
今年以来,“如何 Tokenmaxxing” 成为了大洋两岸都在讨论的问题。
然而,在真实企业场景中,大家都在用的主流开源大模型推理框架 vLLM 一直隐藏着一个“吞 Token 大坑”:
系统看起来正常运行,请求也正常返回,但模型的回答质量却在高并发、多卡并行等复杂环境下悄悄下降。
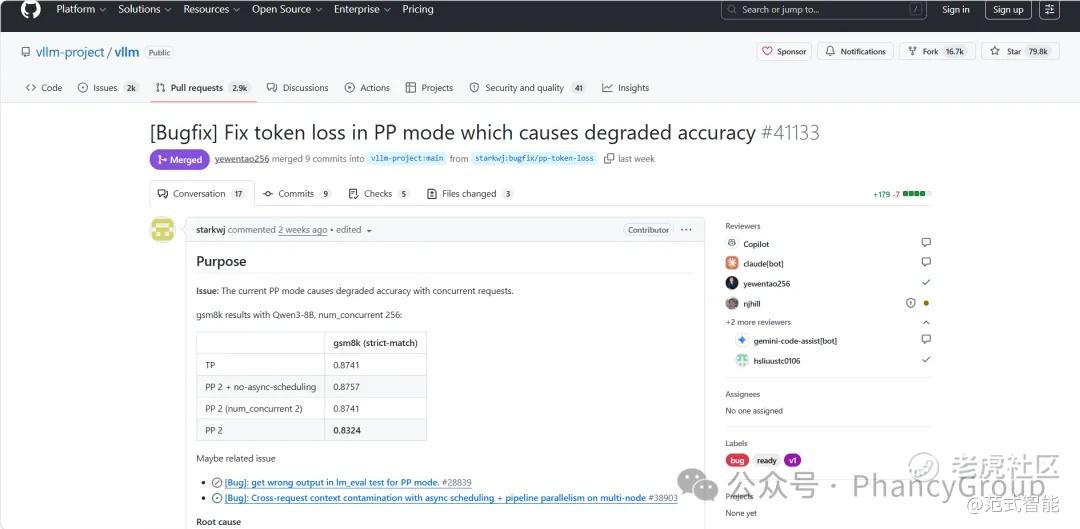
近日,范式 $06682(06682)$ 工程师向开源大模型推理框架 vLLM 提交的一项关键 Bugfix 已被官方社区合并。该修复解决了 vLLM 在 Pipeline Parallelism(流水线并行)模式下,高并发请求可能导致 prompt token 丢失,并进一步引发模型推理准确率下降的问题。
01 多卡流水线并行,会“吞掉”用户的 Token
可以把大模型想象成一条很长的生产线。模型太大,一张 GPU 放不下或算不过来,就把它按层拆成几段:前面几层放在 GPU 1,中间几层放在 GPU 2,后面几层放在 GPU 3。请求进来后,数据会像产品上流水线一样,依次经过每一段 GPU,最后产出结果。在有多个请求或 micro-batch 时,不同 GPU 可以同时处理不同阶段,从而提高整体吞吐。
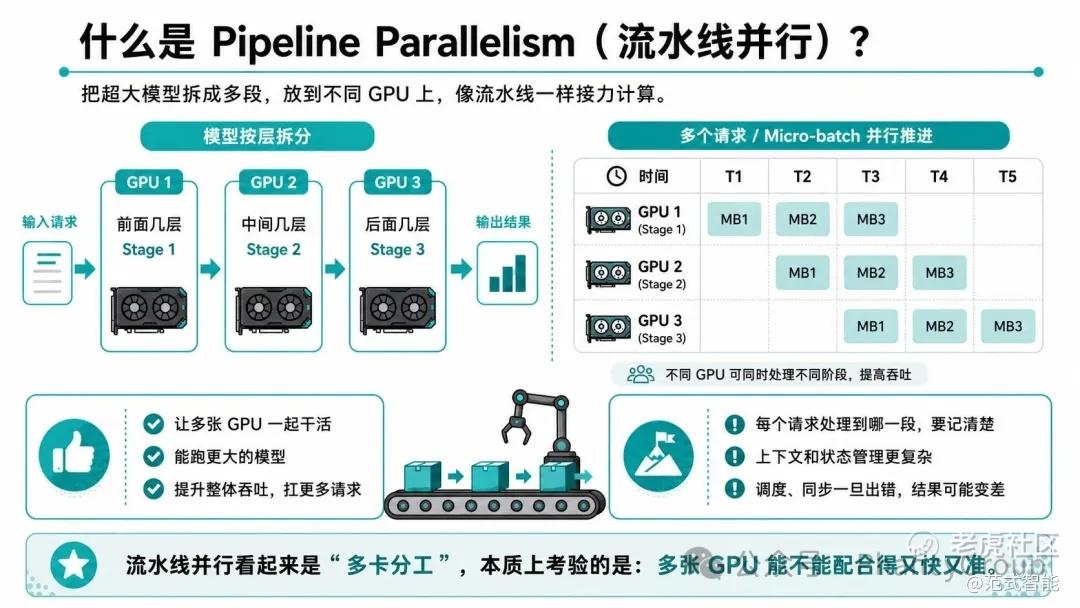
它的好处是:让多张 GPU 一起干活,跑更大的模型、扛更多请求。
但难点也在这里:请求多了以后,每一站都要记清楚“这个请求处理到哪了、上下文有哪些”。一旦记录错了,模型就可能漏看一部分题目背景,答案自然会变差。所以,流水线并行看起来是“多卡分工”,本质上考验的是:多张 GPU 能不能配合得又快又准。
但当系统同时处理大量请求时,问题就出现了。vLLM 在流水线并行模式下,需要一边拆分任务、一边分批处理输入内容,还要不断调整请求顺序。原有逻辑在少数复杂场景下,可能把某个请求的上下文记录错了。
