我们认为,从大模型的演化路径来看,模型体量还将进一步扩张,从而带来算力需求持续增长。长远来看,成熟大模型的运营有望带来3169亿美元的服务器增量市场,较2023年全球211亿美元的AI服务器市场而言,仍有较大成长空间。基于此,我们认为大模型持续迭代有望带来大量算力基础设施需求,建议关注算力产业投资机遇。
核心观点
全球AI算力需求继续向上
随着大模型持续迭代,模型能力不断增强,其背后是“Scaling Law”下模型参数量和数据集不断增长的结果。我们认为,从大模型的演化路径来看,模型体量还将进一步扩张,从而带来算力需求持续增长。具体来看,大模型对算力的需求体现在预训练、推理、调优三个环节。根据我们的测算,以1000亿参数模型为例,三个环节的算力总需求约18万PFlop/s-day,对应需要2.8万张A100等效GPU算力。长远来看,成熟大模型的运营有望带来3169亿美元的服务器增量市场,较2023年全球211亿美元的AI服务器市场而言,仍有较大成长空间。基于此,我们认为大模型持续迭代有望带来大量算力基础设施需求,建议关注算力产业投资机遇。
模型体量越来越大,带动算力建设需求
大语言模型(LLM)是在大量数据集上预训练的模型,其在处理各种NLP任务方面显示出了较大潜力。Transformer架构的出现开启了大模型的演化之路,随着解码模块堆叠数量的不断增长,模型参数量持续增加,逐渐演化出GPT-1、GPT-2、GPT-3、PaLM、Gemini等不同版本模型,参数量也从十亿、百亿,向千亿、万亿增长。我们看到,每一代模型的演化都带来能力的增强,背后一个很重要的原因在于参数量和数据集的增长,带来模型感知能力、推理能力、记忆能力的不断提升。基于模型的缩放定律,我们认为未来模型迭代或仍将延续更大参数量的路径,演化出更加智能的多模态能力。
大模型的算力需求体现在:预训练、推理、调优
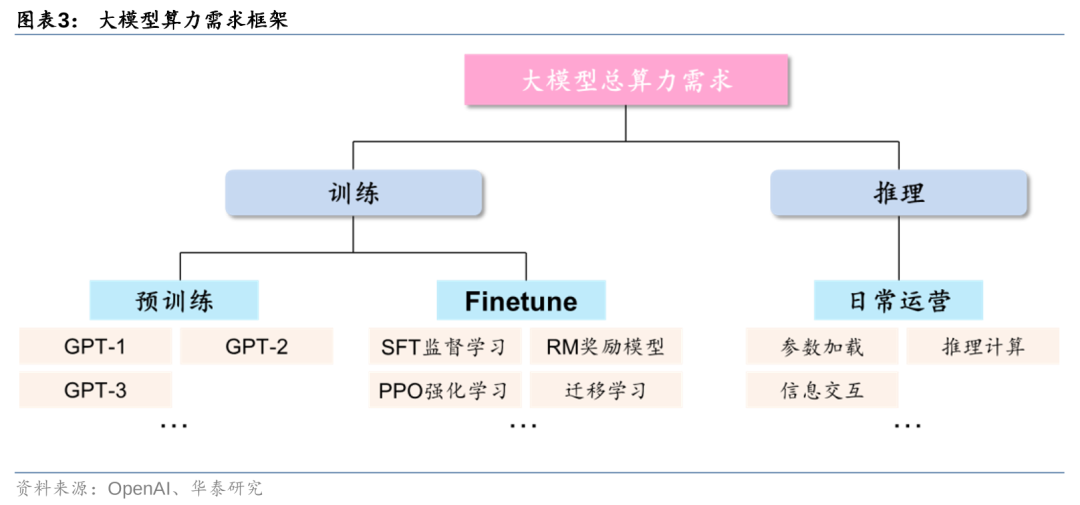
拆解来看,大模型的算力需求场景主要包括预训练、Finetune及日常运营。对于三部分的算力需求,我们的测算思路如下:1)预训练:基于“Chinchilla 缩放定律”假设,计算量可以通过公式C≈6NBS来刻画;2)推理:以ChatGPT流量为基准,计算量可以通过公式C≈2NBS来刻画;3)调优:通过调优所需的GPU核时数倒推。以1000亿参数模型的预训练/推理/调优为例,三个环节所需的算力需求分别为13889、5555.6、216 PFlop/s-day。我们认为,在缩放定律(Scaling Law)加持下,随着模型体量增长,算力需求有望持续释放。
基础设施需求有望持续释放,关注算力产业投资机遇
