给任何示例。完全依赖模型已有的能力理解并执行命令。比如问 ChatGPT“什么是微调?”,就是零样本请求 —— 相信对齐后的模型不用示例也能给出好答案。
-
少样本提示(Few-shot Prompting):既给指令,又在提示词里加几个 “示例”(称为 “shots”),明确期望的输出格式或风格。比如想让模型用三个简洁的要点总结文本,就可以先在提示词里给一个这样的总结示例,再让它处理新文本。
少样本提示能让模型的输出更可靠、格式更统一。
13. 推理与思维链(Chain-of-Thought,CoT)
有时候你会问 ChatGPT 这类复杂问题,需要多步推理才能回答。比如 “对比检索增强生成(RAG)和微调,哪种更适合解决幻觉问题?” 如果模型直接给答案,很容易出现逻辑错误。
这就是 “推理能力不足” 的问题。要解决这个问题,就可以用 “思维链(CoT)” 这种提示词技巧 —— 不用只问最终答案,而是在提示词里加一句简单的指令:“咱们一步步想”。
这会让模型按逻辑步骤推导:先定义 RAG,再定义微调,然后对比两者,最后得出结论。通过 “展示思考过程”,模型在复杂问题上的推理准确性会大幅提升。
现在一些专注于推理的新模型更进一步:它们自带 “一步步思考” 的能力,不用专门提示,会自动进行内部思考,比如谷歌 Gemini 2.5 Pro、OpenAI GPT-5 和 Anthropic Claude Opus 4.1 这类尖端模型,都有这种高级推理能力。
实时运行:按下回车后发生了什么?
14. 推理(Inference)
当 ChatGPT 收到完整提示词后,就开始生成答案 —— 这个训练好的模型产生输出的过程,就是 “推理”。
你看到答案逐字逐句出现,就是推理的实时过程:模型不是一次性写出完整句子,而是每次只预测下一个最可能的token,把它加入序列,再重复这个过程,直到生成一个特殊的 “序列结束”token,或者达到最大输出长度。
15. 延迟(Latency)
从你提问到收到完整答案的时间,就是 “延迟”—— 这是影响用户体验的关键因素,延迟太高会让 AI 显得又慢又迟钝。
因为推理是逐token生成的,延迟主要看两个指标:
-
