3.5 行业大模型
市场定义:
行业大模型是指经过后训练或者微调,具备金融、医疗等明确的行业属性,致力于更好地完成特定任务。
甲方终端用户:
大型企业IT部门
甲方核心需求:
企业需要有行业属性的大模型,致力于更好地完成特定任务。并且,行业大模型需要是合规可信的,才能保证其可用性。美国政府持续扩大针对中国芯片的出口限制,加剧了国内算力供应的压力,AI芯片价格持续走高且一卡难求。企业通常需要“行业大模型+算力”的综合解决方案来应对“卡荒”,解决对算力的后顾之忧。
需要有行业属性的大模型。目前,通用大模型一般是基于广泛的公开文献与网络信息来训练的,属于“泛行业”,没有特定行业属性。企业较难指望通用大模型拿来就可用和好用。因此,企业更希望采建设具备自身所属行业属性的大模型,建设方式为私有化部署或公有云MaaS。
需要合规可信的大模型,保证其可用性。用于预训练的数据一般源自公开文献与网络信息,这种数据不仅数据噪音大,并且中文语料少。这不仅影响大模型生成内容的准确度,更由于生成内容受西方价值观影响较深,致使企业担心合规问题。大模型可信度问题主要在于存在大模型幻觉,“一本正经地胡说八道”让用户不敢使用大模型生成结果。
企业需要“行业大模型+算力”的综合解决方案来应对“卡荒”。行业大模型的微调、推理需要高端AI芯片作为算力底座。但是,美国政府持续扩大针对中国芯片的出口限制,加剧了国内算力供应的压力,AI芯片价格持续走高且一卡难求。企业通常需要“行业大模型+算力”的综合解决方案来应对“卡荒”,解决对算力的后顾之忧。
厂商能力要求:
企业更希望建设具备自身所属行业属性的大模型。因此,厂商要以高质量行业大数据作为行业大模型的属性保障。为保证行业大模型可用性,厂商需要具备应对合规、可信难题的解决方案。为应对“卡荒”,厂商需要具备足够的高端AI芯片,并具备以华为升腾为代表的国产化芯片替代方案。
厂商要以高质量行业大数据作为行业大模型的属性保障。企业更希望建设具备自身所属行业属性的大模型。因此,高质量行业大数据是打造行业大模型的基础和门槛。大模型厂商一般具有技术积累,但在数据方面较为薄弱。它们主要依托公域数据训练基础大模型,或者结合用户私有数据训练或微调出企业大模型。它们由于缺乏行业深耕与数据沉淀,导致自有数据难以支撑行业大模型的训练。为保证行业大模型的持久生命力,厂商应具备动态更新高质量行业大数据的能力,而非只掌握一批“静态数据”。