结合对大模型预训练/推理/调优的算力需求测算,我们预计从开发到成熟运营一个千亿模型,对A100等效GPU的需求量为2.8万张。根据我们的测算,成熟大模型的运营有望带来3169亿美元的全球AI服务器增量市场。对比来看,据IDC,2023年全球AI服务器市场规模211亿美元,预计2024-2025年CAGR将达22.7%,未来仍有较大成长空间。此外,考虑到国内对高性能芯片获取受限,AI GPU国产化也有望进一步提速。
风险提示:宏观经济波动、下游需求不及预期、测算结果可能存在偏差。
正文
“Scaling Law”驱动大模型算力需求持续增长
Transformer的出现开启了大模型演化之路。大语言模型(LLM)是在大量数据集上预训练的模型,且没有针对特定任务调整数据,其在处理各种NLP(自然语言处理)任务方面显示出了较大潜力,如自然语言理解(NLU)、自然语言生成任务等。从LLM近年的发展情况来看,其路线主要分为三种:1)编码器路线;2)编解码器路线;3)解码器路线。从发展特点来看:1)解码器路线占据主导,归因于2020年GPT-3模型表现出的优异性能;2)GPT系列模型保持领先,或归因于OpenAI对其解码器技术道路的坚持;3)模型闭源逐渐成为头部玩家的发展趋势,这一趋势同样起源于GPT-3模型,而Google等公司也开始跟进;4)编解码器路线仍然在持续发展,但是在模型数量上少于解码器路线,或归因于其复杂的结构,导致其在工程实现上没有明显的优势。
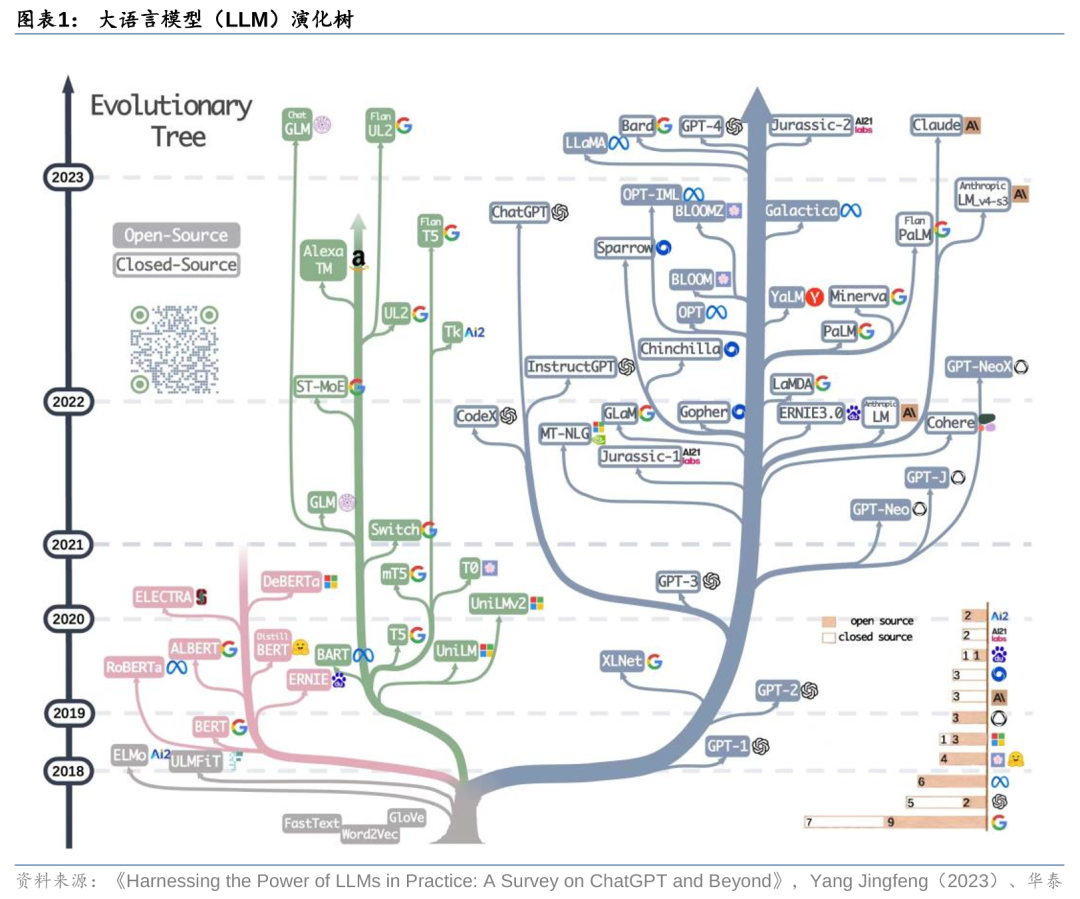
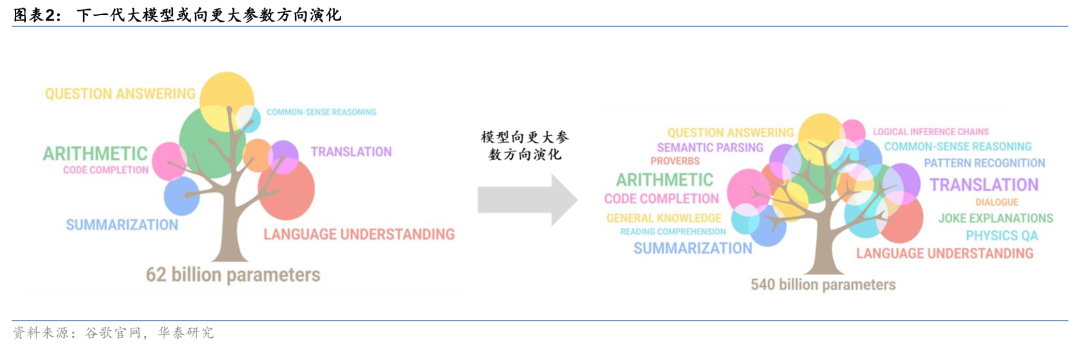
大模型或将向更大参数的方向不断演化。我们看到从GPT-1到GPT-4模型、从PaLM到Gemini模型,每一代模型的能力在不断强化,在各项测试中取得的成绩也越来越好。而模型背后的能力来源,我们认为参数和数据集是最重要的两个变量。从十亿规模,到百亿、千亿、万亿,模型参数量的增加类似人类神经突触数量的增加,带来模型感知能力、推理能力、记忆能力的不断提升。而数据集的增加,则类似人类学习知识的过程,不断强化模型对现实世界的理解能力。因此,我们认为下一代模型或仍将延续更大体量参数的路线,演化出更加智能的多模态能力。
拆解来看,大模型的算力需求场景主要包括预训练、Finetune及日常运营。从ChatGPT实际应用情况来看,从训练+推理的框架出发,我们可以将大模型的算力需求按场景进一步拆分为预训练、Finetune及日常运营三个部分:1)预训练:主要通过大量无标注的纯文本数据,训练模型基础语言能力,得到类似GPT-1/2/3这样的基础大模型;2)Finetune:在完成预训练的大模型基础上,进行监督学习、强化学习、迁移学习等二次或多次训练,实现对模型参数量的优化调整;3)日常运营:基于用户输入信息,加载模型参数进行推理计算,并实现最终结果的反馈输出。