首token时间(Time-to-first-token,TTFT):第一个答案字符出现的时间,这个指标越低越好,能让你知道 AI 正在工作;
-
token间隔时间:后续token生成的速度,决定了模型的 “打字速度”。
一个好用的聊天机器人,这两个延迟指标都得低。
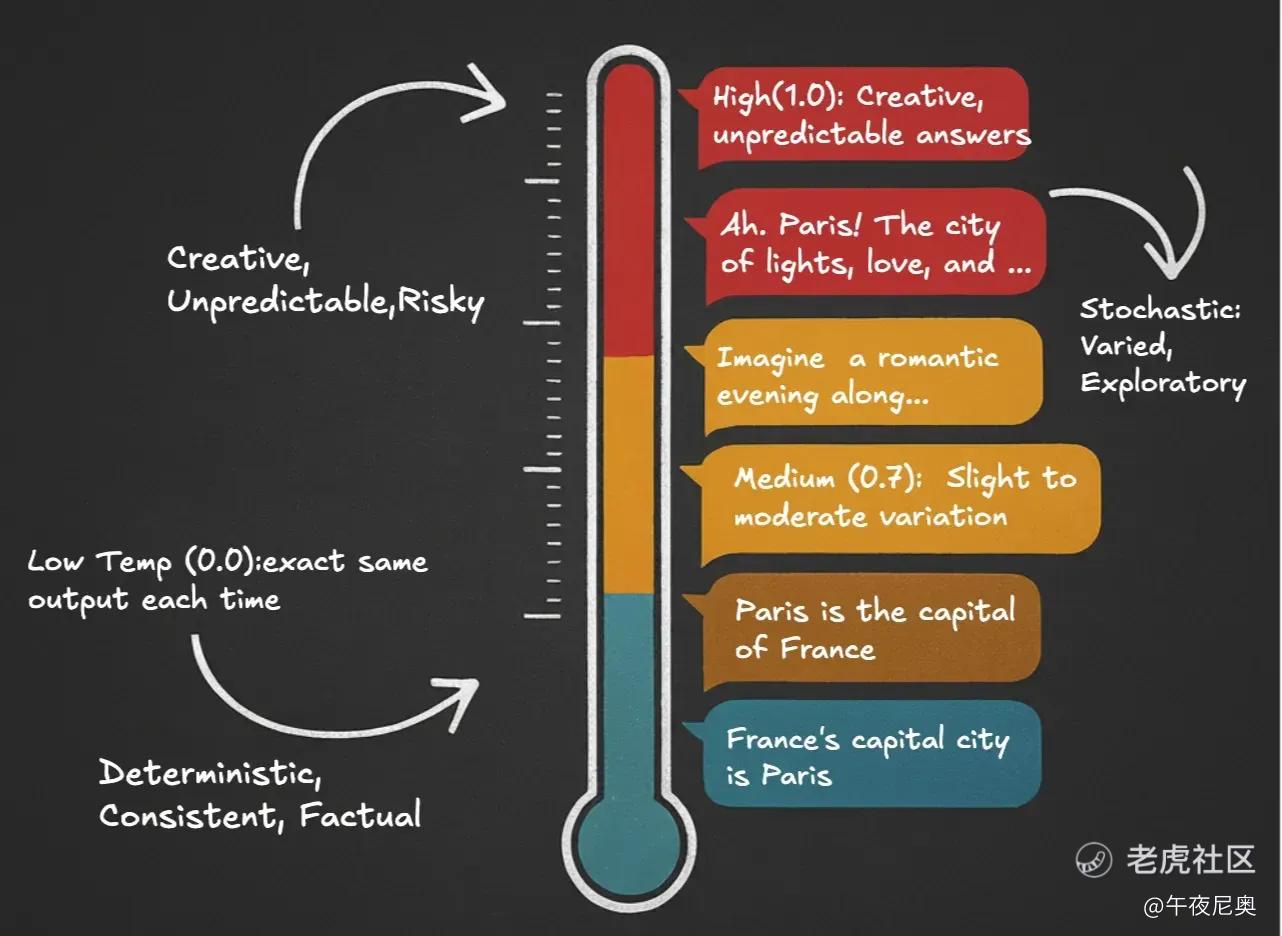
16. 温度(Temperature):确定性输出 vs 随机性输出
“温度” 这个参数,控制的是模型选择token时的随机程度。当你多次问 ChatGPT 同一个问题,它应该每次都给一样的答案吗?这就由温度决定。
-
高温(1.0):答案有创意、不可预测,属于 “随机性输出”。比如问 “巴黎是什么样的?”,可能会得到 “啊,巴黎!这座灯光之都、浪漫之都,想象一个傍晚漫步在……” 这类充满探索性的回答;
-
中温(0.7):答案有轻微到中等程度的变化;
-
低温(0.0):每次输出完全一样,属于 “确定性输出”。比如问 “巴黎是什么?”,会得到 “巴黎是法国的首都” 这种稳定、客观的答案。
确定性输出适合需要一致结果的场景(比如事实定义),随机性输出适合需要多样化表达的场景(比如 “换种方式解释”)。
架构与扩展:超越基础模型的能力
17. 接地(Grounding)
“接地” 的核心原则是:让大语言模型的输出只基于我们提供的、可验证的外部真实信息。
这是缓解幻觉问题的最直接方式之一 —— 不让模型依赖自己庞大但不可靠的 “内部记忆”,而是连接到可信数据源。如果没有相关信息,接地后的系统会直接说 “不知道”,而不是瞎猜。
18. 检索增强生成(Retrieval-Augmented Generation,RAG)
那怎么在实时场景中实现接地呢?答案就是 “检索增强生成(RAG)”—— 这种架构能在需要时连接知识库或外部数据源,提升答案准确性。
最典型的例子就是 Perplexity AI:你提问后,它不会只靠内部记忆回答,而是先搜索网页、找到相关来源,再把这些信息融入答案。RAG 的工作流程分三步:
-
检索(Retrieve):系统先搜索可信文档或网页,找到最相关的文本片段;
-