具备应对合规、可信难题的解决方案。厂商需要具备深厚的中文语料积累和价值观对齐机制,来提升大模型生成结果的合规性。在可信方面,厂商需要具备缓解大模型幻觉的解决方案,包括知识图谱、RAG、向量数据库、提示词工程等。
厂商需要具备足够的高端AI芯片,并具备以华为升腾为代表的国产化芯片替代方案。企业需要“行业大模型+算力”的综合解决方案来应对“卡荒”。相应地,厂商需要具备足够的高端AI芯片,才能满足企业需求。鉴于美国芯片供应的不确定性持续增加、国产芯片的崛起以及国产化替代事业的推进等多重因素,将国产芯片应用于微调、推理场景是大势所趋。厂商应具备以国产化芯片替代方案。当前,华为升腾910是最热门的替代方案。在交付方面,大模型一体机已经成为主流交付形态之一。
入选标准说明:
1. 符合行业大模型市场分析的厂商能力要求;
2. 近一年厂商在该市场至少服务1家企业(含POC)
代表厂商评估:

拓尔思
厂商介绍:
拓尔思信息技术股份有限公司(简称“拓尔思”)成立于1993年,是一家专业的大数据、人工智能和数据安全产品及服务提供商。拓尔思坚持核心技术自主研发,拥有50+专利、1000+软件著作权,在搜索型数据库、自然语言处理(NLP)技术的技术创新和应用场景落地等方面保持领先地位。
产品服务介绍:
拓尔思打造多模态认知大模型——拓天大模型,具备通用的语义理解、多轮对话、内容生成、多模态交互、知识型搜索引擎等能力。并且,拓尔思以拓天大模型为基础,依托在各行业的数据积累推出金融、媒体、政务、舆情、公安等多个行业大模型。
图9:拓尔思行业大模型示例

厂商评估:
在数据方面,拓尔思以2000亿+高质量数据作为行业大模型的质量保障。在应用方面,合规和可信度问题阻碍大模型落地应用。拓尔思依托自身深厚的中文语料积累和价值观对齐机制,可有效提升大模型生成结果的合规性,并综合运用“知识图谱+RAG+向量数据库”三种手段,致力于缓解大模型幻觉,提升其生成结果的可信度。在部署方面,拓尔思提供灵活的部署模式选择,满足不同企业的需求。在成功案例方面,拓尔思依托AI工程化能力,已在多个行业实现大模型商业化应用落地。