预训练:缩放定律下算力需求有望持续增长
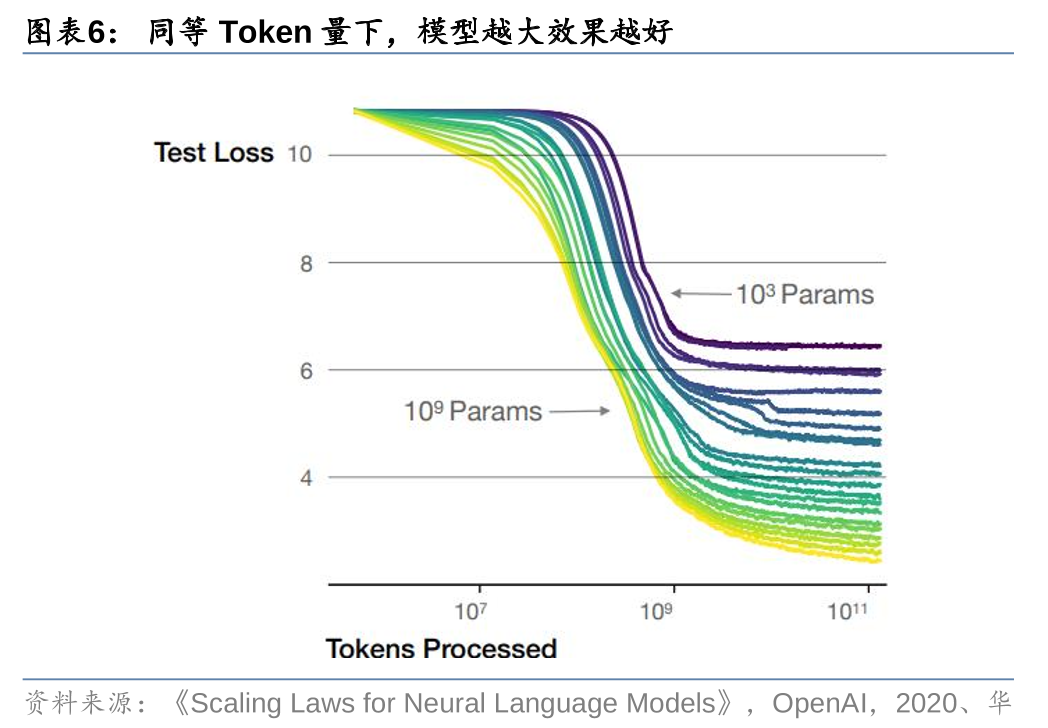
大模型预训练效果主要由参数量、Token数量、计算量决定,且满足“缩放定律”。根据OpenAI在2020年发表的论文《Scaling Laws for Neural Language Models》,在大语言模型训练的过程中,参数量、Token数量、计算量对大模型的性能表现有着显著影响。为了获得最佳性能,这三个因素必须同时放大。当不受其他两个因素的制约时,模型性能与每个单独因素呈幂律关系,即满足“缩放定律”。
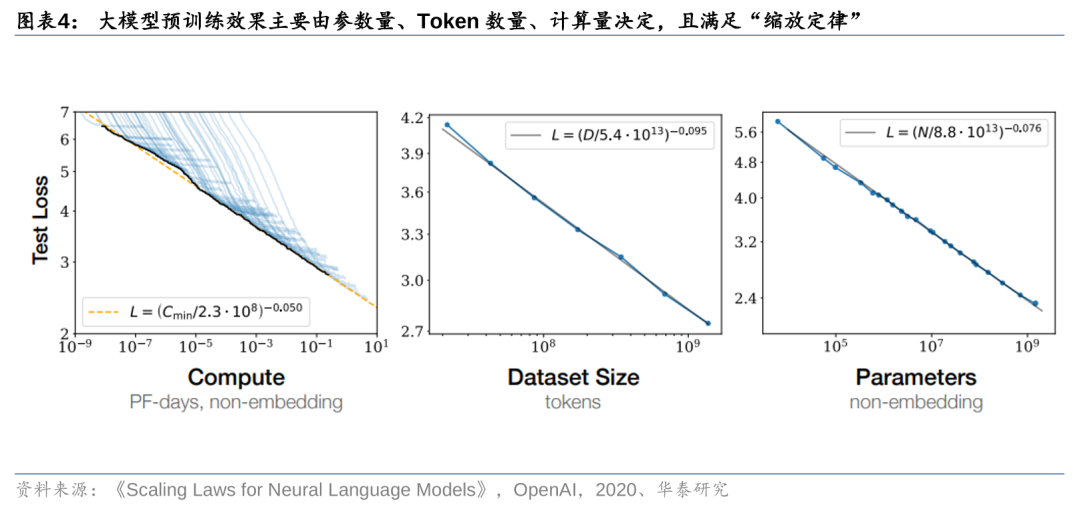
OpenAI认为模型预训练的计算量可以通过公式C≈6NBS来刻画。根据OpenAI在2020年发表的论文《Scaling Laws for Neural Language Models》,预训练一个Transformer架构模型所需要的算力(C)主要体现在前向反馈()和后向反馈()过程,并主要由三个变量决定:模型参数量(N)、每步训练消耗的Token批量(B)、预训练需要的迭代次数(S)。其中,B、S的乘积即为预训练所消耗的Token总数量。基于此,我们可以通过C≈6NBS来刻画大模型预训练所需要的算力大小。

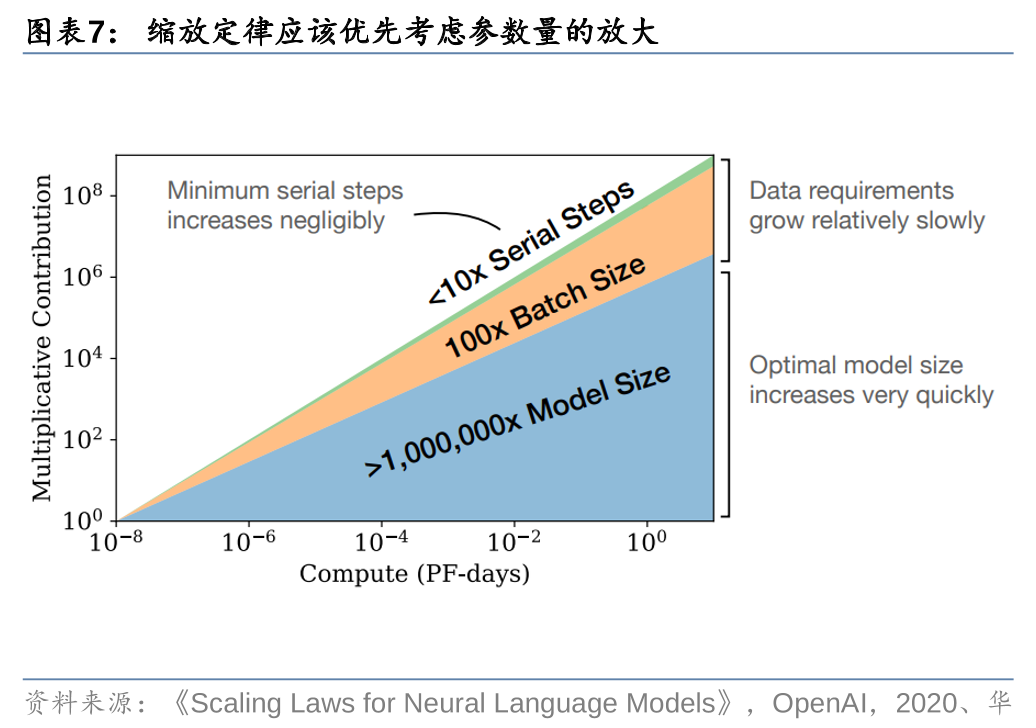
其中,OpenAI认为模型参数量是最重要变量,参数越大模型效果越好。OpenAI认为,随着更多的计算变得可用,模型开发者可以选择分配多少用于训练更大的模型,使用更大的批处理,以及训练更多的步骤。假设计算量增长十亿倍,那么为了获得最优的计算效率训练,增加的大部分应该用于增加模型大小。为了避免重用,只需要相对较小的数据增量。在增加的数据中,大多数可以通过更大的批处理大小来增加并行性,而所需的串行训练时间只增加很少一部分。
谷歌提出“Chinchilla 缩放定律”,认为模型参数与训练数据集需要等比例放大以实现最佳效果。据谷歌DeepMind在2022年发表的《Training Compute-Optimal Large Language Models》,模型预训练需要的Token数量和参数量的放大与模型性能之间的关系并不是线性的,而是在模型参数量与训练消耗Token数量达到特定比例的时刻,才能实现最佳的模型效果。为了验证这一规律,谷歌用1.4万亿个Tokens训练了一个700亿个参数的模型(“Chinchilla”),结果发现其效果比用3000亿个token训练的2800亿参数模型Gopher更好。而DeepMind进一步的研究发现,计算最优语言模型的参数量和数据集大小的近似关系满足:D=20P,其中D表示Token数量,P表示模型参数量,即在此比例下满足“Chinchilla 缩放定律”。