结果就是,模型并没有完整看到用户输入的全部内容。对用户来说,服务没有报错,接口也正常返回;但对模型来说,它可能已经漏掉了一部分题目背景,就像考试时少看了半道题,最终回答自然会变差。
这类问题,在企业级大模型服务中尤其关键。
因为真正的生产系统,不只是要在实验室环境里跑通,更要在大量用户同时访问、多卡并行调度、长上下文输入和复杂请求混合的情况下,依然保持稳定、准确、可验证。一次静默的上下文丢失,就可能让模型在金融风控、企业知识问答、代码生成、数据分析等严肃场景中输出错误结果。
02 范式贡献 vLLM 关键 Bugfix
根据测试结果,在 Qwen3-8B 模型、GSM8K 任务、256 并发请求场景下,PP模式修复前 strict-match 指标为 0.8324;修复后提升至 0.8772,基本恢复至正常水平。同时,该修复未观察到明显性能影响。
此次修复的核心,是让 vLLM 在非最后一个流水线并行节点更新 token 缓存时,基于请求当前真实 token 长度进行状态维护,避免在 batch 重排过程中发生 prompt token 被覆盖或丢失的问题。
换句话说,范式这次修复的不是一个普通代码瑕疵,而是大模型推理系统在规模化部署中非常关键的一类底层可靠性问题:高并发下,模型不仅要跑得快,更要跑得准。
范式长期关注大模型落地过程中的基础设施问题。从异构算力纳管、GPU 虚拟化、模型服务,到高并发推理、智能路由与企业级部署,范式持续围绕AI规模化应用所需的底层能力进行技术投入。
此次向 vLLM 社区贡献关键修复,也体现出范式在大模型推理基础设施领域的工程深度:不仅在自有产品体系中建设 AI 基础设施能力,也积极参与全球开源生态,用真实场景中的工程经验反哺基础软件社区。
链接:
https://github.com/vllm-project/vllm/pull/41133
精彩评论