拓尔思以2000亿+高质量数据作为行业大模型的质量保障。高质量行业大数据是打造行业大模型的基础和门槛。大模型厂商一般具有技术积累,但在数据方面较为薄弱。它们主要依托公域数据训练基础大模型,或者结合用户私有数据训练或微调出企业大模型。它们由于缺乏行业深耕与数据沉淀,导致自有数据难以支撑行业大模型的训练。
拓尔思自2010年开始自建互联网数据中心,对产业金融、新闻资讯、网络舆情等信息进行采集,日均增长数据超3.5亿条,数据中心总数据量超2000亿条,并且可以实现重点数据分钟级更新。这些数据主要源自全国数字报刊、各级新闻网站以及拓尔思的业务沉淀,数据质量较高。
拓尔思着力解决大模型合规与可信度问题,保证其可用性。合规和可信度问题阻碍大模型落地应用。大模型合规问题主要在于中文语料少,大模型生成内容受西方价值观影响较深。大模型可信度问题主要在于存在大模型幻觉,“一本正经地胡说八道”让用户不敢使用大模型生成结果。拓尔思依托自身深厚的中文语料积累和价值观对齐机制,可有效提升大模型生成结果的合规性,并综合运用“知识图谱+RAG+向量数据库”三种手段,致力于缓解大模型幻觉,提升其生成结果的可信度。
在合规方面,拓尔思主要采集主流官方机构可公开访问的数据,如各级政府部门、主流媒体等,这些机构所有对外公开的信息均严格履行“三审三校”制度。所有采集源由人工整理配置,保证了数据源头的“纯净”和完整性。拓尔思采用专家规范化标引+机器自动标引相结合的方式,对采集的内容资讯进行“精加工”,包括低噪、去重、数据结构化、数据归一化、内容标签化、属性知识化、安全合规核查等,实现数据与主流价值观对齐。
在可信度方面,拓尔思综合运用“知识图谱+RAG+向量数据库”,三管齐下,缓解大模型幻觉。一是知识图谱,其优势在于知识间的逻辑关系非常清晰,通过将知识库和大模型进行结合可以提升生成解决的可解释性。二是RAG(检索增强),是指在大语言模型推理生成答案时,额外检索调用外部知识,然后综合其检索结果进行回答生成,相比单纯依靠模型训练,该技术的引入可以大幅提升回答的准确性。三是向量数据库,通过将权威、可信的信息转换为向量,并将它们加载到向量数据库中,数据库能为大模型提供可靠的信息源,从而减少模型产生幻觉的可能性。
拓尔思提供灵活的部署模式选择,满足不同企业的需求。拓尔思可将行业大模型通过公有云API的方式为企业提供服务,也支持结合企业私有数据和个性化场景需求,以私有化部署的方式为企业提供定制化大模型。在私有化部署方面,拓尔思通过剪枝、量化、稀疏、蒸馏等部署优化方案,可有效降低大模型对算力资源的要求。并且,拓尔思推出的垂类大模型参数在百亿级,当前市场主流推理卡单卡就可以满足运行要求,实现模型轻量化部署。