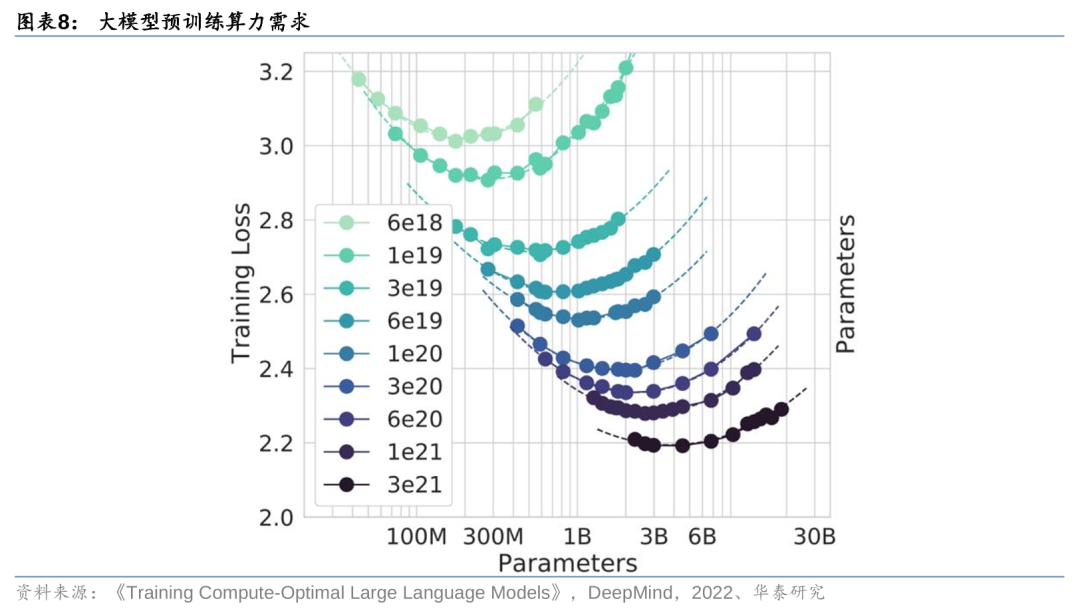
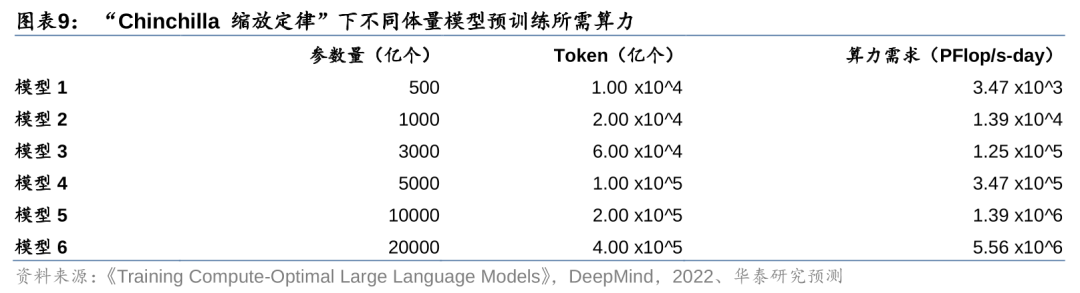
我们预计训练千亿参数模型所需算力在1万PFlop/s-day以上。我们假设不同参数体量的模型均满足“Chinchilla缩放定律”,由此测算不同模型所需的最优数据集大小及预训练所需的算力。以训练1000亿参数的大语言模型为例,“Chinchilla缩放定律”下所需的训练Token数量为2万亿个。根据OpenAI所提出的计算量公式C=6NBS,可以计算得到,训练1000亿参数模型所需的算力约1.39x10^4 PFlop/s-day。同理,训练5000亿参数模型所需算力约3.47x10^5 PFlop/s-day,训练1万亿参数模型所需算力约1.39x10^6 PFlop/s-day。
推理:高并发是推理计算需求的主要驱动力
GPT模型底层架构由解码器模块构成。在GPT这类大语言模型中,解码模块相当于基本架构单元,通过彼此堆叠的方式,拼凑成最终我们看到的GPT模型底层架构。解码模块的数量决定了模型的规模,GPT-1一般有12个模块,GPT-2有48个,GPT-3则有96个模块。模块数量越多,则意味着模型参数量越大,模型体积也越大。

解码模块通过计算Token化的文本数据,实现大模型推理。据OpenAI在2020年发表的论文《Scaling Laws for Neural Language Models》,大模型在完成训练之后,模型本身已经固定,参数配置完成之后即可进行推理应用。而推理过程实质上就是对大模型参数的再次遍历,通过输入文本编码后的向量,经过注意力机制的计算,输出结果并转化为文字。这一过程中,模型的参数量取决于模型层数、前馈层的层数、注意力机制层的头数(head)等。
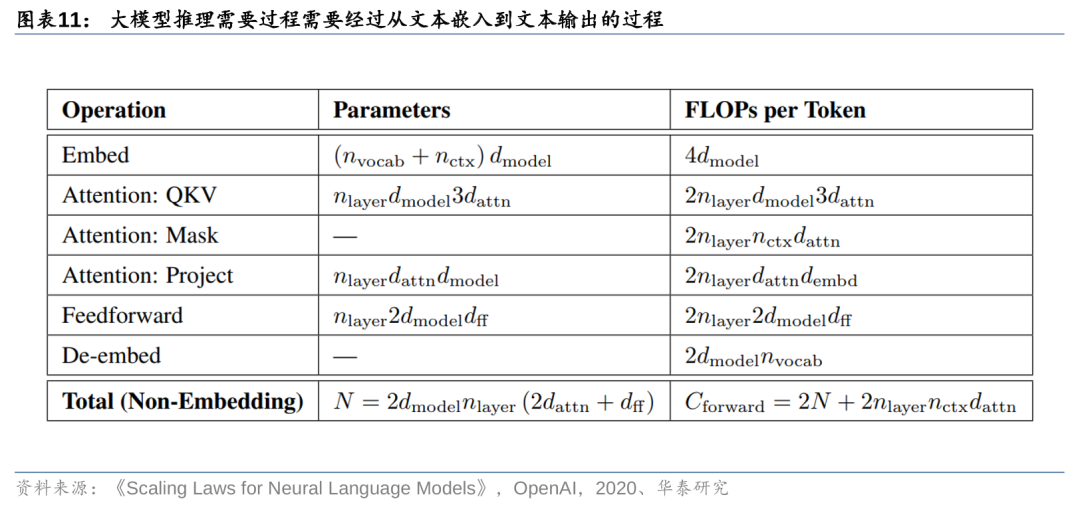
推理过程所需要的算力可以由公式C≈2NBS来刻画。由于解码模块在进行推理的过程中,主要执行前向传播,主要计算量体现在文本编码、注意力机制计算、文本解码等环节。根据OpenAI给出的计算公式,每输入一个Token,并经历这样一次计算过程,所需要的计算量=2N+2,其中公式后半部分主要反映上下文窗口大小,由于这部分在总计算量中的占比较小,所需字节常以K级别表示,因此在计算中往往予以忽略。最终,我们得到大模型推理的计算需求为单次计算量与Token数量的乘积,即C≈2NBS。