增强(Augment):把这些片段自动加入提示词,给模型一份 “标准答案 cheat sheet”;
-
生成(Generate):指示模型只基于检索到的证据生成答案。
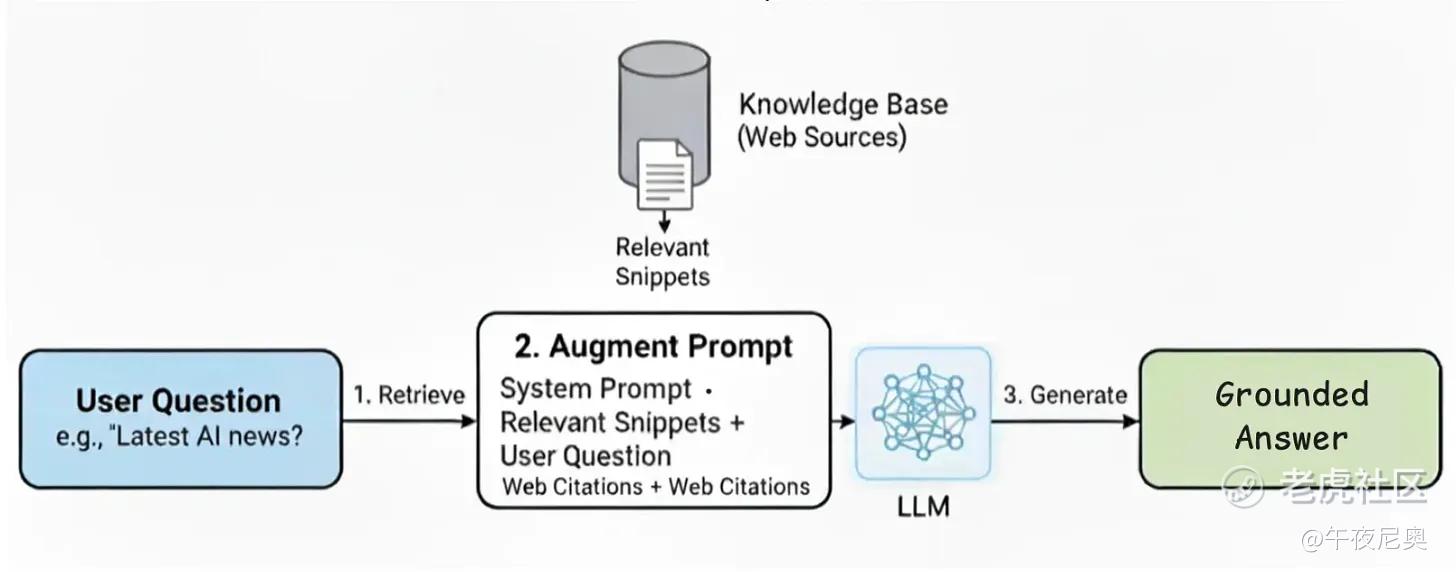
这样一来,每个回应都有可验证的来源,既提升了准确性,也让用户更信任输出。
19. 工作流(Workflow)vs 智能体(Agent)
构建具备 “行动能力” 的 AI 系统,主要有两种方式,各自的控制程度和灵活性不同:
-
工作流(Workflow):开发者定义固定、可预测的步骤序列,LLM 只是这个过程中的一个组件。比如 Perplexity 这类 RAG 系统,永远遵循 “检索→增强→生成” 的固定流程,可靠性高、易控制;
-
智能体(Agent):让 LLM 充当核心 “大脑”,自主主导流程。不给固定路径,而是给它一个目标和一套工具(比如网页搜索、计算器),让它动态规划该用什么工具、按什么顺序用,来实现目标。智能体更灵活,但可预测性较低。
20. 智能体 AI(Agentic AI)
现在大多数聊天机器人都是 “被动响应型”:等你提问,才给一个答案。而智能体 AI 要解决的核心问题是:系统能自主规划并完成多步骤任务吗?
智能体 AI 让 LLM 能规划行动、执行任务,以达成复杂目标 —— 这让模型从 “工具” 变成了 “系统大脑”。
比如你不用只问 “什么是微调?”,而是可以说 “做一份关于微调的学习指南”。智能体助手会自主搜索文档、提取核心概念、整理成结构化总结,全程不用你额外输入。
现在已经有这类工具的早期版本了:比如 Gemini Deep Research、OpenAI Deep Research、Perplexity Deep Research,能自主搜索来源、收集见解、生成有条理的输出;编码领域的 Claude Code 和微软 Copilot Agent Mode,能规划并完成多步骤编程任务,不止于研究。
模型的不同形态:大语言模型家族与权衡
21. 专有模型(Proprietary)vs 开源模型(Open-Source)
用 LLM 开发应用时,迟早会面临一个实际选择:选哪种模型?