为帮助企业选择最合适的部署模式,拓尔思基于实践经验构建了一套“大模型部署模式考虑要素”方法论。该方法论包含六个要素,分别为灵活性需求、高性能和低延迟需求、成本效益衡量、专业技术团队的成熟度、数据治理情况、数据隐私与安全性需求。
拓尔思依托AI工程化能力,已在多个行业实现大模型商业化应用落地。对于企业而言,解决单点问题价值度不大,它们需要大模型厂商为其解决系统性问题。因此,AI工程化能力成为大模型商业化应用落地的关键。拓尔思在AI工程化方面有四项优势,一是产品自主可控,二是私有化部署,三是专业、稳定的服务团队,四是灵活的服务模式。
拓尔思依托AI工程化能力,已在多个行业实现大模型商业化应用落地。如,拓天媒体大模型已在人民日报和浙江日报传播大脑等媒体进行落地实践,范围覆盖内容生产、定向化训练、“新闻+政务服务”等多种场景;拓天金融大模型为某股份制银行打造智能消保助手,赋能消费者权益保护全流程,降低投诉率。
典型客户:
人民日报、浙江日报传播大脑、某股份制银行等
3.6 企业大模型
市场定义:
企业大模型是指经过后训练或微调,面向企业私有化部署的大模型,助力企业从数据驱动升级为智能驱动。
甲方终端用户:
大型企业IT部门
甲方核心需求:
企业有三项核心需求。一是利用企业大模型助力自身从数据驱动升级为智能驱动。二是找到能满足企业对数据隐私与合规需求的企业大模型。三是找到具备高可用性的企业大模型。
助力企业从数据驱动升级为智能驱动。当前,头部企业已实现或部分实现数据驱动,生产经营决策的专业性、科学性和敏捷性相较之前显著提升。在大模型时代,它们希望借助企业大模型,在各个业务场景和流程中构建智能助手,通过“人+智能助手”的新型协作方式降低企业运营成本。例如,某零售企业赋能一线员工,通过配备智能助理提升员工工作效率,进而达到精简人员和降低运营成本的目的。
满足企业对数据隐私与合规需求。随着数据量的不断增加,数据隐私保护变得越来越重要。大模型的研发和应用过程中可能存在数据泄露风险,尤其是当企业调用对第三方底层大模型公网API时,数据安全问题更为突出。中国工商银行首席技术官吕仲涛曾称:数据隐私保护也存在隐患,大模型训练数据来源于互联网、业务数据,这些数据可能涉及大量用户隐私,需要通过隐私计算、联邦学习等方式进行保护。企业大模型则可以更好地保护商业机密和数据隐私。