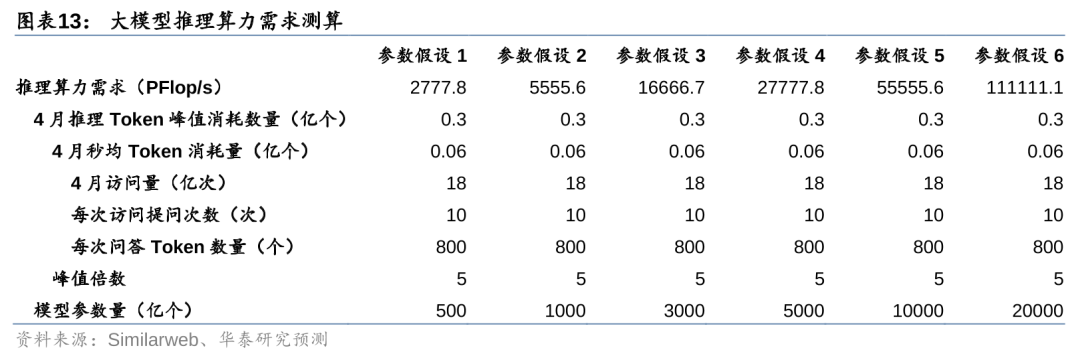
在ChatGPT同等访问量下,我们预计千亿模型推理所需算力需求在5000 PFlop/s以上。据Similarweb数据,2024年3月ChatGPT官网访问量为18亿次。我们假设每次用户访问会进行10次问答,每次问答消耗的Token数量为800个,则计算得4月ChatGPT官网每秒消耗的Token数量为0.06亿个。考虑到算力基础设施建设是按照峰值需求而不是平均需求来确定,因此我们进一步假设峰值Token需求为均值的5倍。最后,假设不同参数模型拥有ChatGPT同等访问量,根据C≈2NBS公式,计算得1000、5000、10000亿参数模型的每秒推理算力需求分别为5555.6、27777.8、55555.6 PFlop/s。
调优:算力需求主要取决于调优次数
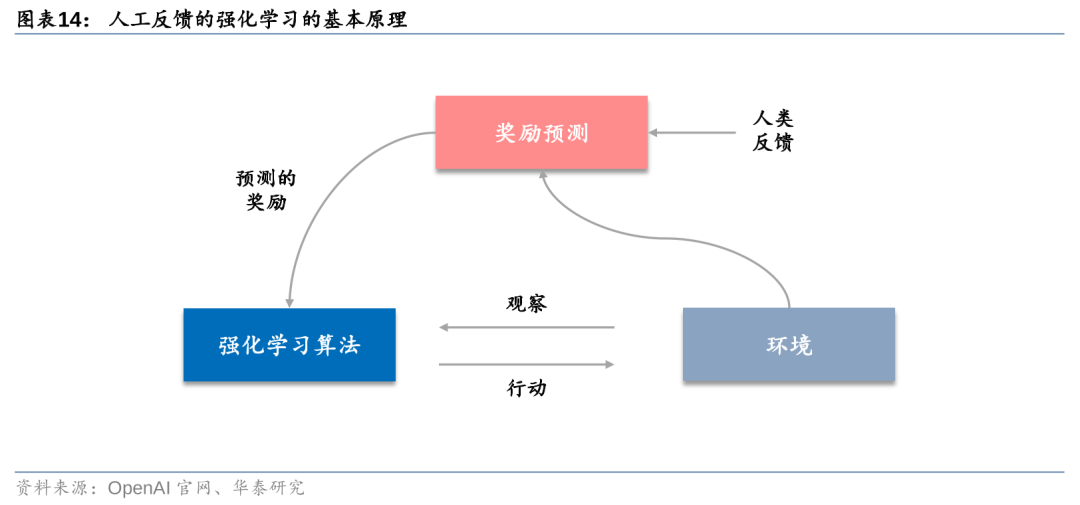
大模型完成预训练之后还需要进行参数调优以符合人类需求。一般而言,大语言模型在完成预训练之后,还需要经过持续的调优(Finetune)才能实现较好的运行效果。以OpenAI为例,模型调优的过程采用人类反馈机制(RLHF)进行。强化学习通过奖励(Reward)机制来指导模型训练,奖励机制可以视为传统模训练机制的损失函数。奖励的计算要比损失函数更灵活和多样(例如AlphaGO的奖励是对局的胜负),代价是奖励计算不可导,不能直接拿来做反向传播。强化学习的思路是通过对奖励的大量采样来拟合损失函数,从而实现模型的训练。类似的,人类反馈也不可导,也可以作为强化学习的奖励,从而产生基于人工反馈的强化学习。
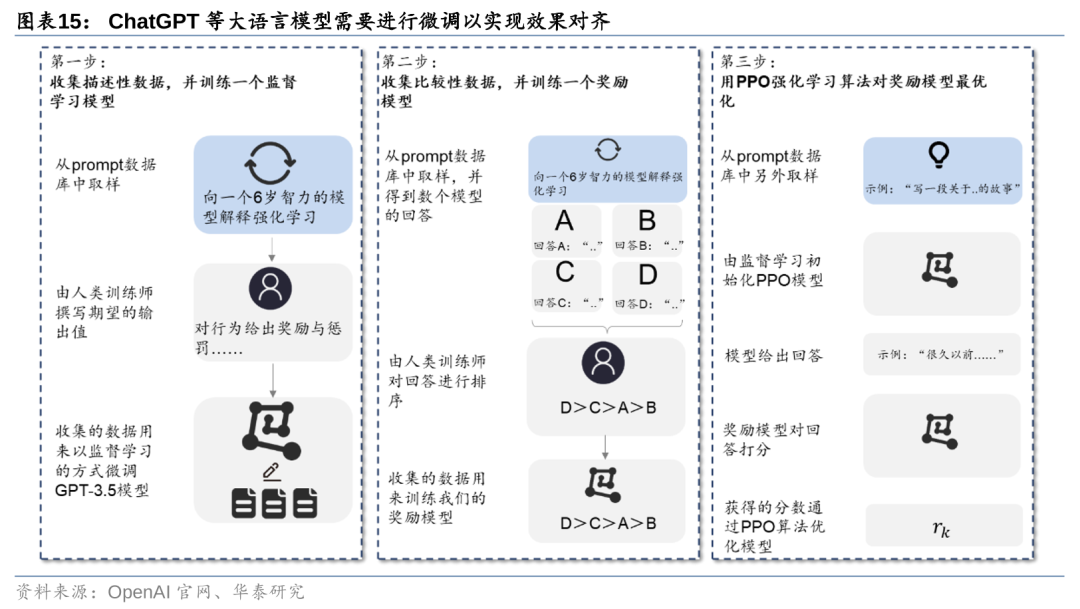
以ChatGPT为例,调优过程主要经过三大步骤。基于人类反馈的强化学习技术,以ChatGPT的调优过程主要分三步进行:1)训练监督模型;2)训练奖励模型;3)进行PPO参数强化学习。调优之后,模型的参数会得到更新,所生成的答案也会更加接近人类所期望的结果。因此,调优过程对算力的需求实际上与预训练类似,都需要对模型参数进行遍历,但所使用的数据集较预训练会小得多。
大模型调优的算力需求可以通过调优所需的GPU核时数倒推。对于大模型调优所需的算力需求,我们采用实际消耗GPU核时数的方式进行反推。据Deepspeed Chat(微软旗下专注于模型调优的服务商),进行一次130亿模型的调优,需要使用8张A800加速卡,耗费9小时完成。据英伟达官网,A800加速卡峰值算力约312 TFLOPS(TF32,采用稀疏技术)。据此计算得,进行一次130亿参数模型的调优,需要耗费算力约0.9 PFlop/s-day。以此类推,对300亿、660亿、1750亿参数模型进行一次调优所需的算力分别为1.9、5.2、8.3 PFlop/s-day。