如果只是实验,可能无所谓,大概率会从 ChatGPT 这类专有 API 开始(好用又易获取)。但如果要大规模部署、降低成本或定制系统,模型类型的选择就至关重要了。
主要分三类,各自在成本、控制度和复杂度上有明显权衡:
-
专有模型(Proprietary Models):由公司拥有和运营(比如 OpenAI 的 GPT-5),通过付费服务访问,无法查看或修改内部工作机制。很多开发者从这里起步,因为能力强、API 易集成;
-
开放权重模型(Open-Weight Models):公开模型权重(比如 Meta 的 Llama 3.1、Mistral 7B、谷歌的 Gemma 2),但不算完全 “开源”—— 训练数据和方法通常不公开,许可证也可能有限制。这类模型透明度高、可自行部署,还能享受尖端性能;
-
开源模型(Open-Source Models):真正意义上的开放,不仅公开权重,还提供训练代码、数据和方法,且基于宽松许可证。控制力和可复现性最强,但性能通常不如顶尖专有模型或开放权重模型。
22. 应用程序接口(API)
不管选哪种模型(专有、开放权重、开源),你的应用都需要一种方式和它 “沟通”—— 大多数时候,尤其是入门阶段,这种沟通是通过 API 实现的。
API(Application Programming Interface)就是应用和模型提供商的 “沟通桥梁”:你发送提示词,它返回生成的文本。
可以这么理解:就像用外卖软件点餐,软件不做饭,只是把你的订单发给餐厅,再把做好的饭送到你手上。你的代码也不会运行庞大的 LLM,而是通过 API 向提供商的服务器发送请求,模型生成回应后再返回给你。
比如你在浏览器里用 ChatGPT,并不是在笔记本电脑上运行 GPT-5,而是你的消息通过 API 发送到 OpenAI 的服务器,生成答案后再传回你的屏幕。
就算是在自己设备上用开放权重模型,通常也会通过 API 调用 —— 这样应用的交互方式能保持一致。
23. 小型语言模型(SLM)
大型模型虽然强大,但运行成本很高。而 “小型语言模型(Small Language Model,SLM)” 的出现,提供了另一种选择。
SLM 参数少(通常不到 150 亿),专门优化特定任务。小巧的体型让它们速度快、运行成本低,还能在笔记本电脑、智能手机这类本地设备上运行。
比如微软的 Phi-3 和 Mistral 的 7B,都是能在消费级硬件上运行的 SLM。这意味着应用可以提供私密聊天、离线助手、本地副驾驶等功能 —— 数据存在自己的手机里,不用上传到云端,既省钱又能离线使用。
24. 模态(Modality)与多模态(Multimodality)
现在很多模型只能处理一种输入:文本 —— 这就是 “模态”。如果你上传一张图表,问 “这张图是什么意思?”,纯文本模型就无能为力了。
这时候就需要 “多模态” 模型 —— 能同时处理文本、图片、音频等多种输入,让答案更贴合上下文、更实用。
现在已经有这类系统了:GPT-4o 和 Gemini 1.5 Pro 能同时接收文本、图片和音频,交互更自然。
顺便说下图像生成:很多工具会把 LLM 和扩散模型(diffusion model)结合 —— 扩散模型从噪声开始,逐步 “去噪”,在文本引导下生成图片(比如 Stable Diffusion、Midjourney、DALL・E)。还有些模型本身就是多模态的,能直接结合文本和图像生成,不用依赖外部工具。
第一种方式模块化、灵活;第二种更无缝,两者在质量、控制力、速度和成本上各有权衡。
25. 推理模型(Reasoning Models)
推理模型是一类新型 LLM,专门优化多步骤问题解决。它们不会急于回答,而是会 “先思考、记笔记”,帮助自己专注任务、对比选项、遵循规则、做简单计算,或回答 “先解释再决策” 的问题。
你可以把它们理解为自带 “一步步思考” 功能的模型。如果任务的核心是 “思考”—— 比如整合观点、权衡利弊、串联步骤,就适合用推理模型。
当然也有权衡:这类模型通常运行时间更长、成本更高。而简洁的指令模型,更适合快速查定义、短文本改写或简单查询。
衡量性能:怎么判断模型好不好用?