除数据隐私需求外,数据合规同样重要。《生成式人工智能服务管理暂行办法》明确规定:在生成式人工智能技术研发过程中进行数据标注的,提供者应当制定符合本办法要求的清晰、具体、可操作的标注规则;开展数据标注质量评估,抽样核验标注内容的准确性;对标注人员进行必要培训,提升尊法守法意识,监督指导标注人员规范开展标注工作。除此之外,其他法律法规同样有关于数据合规的要求,企业也需要遵守。
具备高可用性的企业大模型。基础大模型一般由先进AI公司建设,通识能力较强,但其缺少行业和企业专业知识,对企业价值有限。对于头部企业而言,通常引入业界领先的基础大模型,通过后训练或微调方式自建企业大模型。为保证企业大模型的可用性,企业对数据处理能力、训练速度、推理速度提出较高需求。
厂商能力要求:
厂商需要满足三项能力要求。一是提供企业大模型端到端工具链。二是具备数据隐私保障技术和数据全流程合规能力。三是在数据工程建设、大模型工程化以及降低大模型参数量方面有深厚积累。
提供企业大模型端到端工具链。厂商需具备算力资源、训练环境、企业大模型、应用开发平台、AI小模型等端到端工具链。“端到端”有利于发挥企业大模型深度价值,实现对企业上层业务的全面赋能。“工具链”有利于企业实现大模型训推及应用开发能力内化,摆脱对厂商的依赖。
具备数据隐私保障技术和数据全流程合规能力。大模型隐私性保障技术主要包括加密存储、差分隐私、同态加密、安全多方计算、模型水印和指纹等。数据全流程合规能力包括厂商需要具备涵盖数据准备、标注、训练、运营全流程的合规能力。
图10:数据全流程合规能力

在数据工程建设、大模型工程化以及降低大模型参数量方面有深厚积累。随着数据集规模的增大,数据管理难度也在攀升,需持续提升大模型数据清洗的工程化能力,并从单一的结构化数据转向多模态的全领域数据。
随着大模型参数规模的提升,训练过程所需的计算资源也呈现指数级增长。现有计算集群在进行大规模并行训练过程中,由于硬件故障等原因,稳定性仍存在较大问题,厂商需提升训练任务失败时快速定位问题的能力,保障训练效率。
企业大模型的参数量并非越大越好,推理速度随着参数量增加会同步降低,同理,降低大模型参数量则有利于推理速度。因此,对应的厂商能力要求是找到大模型推理效果和推理速度的最佳平衡点。