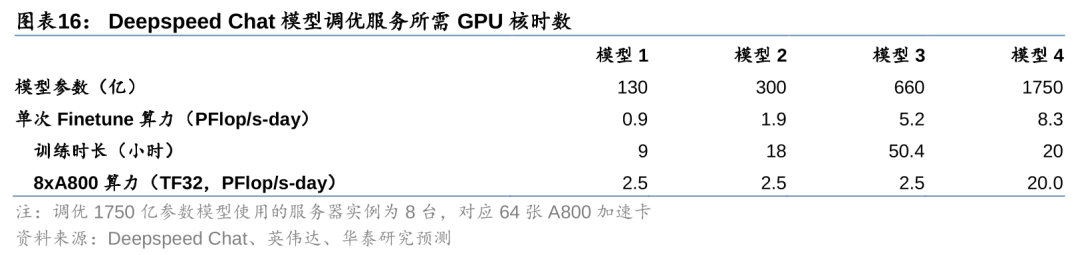
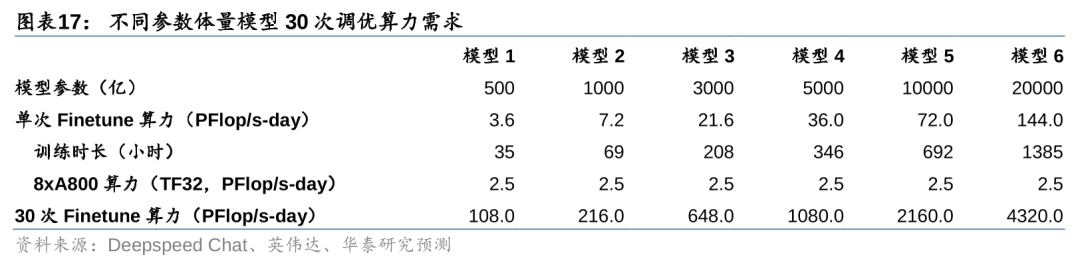
我们预计每月调优万亿参数模型所需算力在2000 PFlop/s-day以上。为了便于比较,我们进一步假设,不同参数体量的模型均采用单个A800服务器实例(即8张A800加速卡)进行调优训练,且训练时长与模型参数量成正比。此外,考虑到调优次数问题,我们假设每个月大模型厂商需要对模型进行30次调优。基于此,我们测算得1000亿参数模型每月调优所需算力为216 PFlop/s-day,1万亿参数模型每月调优所需算力为2160 PFlop/s-day。
算力基础设施需求有望持续释放,关注算力产业机遇
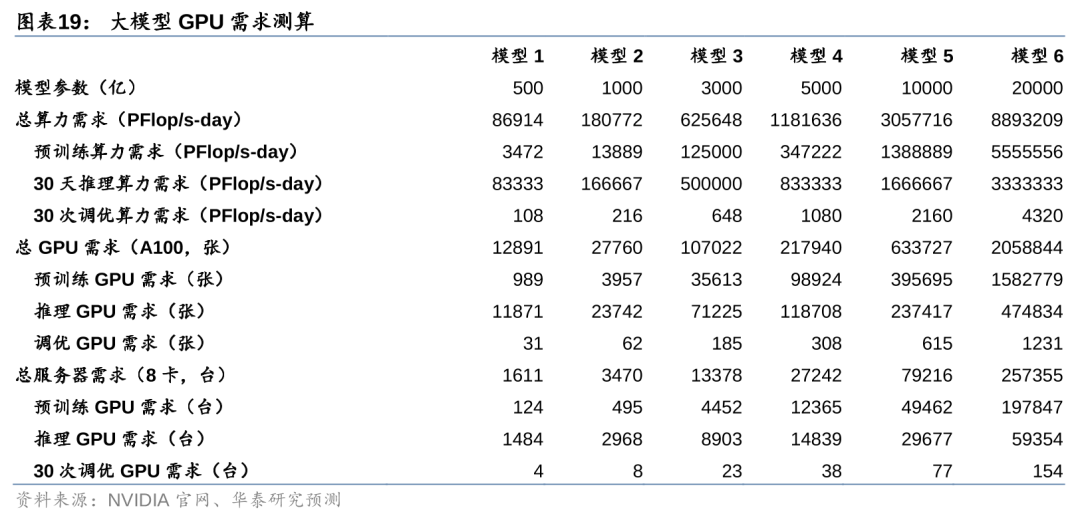
大模型训练/推理/调优带来算力硬件需求。对于大模型的计算需求,目前主流的做法是采用AI服务器进行承载,核心器件是AI GPU,如英伟达A100、H100、B100等。据英伟达,单张A100加速卡TF32峰值算力为312 TFLOPS(采用稀疏技术)、FP16峰值算力为624 TFLOPS(采用稀疏技术)。考虑到实际工作负载中,往往采用多卡互联进行模型的训练和推理,需要考虑有效算力问题。据Sid Black等人2022年发布的《GPT-NeoX-20B: An Open-Source Autoregressive Language Model》,多张A100互联下,单卡有效算力约117 TFLOPS(TF32,采用稀疏技术),即有效算力比例为37.5%。我们假设,推理过程的有效算力比例与训练过程相当,则单卡的推理算力为234 TFLOPS(FP16,采用稀疏技术)。

我们预计千亿模型训练/推理/调优的A100等效GPU需求量为2.8万张。对于大模型所需要的算力基础设施数量,我们以GPU/服务器数量进行测算。根据我们的测算框架,大模型对算力的总需求即为预训练、推理和调优的算力需求之和。考虑到模型预训练完成之后,服务器等基础设施通常会被用于下一代模型的开发,因此我们假设预训练、推理、调优的算力需求将并发出现。此外,我们假设训练、推理、调优均在一个月内完成,基于此,测算得1000亿参数模型对A100 GPU的需求为2.8万张,5000亿模型的需求为21.8万张,10000亿模型的需求为63.4万张。我们进一步假设所有服务器均集成8张A100加速卡,则1000、5000、10000亿参数模型对AI服务器需求量分别为0.3、2.7、7.9万台。