26. 基准测试(Benchmarks)
选模型时(比如 GPT-4o、Llama 3.1、Claude 3),怎么客观对比它们的原始能力?答案是 “基准测试”。
基准测试是标准化的测试,用来衡量和对比不同 LLM 的能力,覆盖多种任务:常识(比如 MMLU)、编码(比如 HumanEval)、逻辑推理(比如 BBH)等。
让不同模型做同一套基准测试,就能得到分数,进而排名、找出它们的优缺点 —— 这在实际应用前非常重要。
要注意两点:
-
基准测试是 “任务特定” 的:编码能力最强的模型,不一定擅长推理或总结;
-
新的基准测试不断出现,随着模型升级和任务重心变化,排名也会变动。
两个常用的真实世界基准测试排行榜:
-
Hugging Face Open LLM Leaderboard:对比开放权重模型在 MMLU、HumanEval、GSM8K 等任务上的表现;
-
Chatbot Arena(由 LMSYS 推出):通过众包方式让用户一对一对比 ChatGPT、Claude、Gemini 等聊天模型,按用户偏好排名。
27. 指标(Metrics)
基准测试分数高,说明模型有潜力,但不代表它在你的应用里表现好。就算是顶尖模型,也可能因为提示词设计差、检索到无关文档或输出不清晰,给出糟糕的答案。
所以还需要 “指标”—— 针对具体使用场景的质量评估标准。比如在 RAG 类聊天助手中,常用两个指标:
-
忠实度(Faithfulness):答案是否只基于检索到的文档?(用来衡量幻觉控制效果);
-
答案相关性(Answer Relevance):答案是否直接回应了用户的问题?(衡量检索和接地的质量)。
指标能帮我们从 “这个模型总体好不好?”,聚焦到 “这个系统对我们的用户好不好用?”。
28. 大语言模型作为评判者(LLM-as-Judge)
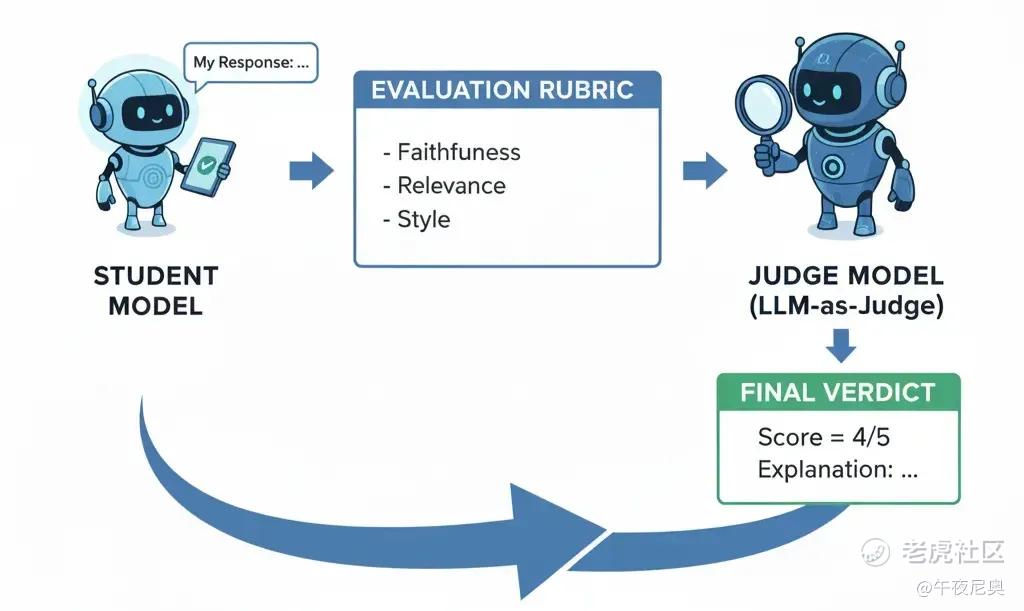
有了忠实度、相关性这类指标,怎么在成千上万次对话中评估它们?手动检查每一个答案根本不现实 —— 这就是 “大规模评估” 的难题。
解决方案是 “LLM-as-Judge”:用一个强大的尖端 LLM(作为 “裁判”),自动评估另一个模型(作为 “学生”)的输出。
具体做法:给裁判模型提供原始提示词、学生模型的回应,以及基于指标设计的评估标准,裁判会返回分数和评估说明。
这让大规模快速、一致的评估成为可能。比如很多研究实验室现在用 GPT-5 或 Claude Opus 当 “裁判”,评估小型模型在忠实度、推理能力、风格等方面的表现。
29. 幻觉(Hallucination)
大语言模型的一个主要问题是 “幻觉”—— 自信地编造虚假信息。
LLM 的目标是预测下一个可能的词,而不是核实事实。这导致它可能生成听起来很有道理,但完全是编造的内容:比如伪造不存在的研究论文引用、虚构法庭案例、编造错误的人物生平。
危险之处不在于错误本身,而在于这些错误被呈现得非常有说服力,很难察觉。在医疗、金融、法律等领域,一次幻觉就可能造成严重危害。
总结
大语言模型是高级的模式匹配者,而不是真相来源。它们的优势是语言流畅、有一定推理能力和广博的知识,但也存在幻觉、偏见、知识过时等短板。
关键在于如何围绕这些特点设计系统:选择合适的提示词技巧、检索方式、微调策略和护栏机制。
如果只能记住一点,那就是:
了解这些基础概念,能让你更有效地使用 LLM,清晰看清它们的局限 —— 这正是区分 “把 LLM 当作魔法或完全不可靠工具” 和 “构建可信任系统” 的关键。
精彩评论