入选标准说明:
1. 符合企业大模型市场分析的厂商能力要求;
2. 近一年厂商在该市场至少服务1家企业(含POC)。
代表厂商评估:

滴普科技
厂商介绍:
北京滴普科技有限公司成立于2018年,定位为数据智能基础设施提供商。以Data+AI为核心战略,滴普科技打造了实时智能湖仓平台FastData、企业大模型Deepexi、智能体平台FastAGI、训推一体机Fast5000E等在内的数据智能产品体系,助力企业实现从数据驱动到智能驱动的升级。目前,滴普科技已成功服务200余家知名大中型企业,包括中国石油、兴业证券、航天烽火、重庆机电、陕药集团、长安新能源、纳爱斯集团、九洲电器等。
产品服务介绍:
企业大模型Deepexi由滴普科技打造,包括智能体平台FastAGI、训推一体机Fast5000E、模型应用Deinsight等产品,通过与另一产品实时智能湖仓平台FastData 相结合,能够为企业大模型训练提供服务,包括数据训练、调优、部署以及推理等功能,帮助其快速构建行业专属大模型。
图11:企业下一代数据智能体系架构
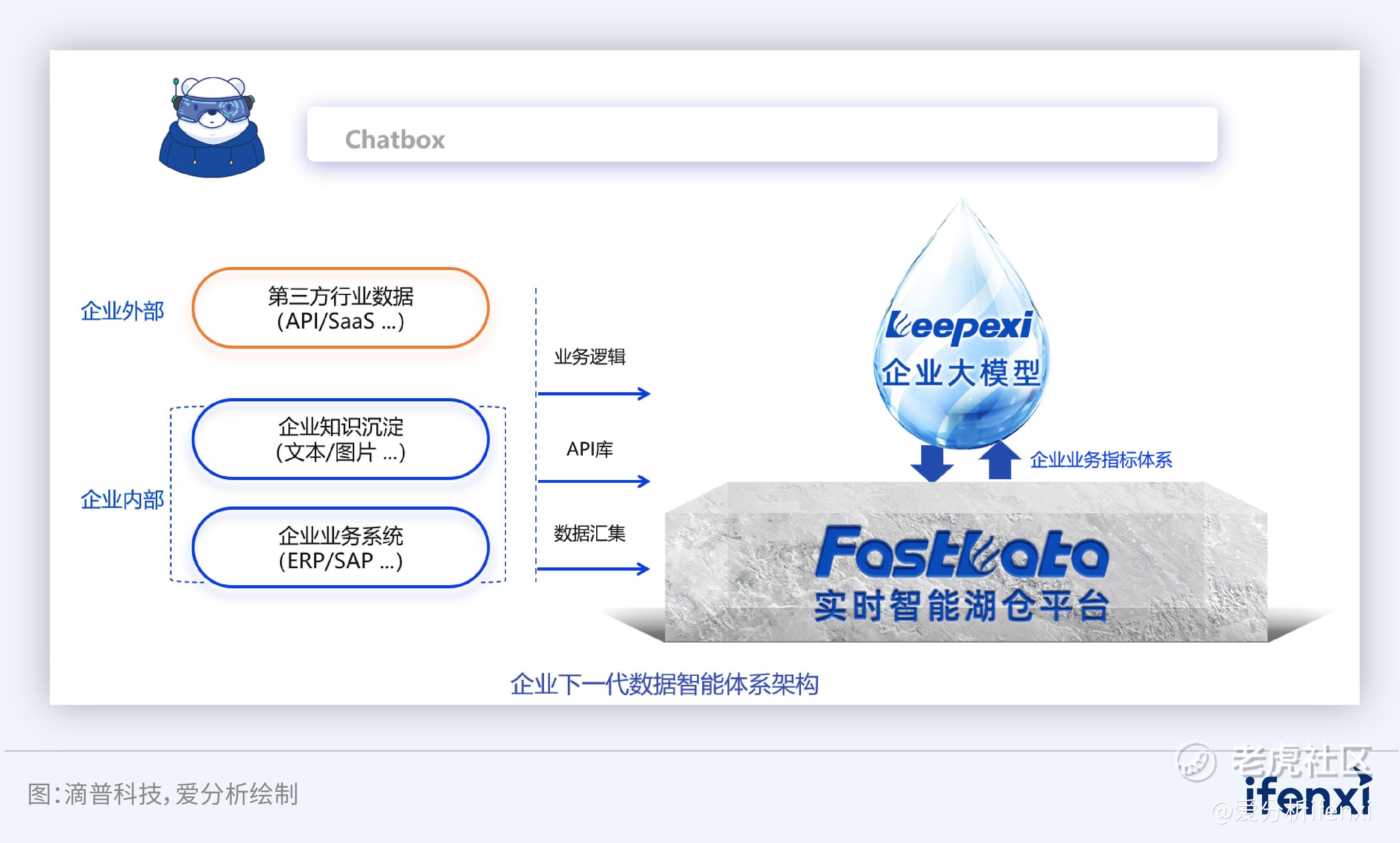
企业大模型Deepexi经过中文预训练、SFT、RLHF等方式精调,具备较强的中文知识与推理、数据分析、代码生成、图表生成等能力。智能体平台FastAGI包含知识智能体 DocAgent、数据智能体 DataAgent、插件智能体 Plugin Agent等工具,利用大语言模型的技术突破,实现交互式精确检索数据/指标,生成丰富数据图表,实现自动调用系统API完成业务需求;同时,基于语义理解能力、个性化与自适应等核心能力,通过知识提取、组织、生成关键知识工程,实现企业知识的精准检索及问答,提供专业、高效、准确的智能问答体验。训推一体机Fast5000E基于Deepexi模型,能够助力企业搭建高性能算力平台,大大提升训练效率,降低用户使用门槛。Deinsight基于滴普科技积累的行业知识库,能够为企业打造行业大模型及相关应用落地。
厂商评估:
在数据准备方面,滴普科技打造了实时智能湖仓平台FastData,实现多模态数据的高性能、低成本存算,为企业应用大模型做好数据准备。在解决方案方面,滴普科技提供大模型端到端解决方案,帮助企业实现从数据驱动到智能驱动的升级。在赋能范围方面,滴普科技把大模型打造成“企业服务智能体”,联通各个系统实现整体赋能。在项目经验方面,滴普科技已落地多个大模型项目,为企业带来可验证的业务价值。
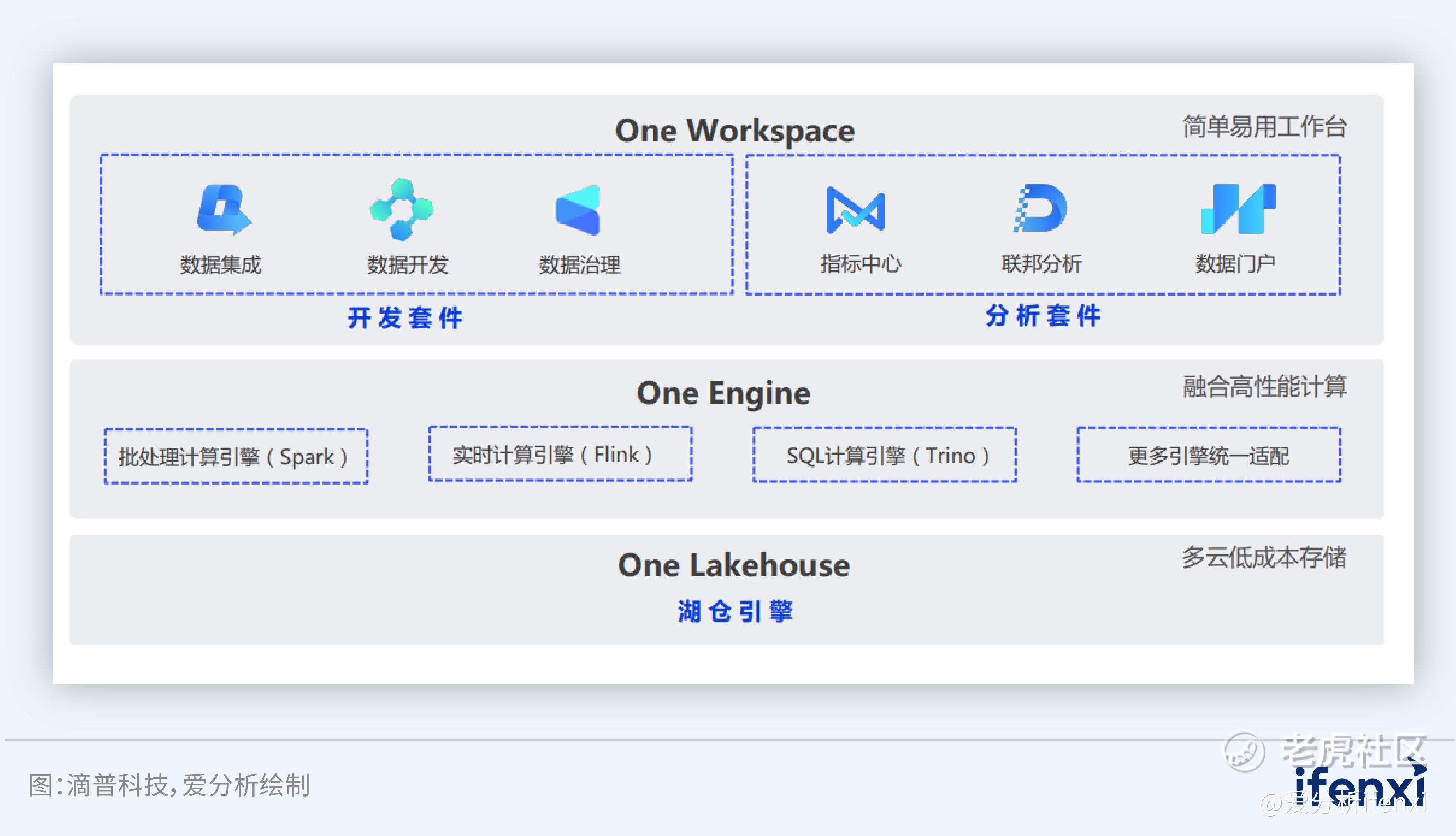
滴普科技打造实时智能湖仓平台FastData,实现多模态数据的低成本、高性能存算,为企业应用大模型做好数据准备。滴普科技基于Data Fabric架构,打造了实时智能湖仓平台FastData,帮助企业建立统一治理、流批一体、湖仓一体的云原生数据智能平台,实现海量数据实时分析,成为支撑企业数字化转型的核心数据基础设施。FastData对多模态的数据能够进行低成本、高性能的存算,为企业应用大模型做好数据准备。在存储方面,FastData具备针对多模态数据存储的核心算法,名为One Lakehouse湖仓引擎,可以实现统一的多模态数据目录和统一的访问接口,进而做到低成本存储。在计算方面,滴普科技解决方案名为One Engine,包括批处理计算引擎(Spark)、实时计算引擎(Flink)、SQL计算引擎(Trino)等,One Engine知识多引擎统一适配,实现高性能计算。
图12:FastData产品架构图
滴普科技提供大模型端到端解决方案,帮助企业实现从数据驱动到智能驱动的升级。企业大模型Deepexi包含智能体平台FastAGI、训推一体机Fast5000E等核心产品,能够为企业搭建私有化大模型训练提供高质量的数据准备、模型训练、调优、部署及推理服务,可以快速地构建企业内不同领域的垂直类模型以及对应的智能应用的能力,帮助企业实现从数据驱动到智能驱动的升级。FastAGI是滴普科技基于AI Agent的核心能力打造的智能体平台,包含知识智能体DocAgent、数据智能体DataAgent等工具:DocAgent结合了检索增强生成(RAG)技术,支持各类文档数据的管理,旨在通过向量检索技术和大型语言模型(LLM),提升内容生成的能力和精准度,基于语义理解能力、个性化与自适应等核心能力,通过知识提取、组织、生成关键知识工程,实现企业知识的精准检索及问答,提供专业、高效、准确的智能问答体验;数据智能体 DataAgent基于 Deepexi-Coder模型提供的MQL能力,可以与已有的企业级数仓和数据平台进行对接,根据交互式问答和数据权限,精确检索数据/指标,生成丰富的数据图表和报告,沉淀业务的理解和问题的解决方案能力。