成熟大模型的运营有望带来3169亿美元的AI服务器市场空间。据中国科学技术信息研究所发布的《中国人工智能大模型地图研究报告》,截至2023年5月全球累计发布大模型202个,中美两国大模型的数量占全球大模型数量的近 90%。我们预计,目前全球大模型数量仍在持续增加,但随着大模型的迭代,模型厂商之间的竞争或将逐步趋于均衡。基于此,我们保守假设未来或将有30家厂商实现1000亿参数模型的成熟运营,20家厂商实现5000亿参数模型的成熟运营,10家厂商实现10000亿参数模型的成熟运营。据京东,单台浪潮NF5688M6服务器配备8张A800加速卡,售价为159万元/台,按美元兑人民币1:7.23换算约22万美元/台。基于前述不同模型对服务器的需求,我们测算得全球大模型厂商服务器需求规模为3169亿美元。

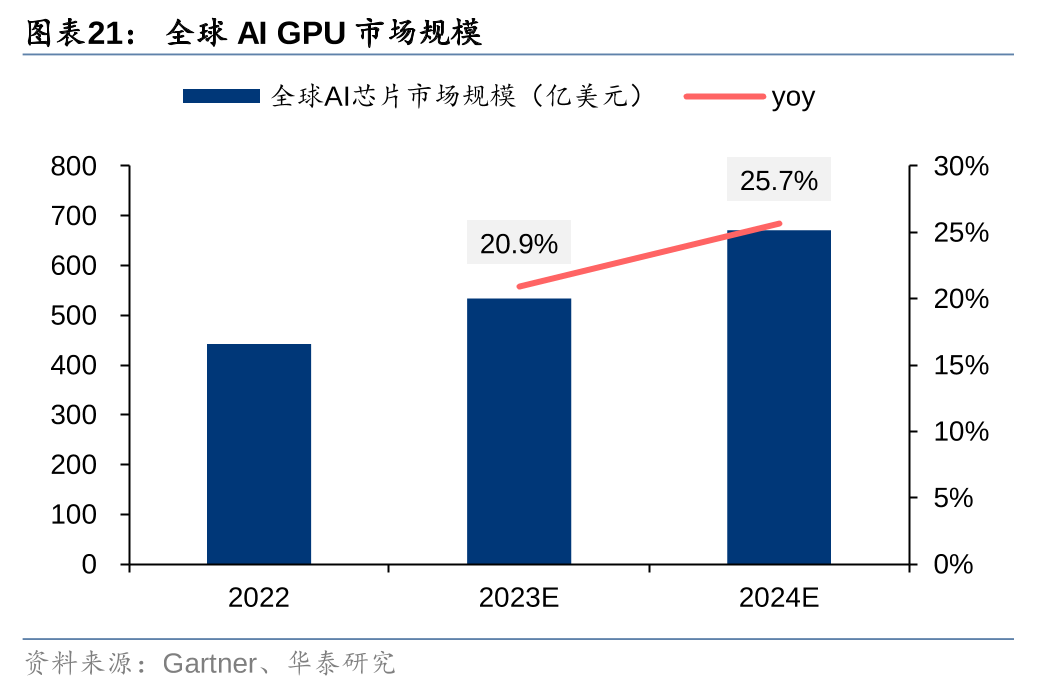
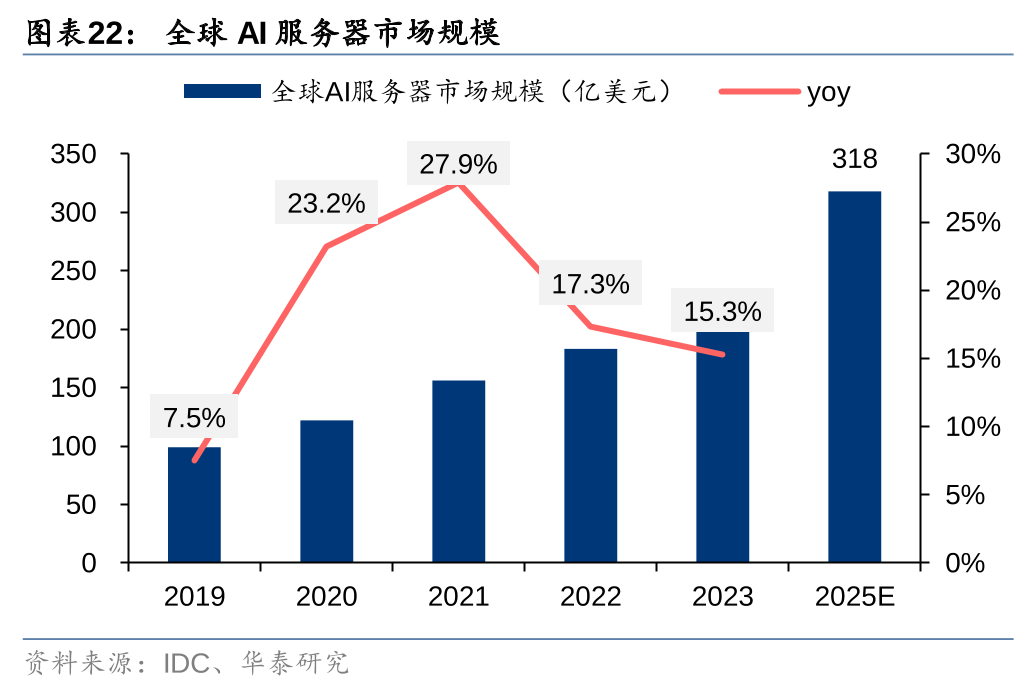
对比之下,目前全球AI服务器市场规模仅为211亿美元,仍有较大成长空间。据Gartner,2023年全球AI芯片市场规模534亿美元,预计2024年同比增速将达25.7%。据IDC,2023年全球AI服务器市场规模211亿美元,预计2025年市场规模将达318亿美元,2024-2025年CAGR将达22.7%。对比来看,全球大模型厂商的持续竞争和成熟运营有望带来3169亿美元的空间,而当下市场规模仅为211亿美元,仍有较大成长空间。我们认为,随着全球大模型百花齐放,AI应用相继问世,训练/推理/调优需求有望带动算力基础设施建设需求快速增长。
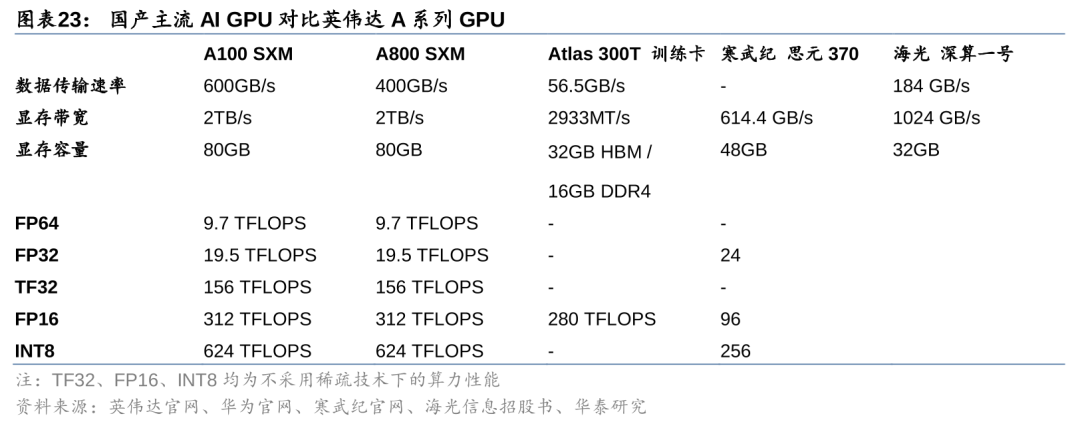
国产化背景下,国产AI GPU有望加速追赶。2023年10月17日,美国商务部工业与安全局(BIS)发布针对中国的先进计算及半导体制造物项出口限制,国内对于高性能AI芯片进口受限。另一方面,我们也看到,目前国产AI GPU较海外先进水平仍有差距。国产AI GPU中,基于华为升腾910设计的Atlas 300T算力性能较强,FP16计算性能在不考虑稀疏技术的情况下约为英伟达A800 SXM的90%。但较英伟达最先进的B100等产品,仍有至少2代以上的产品差距。我们认为,AI芯片进口受限的背景下,AI GPU国产化有望提速,技术迭代之下,海内外差距有望逐步缩小。
产业链公司梳理,请见研报原文。
风险提示
宏观经济波动。若宏观经济波动,产业变革及新技术的落地节奏或将受到影响,宏观经济波动还可能对IT投资产生负面影响,从而导致整体行业增长不及预期。
