2026年6月,台北Computex展馆,黄仁勋与Marvell CEO同台,那句话只说了一遍,但全场都听清楚了:Marvell会成为下一家万亿美元市值企业。

英伟达同期宣布20亿美元战略入股,NVLink Fusion生态合作随之落地。消息落地的当天,Marvell股价单日暴涨32.5%,市值增加620亿美元,几乎相当于凭空又多出了一家巨头。
这个场景被财经媒体反复引用,解读角度无非两种:一是Marvell的芯片业务终于被算力浪潮抬上了新台阶,二是英伟达在垂直整合的路上再下一城。但这两种读法,都停在了事件的表面。
真正读懂这句话的人,目光早已越过Marvell本身,落在了它身后那场更大的战争:AI算力的下半场,已经从单卡性能的军备竞赛,全面转向万卡级集群的组网之战。谁掌握了集群互联的效率,谁就掌握了下一代AI基础设施的命脉。
而这场战争的关键棋子,意外地握在了三家中国公司手里。
卡脖子卡不到的地方,才是真正的战略高地
要理解这个局面,先要理解美国的封锁逻辑。
2022年以来,美国商务部工业与安全局持续收紧对华半导体出口管制,矛头直指H100、H200、A100等高端GPU。逻辑很清晰:卡住算力最密集的单点,AI大模型训练就无从推进。这套打法在短期内确实奏效,国内大型模型训练集群在引进高端GPU这条路上,遭遇了实质性阻碍。
但问题在于,这套打法的底层假设,是AI训练的关键约束在单卡算力,到了2024年前后,这个假设开始松动。
当模型参数规模突破万亿、训练集群扩展至数万卡,单卡的算力早已不是瓶颈。真正的制约,变成了集群里每一张卡之间的数据传输速度。一个由一万张GPU组成的训练集群,如果卡间通信延迟偏高、带宽不足,大量算力会消耗在等待数据上,实际利用率可能跌到30%以下。提升集群效率,比堆砌更多单卡更迫切,这已经是算力行业的基本共识。
这就是光模块的位置。
在超大规模数据中心里,每一张GPU与交换机之间的连接,每一条机架与机架之间的数据通路,都需要通过光模块完成电信号到光信号的转换与传输。一个万卡量级的集群,需要的光模块数量以十万计。800G、1.6T速率的高端光模块,是这套系统的基础单元,也是集群跑满算力的关键前提。
这里正是封锁的盲区所在,虽然高端光芯片核心原材料与精密封装设备仍处于出口管制范围内。但关键区别在于:光模块的封装组装环节,目前没有被纳入专项禁令。而这个环节,恰恰是整条产业链里技术门槛最高、交付难度最大,也是中国企业经过二十年深耕后形成全球领先优势的节点。
光模块的封装,听起来不算高精尖,但做好极难,一颗光芯片的尺寸在微米量级,耦合精度要求在纳米级别,封装过程中任何细微的偏差都会导致光路损耗剧增、良率崩塌。批量生产时,如何在高速产线上稳定维持耦合精度,如何把温漂、振动、老化对器件性能的影响控制在可接受范围,这些工艺难题的答案,不在论文里,在工厂里日复一日的迭代摸索中。
中国光通信产业的技术积累,起点是2000年代的基站建设与电信级光纤铺设。二十年间,从通信运营商的大规模采购,到海外数通市场的订单争夺,国内厂商的制造能力在激烈竞争压力下被反复锻造。当AI浪潮将数据中心光模块需求从百万级推向千万级,这套能力体系突然找到了历史级别的释放出口。
