在2024年4月10日,$谷歌(GOOG)$ 推出了具有划时代意义的下一代Transformer模型——Infini-Transformer。该模型具备处理无限长度输入内容的能力,且不会增加额外的内存和计算需求。ChatGPT是基于第一代的 Transformer模型。
对于人工智能来说,内存资源是神经网络模型进行高效计算的必要条件。然而,由于Transformer中的注意力机制在内存占用和计算时间上都表现出二次复杂度,所以基于Transformer的大模型就更加依赖内存资源。
Infini-Transformer通过引入一个创新的压缩内存系统,能够将使用后的数据片段存储于压缩内存中,从而持续维护完整的上下文信息。这一机制确保了内存使用保持在恒定水平,即使不断添加新的内容,也不需要额外的内存资源。
Infini-Transformer模型通过其核心技术Infini-attention在处理极长序列数据方面展现了卓越的性能。这种新型注意力机制能够同时计算并整合局部与全局上下文状态,通过这种方法,它不仅能提供更加丰富和细致的数据处理,还能显著提高模型的输出效果。 $微软(MSFT)$

Infini-attention机制的一个显著特点是它为每个注意力头部配备了并行压缩内存,这些内存单元能够有效地存储和回溯之前的计算状态,极大地减少了重复计算的需要。这种设计使得模型在保持计算效率的同时,还能处理更长的数据序列。

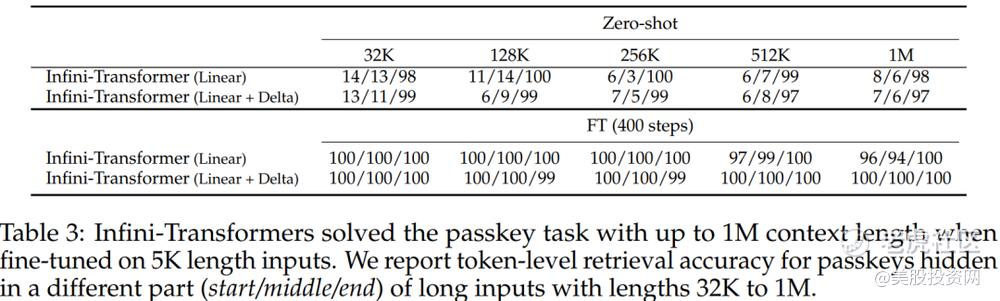
在实际应用中,Infini-Transformer在PG19和Arxiv-math数据集上的表现尤为突出。在这些长上下文语言建模任务中,它不仅在性能上超过了基线模型,而且在内存效率上实现了显著的优化,达到了114倍的压缩比。此外,在1M序列长度的密钥检索任务中,仅通过在5K长度的输入上进行微调,Infini-attention已成功完成了任务,充分展示了其在处理超长序列时的强大能力。 $苹果(AAPL)$
此外,谷歌还发布了Mixture-of-Depths(MoD)技术,这是一种变革传统Transformer计算模式的方法。MoD通过在大型模型中动态分配计算资源,优化了计算的分布和效率。它跳过了部分非必要的计算步骤,显著提高了模型的训练效率和推理速度。具体来说,MoD通过限制自注意力和多层感知器(MLP)计算的token数量,促使模型聚焦于最关键的信息。这种策略不仅节省了计算资源,还通过预定义的token数量和静态计算图,在模型深度和时间上动态扩展了计算量,实现了更高的计算效率。
实验结果表明,使用MoD技术的Infini-Transformer在等效的计算量和训练时间上,每次前向传播所需的计算量更少,训练后的采样步进速度提高了50%。这种高效的资源利用不仅匹配了传统模型的基线性能,还在许多方面超越了它。
这些技术的结合,开启了一种全新的无限上下文处理时代,使得Infini-Transformer不仅在理论上,在实际应用中也展现了强大的潜力和广阔的应用前景。这标志着大模型的一个重要进步,预示着未来AI技术在处理复杂和长序列数据方面的巨大潜能。
精彩评论