下游需求不及预期。若下游对算力需求不及预期,相关的算力投入增长或慢于预期,致使行业增长不及预期。
测算结果可能存在偏差。本文中的测算过程中用到“缩放定律”、“Chinchilla 缩放定律”等假设,存在一定主观性,若与实际模型训练过程不符,则可能导致算力需求存在偏差。
相关研报
研报:《全球AI算力需求继续向上》2024年4月12日
谢春生 分析师 S0570519080006 | BQZ938
林海亮 联系人 S0570122060076
关注我们
华泰证券研究所国内站(研究Portal)
https://inst.htsc.com/research
访问权限:国内机构客户
华泰证券研究所海外站
https://intl.inst.htsc.com/research
访问权限:美国及香港金控机构客户
添加权限请联系您的华泰对口客户经理
免责声明
▲向上滑动阅览
本公众号不是华泰证券股份有限公司(以下简称“华泰证券”)研究报告的发布平台,本公众号仅供华泰证券中国内地研究服务客户参考使用。其他任何读者在订阅本公众号前,请自行评估接收相关推送内容的适当性,且若使用本公众号所载内容,务必寻求专业投资顾问的指导及解读。华泰证券不因任何订阅本公众号的行为而将订阅者视为华泰证券的客户。
本公众号转发、摘编华泰证券向其客户已发布研究报告的部分内容及观点,完整的投资意见分析应以报告发布当日的完整研究报告内容为准。订阅者仅使用本公众号内容,可能会因缺乏对完整报告的了解或缺乏相关的解读而产生理解上的歧义。如需了解完整内容,请具体参见华泰证券所发布的完整报告。
本公众号内容基于华泰证券认为可靠的信息编制,但华泰证券对该等信息的准确性、完整性及时效性不作任何保证,也不对证券价格的涨跌或市场走势作确定性判断。本公众号所载的意见、评估及预测仅反映发布当日的观点和判断。在不同时期,华泰证券可能会发出与本公众号所载意见、评估及预测不一致的研究报告。
在任何情况下,本公众号中的信息或所表述的意见均不构成对任何人的投资建议。订阅者不应单独依靠本订阅号中的内容而取代自身独立的判断,应自主做出投资决策并自行承担投资风险。订阅者若使用本资料,有可能会因缺乏解读服务而对内容产生理解上的歧义,进而造成投资损失。对依据或者使用本公众号内容所造成的一切后果,华泰证券及作者均不承担任何法律责任。
本公众号版权仅为华泰证券所有,未经华泰证券书面许可,任何机构或个人不得以翻版、复制、发表、引用或再次分发他人等任何形式侵犯本公众号发布的所有内容的版权。如因侵权行为给华泰证券造成任何直接或间接的损失,华泰证券保留追究一切法律责任的权利。华泰证券具有中国证监会核准的“证券投资咨询”业务资格,经营许可证编号为:91320000704041011J。
精彩评论