这就是战略高地的形成逻辑:不是正面突破封锁,而是在别人没有设防的地方,建起了别人追不上的壁垒。
全球超过一半的高端光模块,从三家中国公司发出
如果说GPU是算力集群的大脑,光模块就是它的神经系统,信号的传导、通路的通断,都在这里完成。
这套神经系统,有超过一半掌握在三家中国公司手里。
中际旭创,总部四川成都,全球数通光模块市场份额第一。谷歌、微软、亚马逊、Meta是其长期核心客户,800G光模块的量产时间线比主要竞争对手提前了近两个季度,率先实现1.6T光模块的批量交付。旭创不是靠价格战打下这个位置的,它的核心竞争力在于研发与制造的深度协同,从芯片封装到整模块测试的垂直整合能力让它在新产品导入周期上始终快人半步。
新易盛,同样落地四川,全球数通光模块市场份额第二,与旭创形成双寡头格局。它在LPO(线性直驱光模块)赛道上布局更早,已向Meta、亚马逊实现小规模商业供货,是当前LPO技术路线上量产进度最靠前的厂商之一。相比旭创的规模优势,新易盛的差异化在于技术路线的前瞻押注。
华工科技,母体是华中科技大学,总部湖北武汉,旗下华工正源整体光模块业务全球排名第六。它是三家里器件自主化程度最高的一个,在高速光芯片、光引擎等器件层面有独特积累,这让它在上游管制风险的对冲上有一定先发优势。
2026年5月LightCounting的榜单显示,这三家在800G及以上高端光模块的全球市占率合计约为62%。剩余份额主要由美国Coherent等海外厂商占据。在这个量级的市场里,超过一半的供给出自中国,是三年前难以想象的格局。
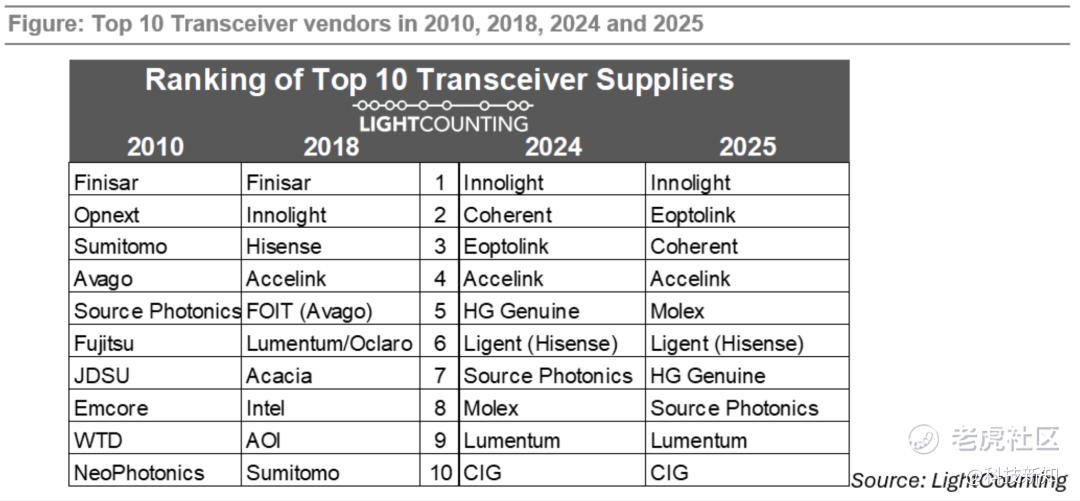
图源/2026年5月LightCounting的榜单
支撑这一市占率的,不仅是价格竞争力,更是一个在AI军备竞赛语境下格外稀缺的能力:交付确定性。
在超大规模数据中心的建设逻辑里,光模块的供货节奏直接制约整个集群的上线时间表。一家云厂商如果宣布下一季度部署十万卡GPU集群,配套光模块必须在GPU到位前完成安装测试。任何供货延迟,都意味着昂贵GPU资产的闲置,都意味着大模型训练或推理服务的上线推迟,这个代价,云厂商算得非常清楚。
在这个需求背景下,光模块厂商最重要的能力,不只是能做出满足规格的产品,而是能在特定时间窗口内,以稳定良率大批量交付经过严格测试的成品。中际旭创在2023年800G爬坡周期中完成的那次大规模交付,新易盛在1.6T送样阶段的快速响应,业内早有口碑。
云厂商采购决策背后,有一套极其理性的供应商筛选逻辑:谁能在关键节点交货,谁才能进入核心供应商名单,继而锁定框架协议、扩大配额。这套采购惯性一旦建立,不是靠一两家新入局者轻易打破的。
这是中国光通信企业真正的护城河:不在某一代产品的技术指标,而在于在全球最挑剔的客户面前,一次次兑现了最难兑现的承诺。
封装制造赢了,但光模块的心脏还在别人手里
清醒 的人都知道,这场胜利还不完整。
