当 TTS(文本转语音)、语音转换、音色克隆软件使用门槛越来越低、越来越逼真,“听起来像本人”正在变成难以防范的安全陷阱:电信诈骗用合成声音诱导转账,身份冒用借声纹闯关,虚假新闻用“音频证据”制造舆情,金融场景里一句“确认”就可能引发连锁风险……要守住这条信任边界,关键不仅在于人耳能不能分辨,更在于系统是否具备实时、可靠的语音鉴伪能力。
为此,范式 $06682(06682)$ 推出【合成音频鉴定模型】,面向真实业务场景强化鲁棒性与泛化性。该模型直接接收原始语音波形输入:先通过卷积特征编码提取稳定声学表示,再由 Transformer 进行全局时序上下文建模,随后对时间维特征池化汇聚,最后由轻量级分类头输出“真/伪”分类结果。整套结构清晰、链路简洁,减少复杂人工特征设计,更利于工程化部署与快速接入现有语音系统。
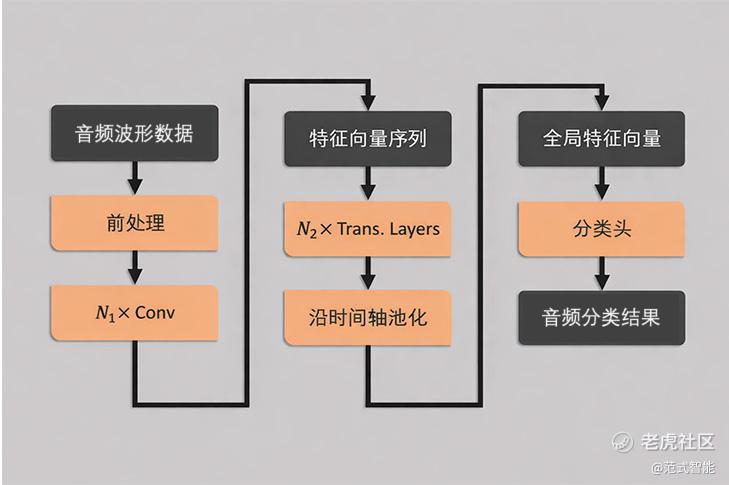
在工程实现上,该模型坚持“快、轻、可落地”:支持单声道 wav/mp3/flac 等主流格式,采样率覆盖 8k–48kHz,音频时长大于 0.5 秒即可鉴定;平均推理响应时间低于 300ms,适合作为电话风控、语音助手、声纹识别等链路的前置安全关卡,在不显著增加系统时延的前提下把风险拦在入口。
为了对抗“生成器快速迭代”的现实威胁,模型训练不仅使用大规模开源 Deepfake Audio 数据集,也引入基于最新 AI 语音合成技术生成的合成人声数据,力图覆盖不同合成方式与攻击形态,降低对特定工具的依赖;同时面向真实链路的分布偏移进行针对性强化,使模型在噪声、压缩与设备差异等条件下依然保持稳定判断。
同时,我们面向真实业务威胁构建了高多样性、高覆盖性的合成语音对抗评测体系,覆盖多类录音攻击场景,并引入多种主流语音合成与语音转换工具生成样本进行持续对抗验证。结果显示,该模型在复杂链路与多变攻击条件下依然能够保持稳定、可靠的鉴伪能力,兼顾“少误报”的业务体验与“高检出”的安全底线。更重要的是,它让“声音可信”重新具备可工程化的验证手段:在反诈风控、语音与声纹系统防护、法律取证、远程会议等关键场景中,为数字身份与内容安全提供一层可落地、可规模化的基础设施级能力。
精彩评论