图13:滴普科技产品整体架构
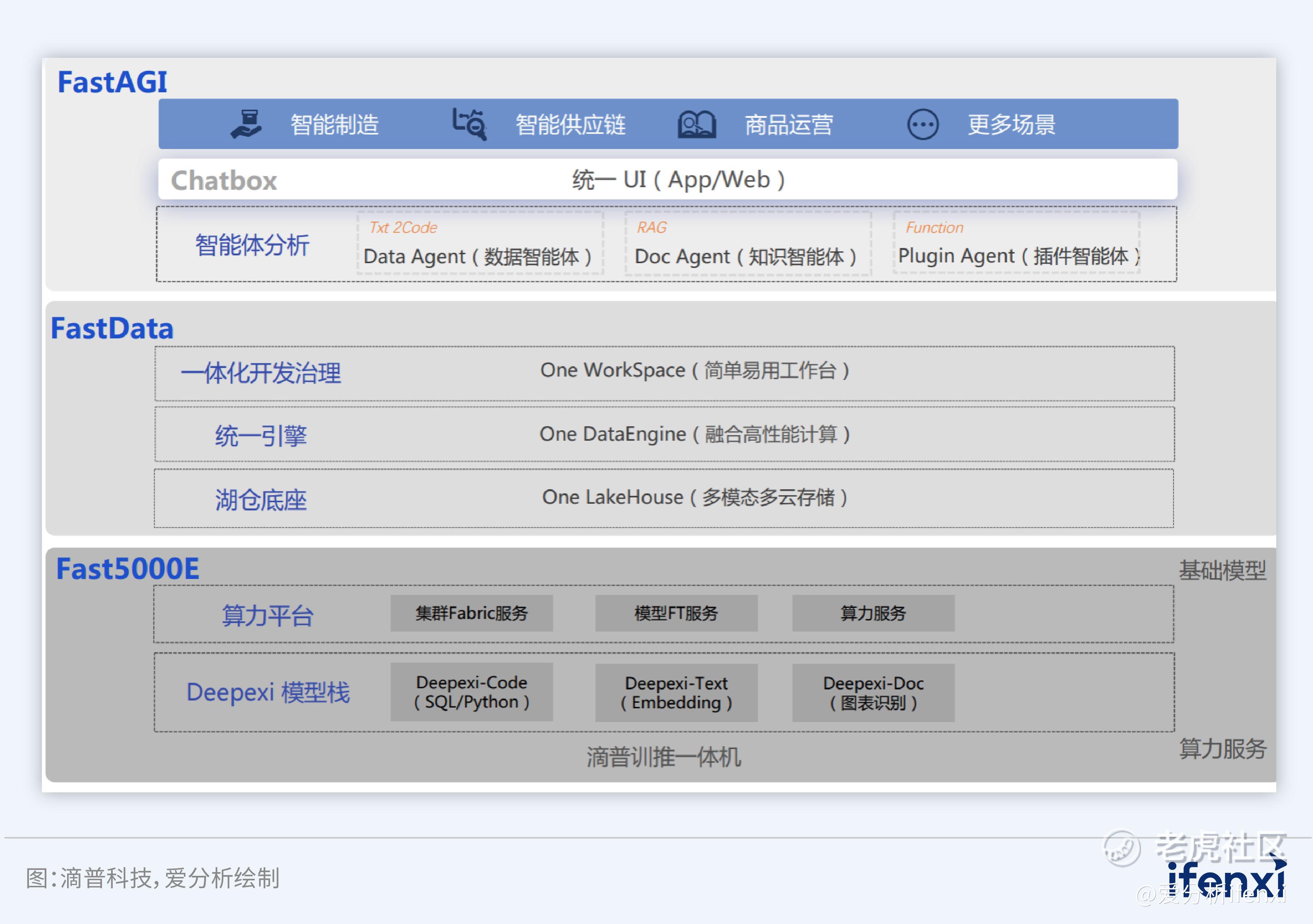
作为升腾应用软件伙伴和认证级一体机解决方案合作伙伴,滴普科技已与升腾完成技术互认证,并打造了训推一体机Fast5000E。Fast5000E基于Deepexi模型,能够助力企业搭建高性能算力平台,大大提升训练效率,降低用户使用门槛,应用于智能问答、文案生成、数据分析、API交互、信息提取、文档总结等多个典型场景。
滴普科技把大模型打造成“企业服务智能体”,联通各个系统实现整体赋能。目前,大模型应用一般是一个孤立的系统,只能为企业实现单点赋能,难以实现整体赋能。滴普科技以AI Agent为依托,提供Text-to-SQL、Text-to-Python、Text-to-API等能力,形成LLM大脑触角。大模型与企业内部业务系统无缝集成,可以调用知识库、数据库、业务系统等数据和知识,为企业各业务、各部门、跟层级实现整体赋能。以零售行业补货场景为例,过去常见的方式是基于经验老道的店长判断,现在企业只需把判断的逻辑,比如补货需要参考爆款销量、库存量等训练到企业大模型里,企业大模型可以自动生成补货建议和补货订单链接,让一个普通销售员轻松完成补货操作。
滴普科技已落地多个大模型项目,为企业带来可验证的业务价值。滴普科技已与中核集团中核装备院、某时尚集团、南京文投等多家行业头部企业展开合作,落地企业大模型项目。以某时尚集团为例,滴普科技已将大模型赋能该集团多个业务场景。在选品场景,大模型给货品运营专家提供供应链专业知识和数据,并且可以执行货品配补调等业务操作。在门店场景,大模型帮助门店店长获取自己权限内需要的数据和智能决策支持。在研发设计场景,大模型可以快速生成运动鞋、高跟鞋的线稿和配色,辅助设计师更快完成工作,并且具备部分重绘和局部修改等功能。滴普科技在“大模型元年”即可实现多个项目落地,除技术积累外,主要得益于领域专家团队的有力支撑。滴普科技已建立一个由多位领域专家组成的咨询团队,致力于大模型与业务场景快速结合,释放业务价值。
典型客户:
某时尚集团、中核集团中核装备院、南京文化投资控股集团有限责任公司
精彩评论