800G和1.6T光模块的核心是高速DSP芯片,负责信号均衡、纠错、调制等关键功能,这颗被称为光模块“心脏”的器件,目前高度依赖Marvell和博通的供货。Marvell的Nova、Ara系列DSP产品与博通的配套方案,是当前主流高端数通光模块的标准配置。国内厂商买入这些芯片,完成封装,交付给全球云厂商,这是当前产业链的真实结构。
国产高端DSP的现状,需要分层来看,在中低端DSP市场,国产化率已达约40%;飞思灵在400G/800G相干DSP领域已实现规模商用,1.6T DSP预计2026年三季度量产;中兴微电子等第二梯队厂商也在持续推进。但本文讨论的核心场景数通高端800G/1.6T DSP,国产化率仍不足5%,这个细分市场才是真正的短板所在。**海思也有相关研发积累,但DSP芯片主要服务于**自用的光通信设备,无法大规模对外供货。
这个短板的风险,在当前阶段还没有显性化,Marvell目前向中国光模块厂商的供货未受实质管制约束。但这不等于风险不存在,它只是被暂时搁置了。一旦管制范围从GPU芯片向光通信DSP延伸,国内光模块厂商将在最关键的环节陷入被动。
面对这个隐患,国内厂商最受外界关注的应对路线是LPO:线性直驱光模块。
LPO的核心思路是把光模块内置的DSP去掉,将信号处理功能转移到服务器端的ASIC芯片承担。从架构上看,这绕开了对光模块内置DSP的采购依赖,也降低了光模块的功耗和成本。新易盛的LPO产品已向Meta和亚马逊实现小规模商业供货,部分云厂商正在试点部署,这是一个真实的进展信号。
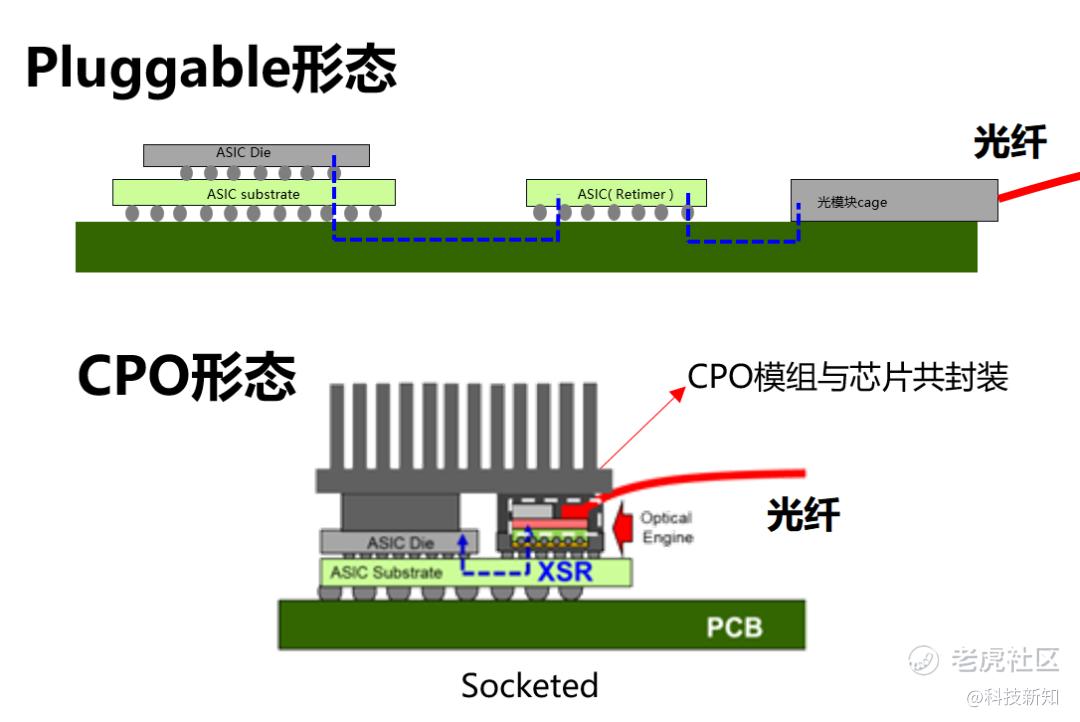
但LPO并不是全产业链突围的答案,这一点需要诚实面对,LPO的主流商用传输距离适用于500米以内,极限商用场景可达2公里;超过2公里的长距互联场景,信号衰减问题将超出系统可接受范围,仍然必须搭载DSP。跨机房、跨园区的中长距互联,LPO无法替代。LPO的基础标准目前已基本落地,封装层面具备通用性;当前的兼容性差异主要体现在驱动适配和细节参数层面,并非根本性的标准割裂。但这些约束共同意味着:未来三至五年内,传统带DSP光模块仍是市场主流。
真正的产业链自主,还需要在上游走完更难走的那段路:高端光芯片的国产化、DSP芯片的规模量产、特种封装设备的自主研发,这不是三年能完成的事,但方向是确定的,进展是真实的。
回望过去二十年,中国在光通信封装、无源器件、基站制造领域的积累,在大多数人眼里是低附加值的制造业,代工、配套、集成这些标签背后,是无数工程师在公差控制、热管理、老化测试上耗费的时间,是在一份份苛刻的海外客户验收报告里被磨砺出来的工程纪律。
当AI将全球算力需求推向前所未有的高度,这套被长期低估的能力体系,在最意想不到的地方找到了历史级别的出口。
黄仁勋看多Marvell,是因为他看到了算力互联的下一个价值洼地。而真正读懂这场战争的人,或许早已把目光投向了Marvell的下游, 那三家在四川、湖北,日夜不停点亮全球数据中心的中国企业。
精彩评论